Qu'est-ce qu'un graphe de connaissances — et pourquoi cela change la façon dont l'IA navigue dans le droit fiscal belge
Un moteur de recherche trouve du texte. Un graphe de connaissances navigue les relations : quel article modifie lequel, quelle décision interprète quoi, quelle exception l'emporte sur la règle. Le droit fiscal belge est un réseau de renvois — et un graphe de connaissances en est la carte.
Par Auryth Team
Posez une question fiscale belge et vous obtenez rarement un seul article comme réponse. Vous obtenez une chaîne.
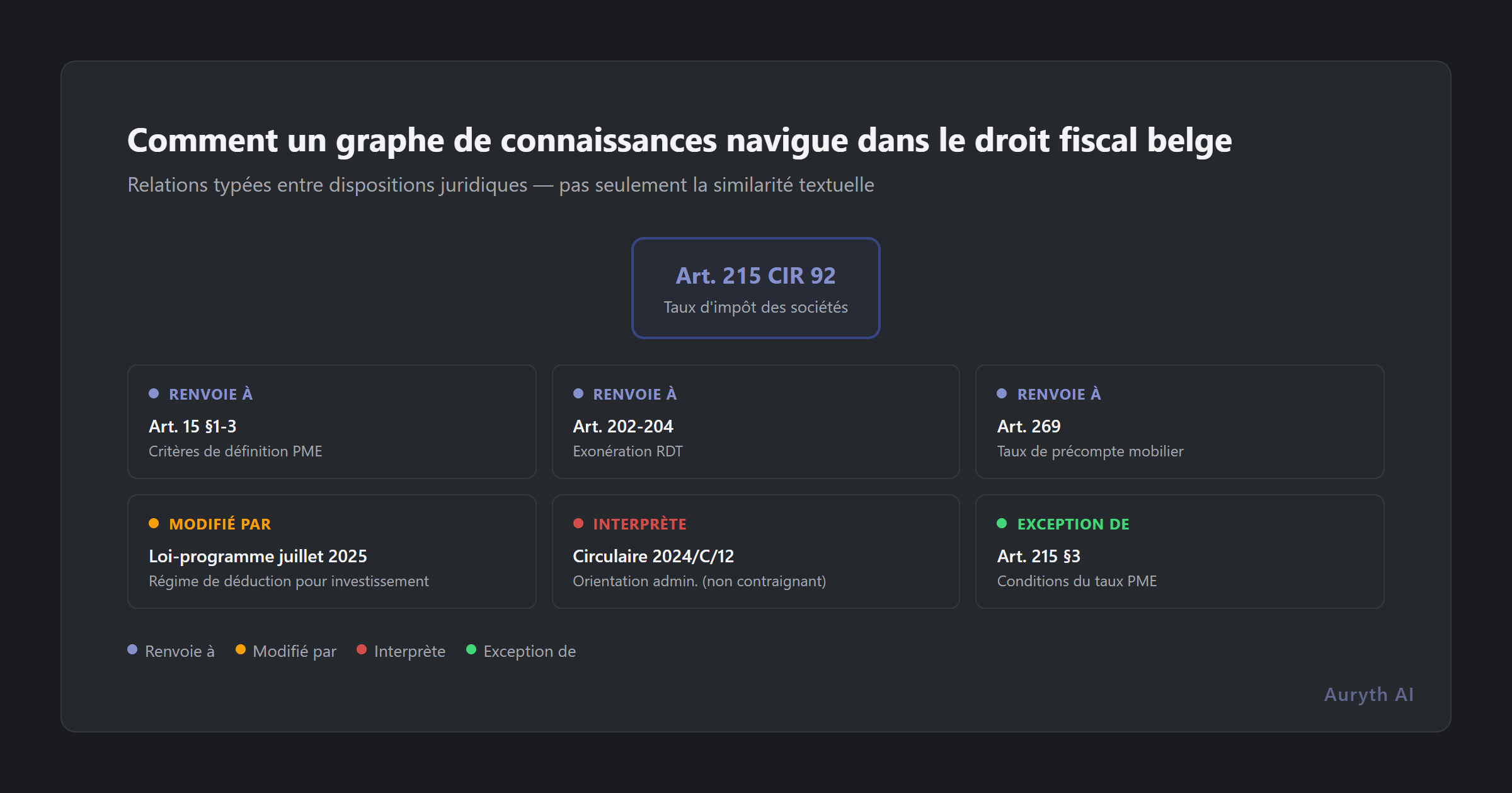
L’article 215 CIR 92 fixe le taux d’impôt des sociétés à 25 % — mais renvoie à l’article 185 pour le principe de pleine concurrence en matière de prix de transfert. L’article 185 a été modifié par la loi-programme de décembre 2023, qui est passée d’une approche transactionnelle à une approche catégorielle. Le taux réduit PME de l’article 215 lui-même exige de remplir des conditions dispersées dans les articles 15 et 215 §2. Les taux de précompte mobilier référencés dans l’article 269 ont été modifiés par la loi-programme de juillet 2025. Et chacune de ces dispositions a été interprétée par des circulaires administratives qui peuvent en restreindre ou élargir la portée.
Ce n’est pas une exception. C’est ainsi que fonctionne le droit fiscal belge. Chaque disposition existe dans un réseau de renvois, modifications, interprétations et exceptions. Un système qui trouve un article mais rate ses connexions vous donne un fragment, pas une réponse.
Un graphe de connaissances est la structure de données qui capture ces connexions — et cela change fondamentalement ce qu’un système d’IA juridique peut faire.
Qu’est-ce qu’un graphe de connaissances
Un graphe de connaissances représente l’information sous forme d’entités connectées par des relations typées. Le concept existe dans la littérature informatique depuis les années 1970, mais est entré dans l’usage grand public en 2012 lorsque Google a lancé son Knowledge Graph pour faire évoluer la recherche du « matching de mots-clés » vers la « compréhension des choses ».
Dans un graphe de connaissances :
- Les entités sont les choses : articles, lois, décisions, concepts, juridictions, périodes temporelles
- Les relations sont les connexions : « modifie », « interprète », « cite », « exception_de », « s’applique_à »
- Les propriétés sont les attributs : date d’entrée en vigueur, juridiction, niveau d’autorité, version linguistique
La différence avec une simple base de données est structurelle. Une base de données relationnelle stocke des enregistrements dans des tables avec des schémas fixes. Un graphe de connaissances stocke directement les relations — et peut les parcourir. Demandez « quelles dispositions affectent la taxation des dividendes d’une filiale ? » et le graphe peut suivre la chaîne : Article 171 (imposition distincte) → cite Article 269 (taux de précompte) → renvoie à l’exonération RDT (Article 202-204) → qui a été modifiée par la loi-programme de juillet 2025 → qui a ajouté une exigence d’immobilisation financière à partir de l’exercice d’imposition 2026.
Aucune recherche par mots-clés ne trouve cette chaîne. Aucun embedding vectoriel ne la capture. Les relations doivent être explicitement modélisées.
Pourquoi le droit fiscal belge est un problème de graphe de connaissances
Le droit fiscal belge a des caractéristiques qui rendent la navigation basée sur les graphes non seulement utile, mais nécessaire.
Les renvois sont la norme, pas l’exception
Un seul article fiscal belge renvoie régulièrement à 5-15 autres dispositions. L’article 215 CIR 92 — un article sur les taux d’impôt des sociétés — renvoie à :
- Articles 15 §1-3 (critères de définition PME)
- Article 185 §2 (principe de pleine concurrence)
- Articles 202-204 (exonération RDT)
- Article 269 (taux de précompte mobilier)
- Article 289ter (crédit d’impôt pour travailleurs à bas revenus)
- Multiples dispositions des lois-programmes qui l’ont modifié
Chaque article référencé a son propre réseau de renvois. Le graphe total accessible depuis l’article 215 s’étend sur des dizaines de dispositions à travers plusieurs codes, niveaux législatifs et périodes temporelles.
Une recherche par mots-clés pour « taux impôt société Belgique » pourrait retourner l’article 215 lui-même. Mais la réponse à une vraie question de conseil — « la filiale de mon client est-elle éligible au taux réduit PME ? » — nécessite de parcourir le graphe à travers les articles 15, 185, 202, et les modifications pertinentes des lois-programmes.
Le problème de la chaîne d’exceptions
La rédaction juridique belge suit un schéma caractéristique :
Règle générale → sauf (sauf) → à moins que (à moins que) → à condition que (à condition que)
Ces exceptions vivent souvent dans des articles différents. La règle générale de l’imposition distincte des dividendes (Article 171) a des exceptions dans l’article 171 §2 (option d’incorporation globale). Mais elle interagit aussi avec l’exonération RDT (Articles 202-204), qui a ses propres conditions, exceptions, et modifications temporelles.
Dans un index de recherche plat, ces exceptions sont des documents séparés. Dans un graphe de connaissances, elles sont connectées par des relations explicites « exception_de » et « modifie » — rendant possible de récupérer la règle complète avec toutes ses qualifications en un seul parcours.
Superposition temporelle
Le droit fiscal belge est modifié au moins deux fois par an par des lois-programmes — législation omnibus qui modifie des dizaines de dispositions simultanément. La loi-programme de décembre 2023 à elle seule a modifié les articles 54, 185/2, 289ter/1, 321quinquies, 321sexies, 321septies, et 344 §2 du CIR.
Un graphe de connaissances modélise cela à travers des nœuds de version temporelle : chaque disposition a un historique de versions, et chaque version enregistre quelle loi-programme l’a créée, quand elle est entrée en vigueur, et ce qu’elle a remplacé. Le système ne stocke pas simplement « l’article 215 dit 25 % ». Il stocke :
- Article 215 (pré-2018) : taux 33,99 %
- Article 215 (2018-2019) : taux 29,58 %, modifié par Loi-programme 25 décembre 2017
- Article 215 (2020-présent) : taux 25 %, modifié par Loi-programme 2 mai 2019
- Article 215 (2026+) : exonération RDT modifiée, modifié par Loi-programme 18 juillet 2025
Chaque version est un nœud distinct, lié à son prédécesseur et successeur, avec la législation modificatrice comme arête de connexion.
Gouvernance multi-niveaux
Les dispositions fiscales belges existent à plusieurs niveaux d’autorité, chacun avec un poids juridique différent :
- Règlements et directives UE — effet direct, priment sur le droit national
- Loi fédérale (CIR, Code TVA) — législation primaire
- Loi régionale (CFF, Code wallon, Code fiscal bruxellois) — égale au fédéral pour les impôts régionalisés
- Arrêtés royaux — règlements d’exécution
- Circulaires ministérielles — interprétation administrative, non contraignante pour les tribunaux
- Décisions anticipées — contraignantes pour l’administration dans le cas spécifique
- Jurisprudence — jurisprudence des tribunaux fiscaux, cours d’appel, Cour de cassation
Un graphe de connaissances capture non seulement le texte à chaque niveau, mais les relations hiérarchiques entre eux. Quand une circulaire interprète l’article 215, le graphe enregistre cette interprétation avec une arête « interprète » — et signale que les circulaires ont une autorité inférieure à l’article lui-même. Quand une décision de justice invalide une circulaire, le graphe se met à jour avec une arête « invalide ».
En quoi cela diffère de la recherche
La plupart des systèmes d’IA, y compris la plupart des outils d’IA juridique, utilisent une forme de recherche : correspondance de mots-clés, similarité sémantique, ou une combinaison. Ces approches trouvent du texte qui semble pertinent. Un graphe de connaissances navigue une structure qui est pertinente.
Recherche par mots-clés trouve des documents contenant les mots de votre requête. Elle ne peut pas parcourir les renvois — si l’article 215 mentionne « Article 185 » par numéro, une recherche par mots-clés pour « prix de transfert » ne suivra pas cette référence.
Recherche vectorielle/sémantique trouve des documents dont le sens est similaire à votre requête. C’est puissant pour les questions en langage naturel mais limité par les frontières des morceaux individuels. La recherche sur les benchmarks de raisonnement multi-saut montre que le RAG traditionnel atteint souvent moins de 70 % de précision quand la réponse nécessite de connecter l’information à travers plusieurs documents.
Parcours de graphe de connaissances suit des relations explicites. Quand on demande « quelles sont les conditions du taux réduit PME ? », il commence à l’article 215, suit l’arête « renvoie » vers l’article 15 (critères PME), suit l’arête « modifié_par » vers la loi-programme pertinente, et retourne la chaîne complète — non pas parce que le texte est similaire, mais parce que la structure juridique les connecte.
Les meilleurs systèmes combinent les deux : recherche vectorielle pour la récupération initiale, graphe de connaissances pour le raisonnement structuré. Les benchmarks académiques montrent que les approches enrichies par graphe peuvent dépasser 85 % de précision sur les tâches multi-saut où les approches vectorielles pures restent typiquement bien en dessous de ce seuil.
Ce que le graphe rend possible
Un graphe de connaissances permet des capacités qui sont structurellement impossibles avec la recherche seule :
Analyse d’impact. Quand une nouvelle loi-programme modifie l’article 215, le système peut tracer toutes les dispositions qui référencent l’article 215 et les signaler pour révision. Ce n’est pas du pattern matching — c’est suivre des arêtes explicites dans le graphe. La modification de juillet 2025 de la loi-programme sur l’exonération RDT affecte chaque disposition qui renvoie aux articles 202-204. Le graphe les identifie toutes.
Complétude des exceptions. Lors de la récupération d’une disposition, le système peut suivre toutes les arêtes « exception_de » pour s’assurer que la chaîne complète règle-plus-exceptions est retournée. La réponse à « comment les dividendes sont-ils taxés ? » n’est jamais juste l’article 171 §1 — elle inclut le §2 (option d’incorporation globale), les articles 202-204 (exonération RDT), et les modifications 2025 aux conditions d’éligibilité.
Précision temporelle. Une requête sur l’impôt des sociétés en 2019 suit le graphe vers le nœud de version 2018-2019 (29,58 %), pas la version actuelle (25 %). Le graphe ne stocke pas seulement le droit actuel — il stocke l’historique complet des versions et peut naviguer vers n’importe quel point dans le temps.
Classement d’autorité. Quand plusieurs sources traitent de la même question, la hiérarchie du graphe permet un classement principiel. Un article du CIR l’emporte sur une circulaire ministérielle. Une décision de la Cour de cassation l’emporte sur une décision de première instance. Ces classements sont encodés dans le graphe comme propriétés de niveau d’autorité sur chaque nœud.
Détection de lacunes. Si une question touche une disposition qui a été récemment modifiée mais que les circulaires d’interprétation n’ont pas encore été mises à jour, le graphe peut signaler cette lacune — l’arête « interprète » de l’ancienne circulaire pointe vers une version remplacée de l’article.
Pourquoi la plupart des outils d’IA juridique n’ont pas cela
Construire un graphe de connaissances pour un corpus juridique est fondamentalement différent d’indexer des documents pour la recherche. La recherche nécessite de diviser le texte en morceaux et de les vectoriser. Un graphe de connaissances nécessite :
- Analyse structurelle — comprendre la structure hiérarchique de chaque code juridique (articles CIR, numérotation hiérarchique du CFF, articles Code TVA et arrêtés royaux)
- Extraction de renvois — identifier chaque renvoi à un autre article, loi, ou décision et créer une arête explicite
- Versionnement temporel — suivre l’historique des modifications et créer des nœuds de version pour chaque changement
- Classification d’autorité — étiqueter chaque source avec son niveau dans la hiérarchie juridique
- Typage de relations — distinguer entre « modifie », « interprète », « cite », « exception_de », et autres types de relations
C’est de l’ingestion structurée, pas du dumping de documents. Cela nécessite une analyse spécifique au domaine pour chaque code juridique et type de document. La numérotation distinctive du CFF (Article 2.10.4.0.1) nécessite une analyse différente de la structure traditionnelle article-et-paragraphe du CIR. Les lois-programmes nécessitent une logique de suivi des modifications qui connecte l’article modificateur à chaque disposition qu’il modifie.
Les outils d’IA généralistes — ChatGPT, Copilot, Gemini — n’ont pas cette structure. Ils traitent le texte juridique comme du texte indifférencié. Ils peuvent trouver des passages qui semblent pertinents, mais ils ne peuvent pas tracer la chaîne de renvois, modifications et exceptions qui connecte une disposition à des dizaines d’autres.
Même la plupart des outils d’IA juridique utilisent la recherche documentaire plutôt que la navigation par graphe. Thomson Reuters et LexisNexis ont investi massivement dans la technologie de graphes de connaissances pour leurs plateformes, mais ce sont des systèmes d’entreprise tarifés pour les grands cabinets internationaux. Le marché belge — corpus plus petit, trois régions, deux langues officielles — n’a traditionnellement pas justifié ce niveau d’investissement structurel.
Que rechercher
Lors de l’évaluation d’un outil d’IA juridique, la présence ou l’absence d’un graphe de connaissances se révèle dans des capacités spécifiques :
-
L’outil peut-il tracer les renvois ? Posez une question qui nécessite de suivre une chaîne : « Quelles conditions mon entreprise doit-elle remplir pour le taux d’impôt des sociétés réduit ? » Si la réponse cite l’article 215 mais pas l’article 15 (définition PME), l’outil cherche, ne navigue pas.
-
L’outil signale-t-il les modifications ? Si vous posez une question sur une disposition qui a été récemment modifiée par une loi-programme, l’outil connaît-il la modification ? S’il retourne du texte obsolète sans signaler le changement, la chaîne de modifications n’est pas modélisée.
-
L’outil peut-il distinguer les niveaux d’autorité ? Posez une question où une circulaire ministérielle contredit une décision de justice. Si l’outil présente les deux comme également autoritaires, il n’a pas de modèle hiérarchique — ce qui signifie pas de graphe.
-
L’outil peut-il vous montrer les connexions ? Un outil construit sur un graphe de connaissances peut vous montrer quelles dispositions se connectent à votre réponse et comment. Un outil construit sur la recherche peut seulement vous montrer le texte qu’il a trouvé.
Le graphe est ce qui transforme une collection de documents juridiques en une carte navigable du droit.
Articles connexes
- Qu’est-ce que le chunking — et pourquoi c’est la fondation invisible de la qualité de l’IA juridique →
- Qu’est-ce que le classement d’autorité — et pourquoi votre outil d’IA juridique l’ignore probablement →
- Qu’est-ce que le versionnement temporel — et pourquoi votre outil d’IA juridique vous sert probablement le droit d’hier →
Comment Auryth TX applique cela
Auryth TX ne recherche pas de documents — il navigue un graphe de connaissances du droit fiscal belge.
Chaque article du CIR, Code TVA, CFF, et codes régionaux est un nœud dans le graphe. Chaque renvoi est une arête. Chaque modification de loi-programme crée un nœud de version temporelle lié aux dispositions qu’elle a modifiées. Chaque circulaire, décision, et décision de justice est connectée aux dispositions qu’elle interprète, avec son niveau d’autorité explicitement modélisé.
Quand vous demandez « comment les dividendes d’une filiale sont-ils taxés ? », le système ne trouve pas juste l’article 171. Il parcourt : Article 171 (imposition distincte) → Articles 202-204 (exonération RDT) → Loi-programme juillet 2025 (exigence d’immobilisation financière) → Article 269 (taux de précompte) — et retourne la chaîne complète avec contexte temporel, classement d’autorité, et complétude des exceptions.
Le radar de domaine dans chaque résultat de recherche est une visualisation directe de ce graphe : il montre quels domaines fiscaux se connectent à votre question, quelles dispositions s’appliquent, et comment elles se rapportent les unes aux autres. Les connexions ne sont pas inférées de la similarité textuelle. Elles sont structurelles — parce qu’elles ont été analysées, extraites et modélisées à partir du droit lui-même.
Pas de recherche. Navigation. Chaque renvoi tracé. Chaque modification liée. Chaque exception connectée.
Sources : 1. Google (2012). “Introducing the Knowledge Graph: things, not strings.” Official Google Blog. 2. Hogan, A. et al. (2021). “Knowledge Graphs.” ACM Computing Surveys, 54(4), Article 71. 3. LexisNexis (2025). “Legal AI Software Company Evaluation Report.” GlobeNewswire. 4. de Martim, H. (2025). “An Ontology-Driven Graph RAG for Legal Norms.” arXiv:2505.00039. 5. Barron, A. et al. (2025). “Bridging Legal Knowledge and AI: RAG with Vector Stores, Knowledge Graphs.” ICAIL 2025. 6. EUR-Lex (2023). “European Legislation Identifier (ELI).” eur-lex.europa.eu.