Wat is chunking — en waarom het de onzichtbare basis is van de kwaliteit van juridische AI
Voordat je juridische AI-tool een vraag kan beantwoorden, moet het de wetgeving in stukken knippen. De manier waarop het knipt bepaalt of het antwoord de uitzondering bevat die alles verandert — of het volledig mist.
Door Auryth Team
Elk gesprek over de kwaliteit van juridische AI komt uiteindelijk op dezelfde plaats aan: retrieval. Vindt het systeem de juiste bronnen? Geeft het de relevante bepalingen terug? Vangt het de uitzondering op die begraven ligt in het derde lid?
Maar voordat retrieval kan plaatsvinden, moet er iets fundamentelers gebeuren. Het systeem moet beslissen hoe het het juridische corpus in stukken knipt — stukken klein genoeg om te doorzoeken, groot genoeg om betekenisvol te blijven. Dit proces heet chunking, en het is de meest onderschatte factor in de kwaliteit van juridische AI.
Doe je het fout, dan zal zelfs het beste retrieval-model ter wereld incomplete antwoorden geven. Doe je het goed, dan kan zelfs een bescheiden systeem verdedigbare resultaten produceren.
Waarom AI überhaupt chunks nodig heeft
Moderne taalmodellen hebben steeds grotere context windows — zowel Claude als GPT-4.1 ondersteunen nu tot een miljoen tokens. Je zou denken dat dit de noodzaak voor chunking volledig elimineert: voer gewoon de volledige wetgeving in en stel je vraag.
Dit werkt niet, om drie redenen.
Attention dilution. Onderzoek toont consistent aan dat LLM’s moeite hebben met informatie die in het midden van zeer lange inputs staat — een fenomeen bekend als het “lost in the middle”-effect. Het model besteedt veel aandacht aan het begin en einde van de tekst, maar verzwakt ertussenin. Voor een juridisch corpus waar de cruciale uitzondering in paragraaf 47 van een input van 200 paragrafen kan staan, is dit geen theoretische kwestie.
Retrieval-precisie. Een Retrieval-Augmented Generation (RAG)-systeem voert niet het volledige corpus in het model in. Het doorzoekt het corpus naar de meest relevante stukken, haalt de top-resultaten op, en voert alleen die in het model in. Dit vereist dat het corpus verdeeld wordt in doorzoekbare eenheden — chunks. De kwaliteit van deze chunks bepaalt de kwaliteit van wat het model ziet.
Kosten en latency. Het verwerken van een miljoen tokens kost €2–15 per vraag, afhankelijk van het model. Voor een fiscaal onderzoekstool die tientallen vragen per dag verwerkt, is het volledige corpus erin stoppen economisch niet haalbaar.
Chunking is geen workaround voor beperkte context windows. Het is een architecturele vereiste voor retrieval-gebaseerde systemen — en elk serieus juridisch AI-systeem is retrieval-gebaseerd.
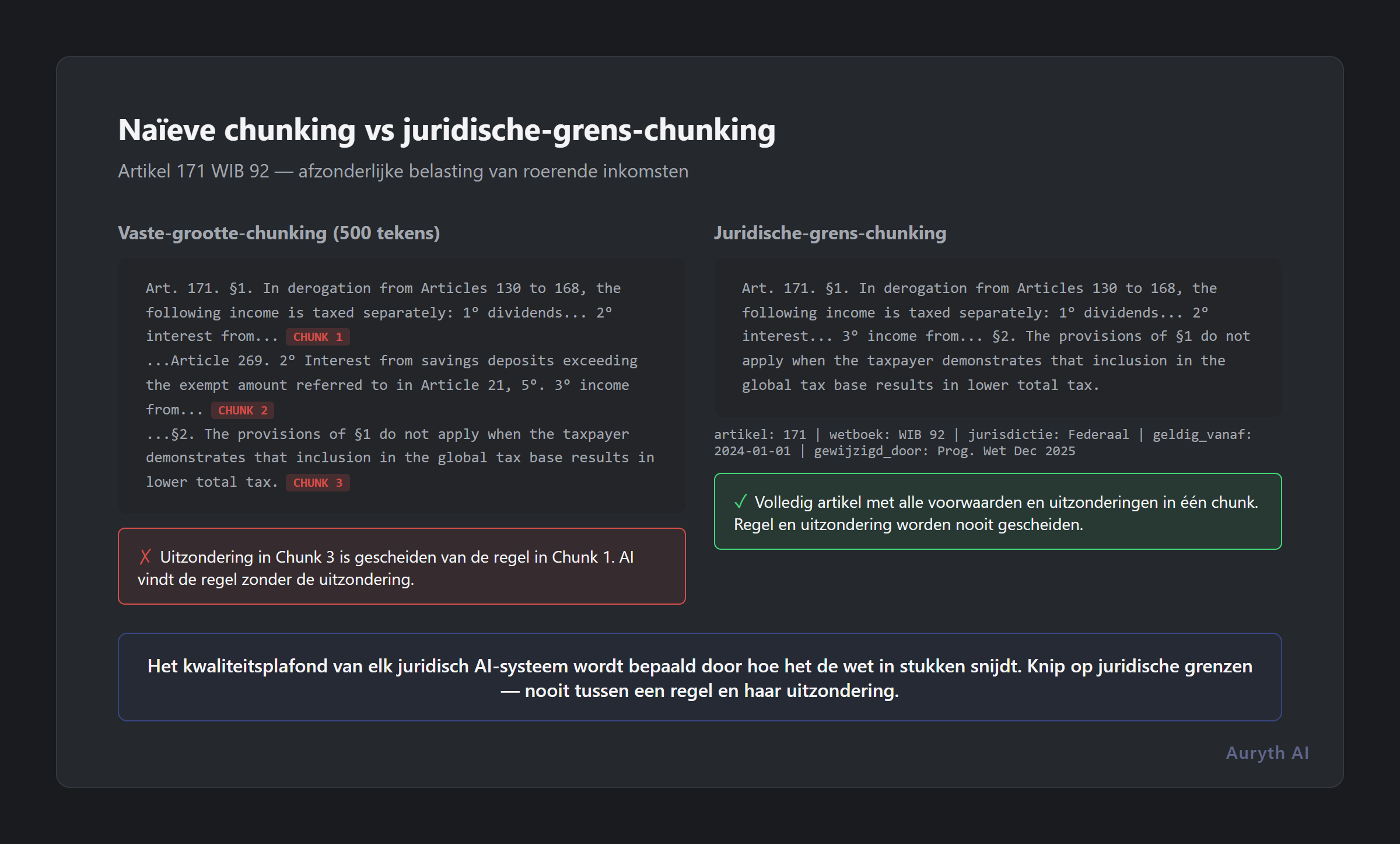
Naïef chunking: de verkeerde manier om te knippen
De simpelste aanpak is fixed-size chunking: splits de tekst elke 500 karakters of 200 tokens, ongeacht de inhoud.
Zo behandelen veel algemene AI-tools documenten. Het werkt goed genoeg voor blogposts, klant-e-mails en producthandleidingen — tekst waar de betekenis van één paragraaf niet cruciaal afhangt van de volgende.
Voor juridische tekst is het catastrofaal.
Neem artikel 171 van het Wetboek Inkomstenbelastingen (WIB 92), dat de afzonderlijke aanslag van roerende inkomsten regelt. Een vereenvoudigde structuur:
Artikel 171. §1. In afwijking van de artikelen 130 tot 168, worden de volgende inkomsten afzonderlijk belast:
1° dividenden [voorwaarden]…
2° interesten [voorwaarden]…
[meerdere genummerde categorieën met specifieke tarieven]
§2. De bepalingen van §1 zijn niet van toepassing wanneer de belastingplichtige aantoont dat opname in de globale belastbare grondslag resulteert in een lagere totale belastingdruk.
Een naïeve chunker die bij 500 karakters splitst zou kunnen produceren:
Chunk 1: “Artikel 171. §1. In afwijking van de artikelen 130 tot 168, worden de volgende inkomsten afzonderlijk belast: 1° dividenden onderworpen aan…” (knipt midden in bepaling)
Chunk 2: “…een roerende voorheffing aan het tarief bepaald in artikel 269. 2° interesten uit…” (gaat verder vanuit het niets)
Chunk 3: ”…§2. De bepalingen van §1 zijn niet van toepassing wanneer de belastingplichtige aantoont dat opname in de globale belastbare grondslag…” (de uitzondering, nu verweesdvaneenzijn context)
Een AI die alleen Chunk 1 ophaalt zal stellen dat dividenden afzonderlijk belast worden — punt uit. Het zal missen dat de belastingplichtige kan kiezen om ze in het globaal inkomen op te nemen als dat tot lagere belasting leidt. Dit is geen nuance. Voor een klant met weinig ander inkomen verandert deze uitzondering de volledige adviesuitkomst.
Het “behoudens”-probleem
Belgische juridische tekst heeft een karakteristieke structuur die naïef chunking bijzonder gevaarlijk maakt. Bepalingen volgen regelmatig een patroon:
Algemene regel → behoudens → tenzij → mits
Elke kwalificatie vernauwt of keert de algemene regel om. De juridische betekenis van elke bepaling hangt af van de volledige keten — regel plus al zijn kwalificaties.
Wanneer een fixed-size chunker deze keten splitst, lijkt de algemene regel absoluut. De AI ziet “dividenden worden afzonderlijk belast aan 30%” zonder “behoudens wanneer de globale belastbare grondslag tot lagere belasting zou leiden” of “tenzij de deelnemingsvrijstelling van toepassing is.”
Dit is geen hallucinatie in de technische zin. De AI reproduceert nauwkeurig wat het kreeg. De fout gebeurde stroomopwaarts, in chunking, waar de volledige bepaling in fragmenten werd gesneden die de juridische betekenis vernietigden.
Legal-boundary chunking: knippen op de naden
Het alternatief is chunken op juridische grenzen — de structurele verdelingen die de wetgever daadwerkelijk bedoelde.
Belgisch fiscaal recht volgt een hiërarchische structuur:
Wetboek (WIB 92, BTW-Wetboek, VCF)
└─ Titel (Titel I: Inkomstenbelastingen)
└─ Hoofdstuk (Hoofdstuk III: Vennootschapsbelasting)
└─ Afdeling (Afdeling II: Belastbare grondslag)
└─ Artikel (Artikel 215)
└─ Paragraaf (§1, §2, §3)
└─ Lid (lid 1, lid 2)
└─ Genummerd item (1°, 2°, 3°)Legal-boundary chunking respecteert deze hiërarchie. De standaardeenheid is het artikel — de fundamentele bouwsteen van gecodificeerd recht. Elk artikel behandelt een onderscheiden juridisch concept en is ontworpen om op zichzelf te staan (hoewel het naar andere artikelen kan verwijzen).
Korte artikelen zoals artikel 1 WIB 92 (“Er wordt een belasting op het totale inkomen geheven…”) passen gemakkelijk in één chunk met ruimte over.
Middelgrote artikelen zoals artikel 215 WIB 92 (vennootschapsbelastingtarieven, KMO-verlaagd tarief, kwalificerende voorwaarden) vullen één chunk met alle voorwaarden intact.
Lange artikelen met tientallen paragrafen en genummerde items kunnen praktische chunk-limieten overschrijden. Hiervoor splitst het systeem op paragraaf (§) grenzen, waarbij volledige semantische eenheden behouden blijven. Als paragrafen nog steeds te lang zijn, splitst het op lid-grenzen — maar nooit midden in een zin, nooit midden in een clausule, nooit tussen een regel en zijn uitzondering.
Het Vlaams Belastingwetboek (VCF) voegt een extra laag structurele precisie toe met zijn onderscheidende hiërarchische nummering: artikel 2.10.4.0.1 codeert Titel 2, Hoofdstuk 10, Afdeling 4 direct in het artikelnummer. Deze ingebouwde structuurkaart maakt legal-boundary chunking bijzonder schoon.
Wat elke chunk met zich meedraagt
Een tekstfragment zonder metadata is een fragment zonder context. In juridische AI is context alles.
Elke chunk in een goed ontworpen systeem draagt identificatiemetadata:
- Artikelnummer en wetboekreferentie — “Artikel 215 WIB 92” of “Artikel 2.7.1.0.3 VCF”
- Jurisdictie — Federaal, of regionaal (Vlaanderen, Wallonië, Brussel)
- Ingangsdatums — Wanneer deze versie van de bepaling in werking trad en, indien van toepassing, wanneer het werd vervangen
- Wijzigingsgeschiedenis — Welke programmawet deze bepaling het laatst wijzigde, en wat er veranderde
- Kruisverwijzingen — Welke andere artikelen deze bepaling aanhaalt, en welke artikelen ernaar verwijzen
- Autoriteitsniveau — Primaire wetgeving, koninklijk besluit, circulaire, of administratieve ruling
Deze metadata transformeert retrieval van “zoek tekst die lijkt op de vraag” naar “zoek de huidige, gezaghebbende bepaling uit de correcte jurisdictie die van toepassing is op de specifieke periode van de klant.”
Zonder dit zou het systeem een versie van artikel 215 uit 2019 kunnen ophalen met een vennootschapsbelastingtarief van 29,58% — technisch nauwkeurige tekst, maar fout voor elke vraag over het huidige regime.
Hoe chunk-kwaliteit door het systeem cascadeert
De retrieval-pipeline werkt als een keten:
Chunking → Embedding → Retrieval → Reranking → Antwoordgeneratie
Elke fase hangt af van de output van de vorige. Slechte chunking verspreidt fouten door elke volgende fase.
Embedding converteert elke chunk naar een mathematische vector. Als de chunk een zinsfragment is dat eindigt midden in een clausule, legt de embedding een incomplete gedachte vast — en zal matchen tegen de verkeerde vragen.
Retrieval zoekt naar chunks waarvan de embeddings het meest lijken op de vraag. Als de cruciale uitzondering los van de regel werd gechunked, kan de retrieval de regel zonder de uitzondering teruggeven — of de uitzondering zonder de regel.
Reranking herevalueert de top-resultaten met een geavanceerder model. Het kan sommige chunking-fouten opvangen door te herkennen dat een resultaat incompleet is. Maar het kan geen informatie reconstrueren die over chunks werd verspreid die het nooit ziet.
Antwoordgeneratie synthetiseert de opgehaalde chunks in een respons. Als het vijf goed gechunkde, complete bepalingen met metadata ontvangt, kan het een verdedigbaar antwoord met correcte citaties produceren. Als het vijf tekstfragmenten zonder artikelnummers en zonder ingangsdatums ontvangt, zal zelfs het meest capabele model een antwoord produceren dat er zelfverzekerd uitziet maar niet geverifieerd kan worden.
Dit is het fundamentele inzicht: het kwaliteitsplafond van elk RAG-gebaseerd juridisch AI-systeem wordt bepaald door zijn chunking-strategie. Geen enkele hoeveelheid modelsofisticatie stroomafwaarts kan compenseren voor structurele vernietiging stroomopwaarts.
Wat dit betekent voor praktijkbeoefenaars
Bij het evalueren van een juridische AI-tool is de chunking-strategie geen technisch detail om over te slaan. Het is de architecturale beslissing die bepaalt of de tool betrouwbaar volledige juridische bepalingen kan teruggeven met hun uitzonderingen, voorwaarden en temporele context.
Drie vragen die de moeite waard zijn om te stellen:
-
Behoudt de tool volledige artikelen met alle voorwaarden en uitzonderingen? Als het antwoord gaat over hoe de tool bepalingen “samenvat” of “sleutelpunten extraheert,” kan de chunking de juridische structuur vernietigen in plaats van behouden.
-
Draagt elk resultaat metadata — artikelnummer, jurisdictie, ingangsdatum? Als resultaten tekst zonder duidelijke herkomst tonen, chunked het systeem waarschijnlijk zonder metadata. Dit maakt verificatie en citatie onmogelijk.
-
Kan de tool onderscheid maken tussen huidige en historische bepalingen? Als het systeem verouderde versies teruggeeft zonder ze te markeren, ontbreekt de temporele metadata — een chunking- en indexeringsfalen.
De ironie van chunking is dat wanneer het goed werkt, het onzichtbaar is. De gebruiker ziet gewoon correcte, volledige, goed geciteerde antwoorden. De architectuur die die antwoorden mogelijk maakte — het zorgvuldige knippen, het behoud van metadata, de grensdetectie — werkt volledig achter de schermen.
Wanneer het slecht werkt, zijn de fouten ook onzichtbaar — tot een klant vertrouwt op advies dat de uitzondering in het derde lid miste.
Gerelateerde artikelen
- Wat is RAG — en waarom het de enige architectuur is die juridische AI verdedigbaar maakt →
- Wat is authority ranking — en waarom je juridische AI-tool het waarschijnlijk negeert →
- Wat is confidence scoring — en waarom het eerlijker is dan een zelfverzekerd antwoord →
Hoe Auryth TX dit toepast
Auryth TX chunked op juridische grenzen — artikelen, paragrafen en leden — nooit op willekeurige karakter- of token-limieten. Het WIB 92, BTW-Wetboek, VCF en regionale wetboeken worden elk geparsed volgens hun specifieke structurele conventies. De hiërarchische nummering van het VCF, de paragraaf-en-lid-structuur van het WIB, de artikel-en-koninklijk-besluit-organisatie van het BTW-Wetboek — elk vereist een andere parsing-aanpak, en elk krijgt er een.
Elke chunk draagt zijn volledige herkomst: artikelnummer, wetboekreferentie, jurisdictie, ingangsdatumbereik, wijzigingsketen, en kruisverwijzingen naar gerelateerde bepalingen. Wanneer het systeem artikel 215 WIB 92 ophaalt, haalt het de huidige versie op — met metadata die aangeeft wanneer het voor het laatst werd gewijzigd door de programmawet van juli 2025 en wat er veranderde.
Het resultaat: wanneer het systeem zegt “dividenden worden afzonderlijk belast onder artikel 171 WIB 92,” staat de volledige bepaling achter dat antwoord — inclusief de uitzondering van §2 voor belastingplichtigen die baat hebben bij globale opname. De uitzondering staat niet in een andere chunk. Het staat daar, omdat het systeem de regel nooit scheidde van zijn kwalificaties.
Chunking op juridische grenzen. Elke bepaling compleet. Elke uitzondering behouden.
Bronnen: 1. Liu, N.F. et al. (2024). “Lost in the Middle: How Language Models Use Long Contexts.” Transactions of the ACL, 12, 157-173. 2. ResearchGate (2024). “Legal Chunking: Evaluating Methods for Effective Legal Text Retrieval.” 3. Milvus (2025). “Best practices for chunking lengthy legal documents for vectorization.” 4. Weaviate (2024). “Chunking Strategies for RAG.” 5. Elvex (2026). “Context Length Comparison: Leading AI Models in 2026.”