5 questions fiscales belges où l'IA générique échoue à coup sûr
Ce ne sont pas des questions pièges. Ce sont des requêtes de routine que tout fiscaliste rencontre. Mais elles exposent cinq angles morts architecturaux qu'aucune IA générique ne peut corriger avec un meilleur prompt.
Par Auryth Team
Nous avons testé ChatGPT, Copilot et Gemini sur cinq questions fiscales belges que n’importe quel professionnel pourrait poser lors d’une journée de travail ordinaire. Pas de cas limites. Pas de questions pièges. Le type de requêtes que vous lanceriez en examinant un dossier client.
Les cinq ont produit des réponses confiantes et bien structurées. Les cinq étaient fausses — ou dangereusement incomplètes. Et les échecs n’étaient pas aléatoires. Chacun expose une limitation architecturale différente qu’aucune ingénierie de prompt ne peut corriger.
Si vous utilisez une IA générique pour la recherche fiscale, ce sont les questions que vous devez comprendre. Non pas parce qu’elles sont les seuls échecs — mais parce qu’elles représentent les cinq catégories structurelles d’échec qui se répètent à travers chaque requête.
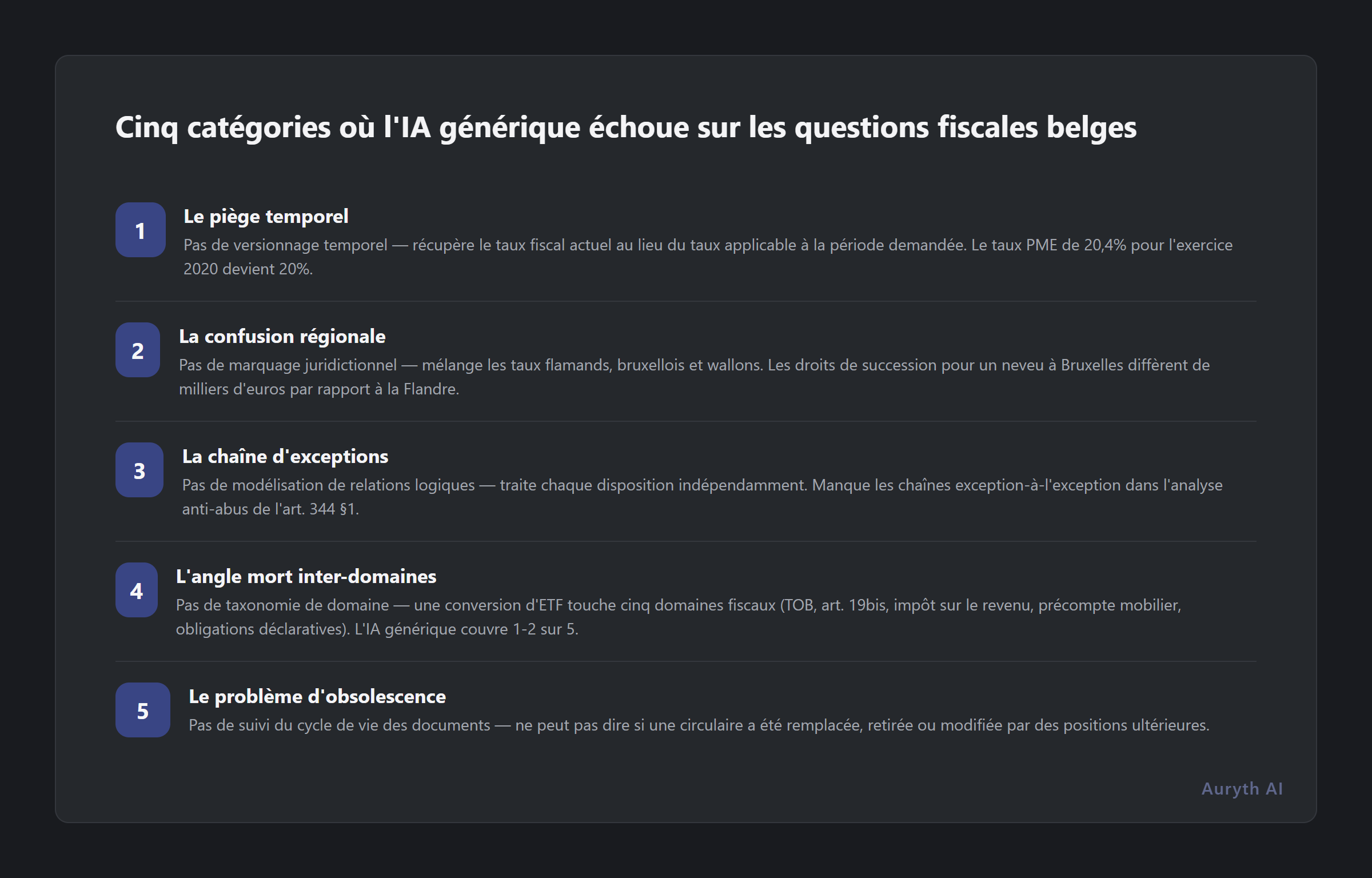
1. Le piège temporel
La question : “Quel était le taux d’impôt des sociétés belge pour les PME avec un revenu imposable jusqu’à 100 000 € pour l’exercice d’imposition 2020 ?”
Ce que l’IA générique dit : “Le taux PME est de 20 % sur les premiers 100 000 € de revenu imposable en vertu de l’Art. 215, paragraphe 2 CIR 92.” Confiant. Clair. Faux pour la période demandée.
Ce qui s’est réellement passé : Le taux réduit PME était de 20,4 % pour l’exercice d’imposition 2020 (année de revenus 2019), dans le cadre des taux transitoires durant la réforme de l’impôt des sociétés. Le taux de 20 % s’applique uniquement à partir de l’exercice d’imposition 2021. L’IA récupère le taux actuel et le projette en arrière — parce qu’elle n’a aucun concept de versionnage temporel.
Pourquoi cela échoue architecturalement : Les modèles d’IA génériques ont un seul instantané de connaissance. Ils ne maintiennent pas de versions temporelles des dispositions légales. Lorsque vous posez une question sur une période historique, le modèle n’a aucun mécanisme pour récupérer la loi telle qu’elle était à ce moment-là. Il vous donne ce dont il “se souvient” — qui est généralement la version la plus récente sur laquelle il a été entraîné.
Ce que cela vous coûte : Un taux incorrect dans une déclaration fiscale déclenche une correction administrative au mieux, une pénalité au pire. Pour un professionnel, c’est aussi un risque réputationnel — le type d’erreur qui fait douter les clients de votre attention aux détails.
2. La confusion régionale
La question : “Quel est le taux de droits de succession à Bruxelles pour un héritage de 300 000 € reçu par un neveu ?”
Ce que l’IA générique dit : Elle produit généralement un tableau de taux — mais mélange les taux flamands et bruxellois, ou ne donne que les taux d’une région sans préciser laquelle. Plusieurs modèles que nous avons testés ont donné le barème de taux flamand (qui utilise des tranches et des seuils différents) tout en prétendant répondre sur Bruxelles.
Ce qui s’est réellement passé : Bruxelles applique son propre barème de taux pour la catégorie “entre frères et sœurs” et “entre oncles/tantes et neveux/nièces”, avec des tranches différentes de la Flandre ou de la Wallonie. Le taux pour un neveu sur 300 000 € à Bruxelles diffère de celui de la Flandre de plusieurs milliers d’euros.
Pourquoi cela échoue architecturalement : La Belgique a trois régions fiscales avec des régimes de droits de succession divergents. L’IA générique traite la Belgique comme une seule juridiction — ou pire, picore des dispositions de n’importe quelle source que sa recherche vectorielle trouve en premier. Elle n’a pas de marquage juridictionnel sur ses données d’entraînement et aucun mécanisme pour distinguer les règles flamandes, bruxelloises et wallonnes lorsqu’elles utilisent une terminologie similaire.
Ce que cela vous coûte : Conseiller un client bruxellois sur la base de taux flamands n’est pas seulement inexact — c’est conseiller sous le mauvais cadre juridique entièrement. Le client se fie à votre chiffre. S’il est faux, la responsabilité est la vôtre.
3. La chaîne d’exceptions
La question : “Existe-t-il une exception à la disposition générale anti-abus de l’Art. 344 §1 CIR 92 pour les opérations qui ont été spécifiquement approuvées par décision anticipée ?”
Ce que l’IA générique dit : La plupart des modèles reconnaissent l’Art. 344 et décrivent la règle générale anti-abus, mais manquent la nuance critique : la relation entre l’Art. 344 §1 (anti-abus général), les dispositions anti-abus spécifiques (comme l’Art. 344 §2), et le rôle des décisions anticipées (SDA) dans la fourniture de sécurité juridique sur des opérations spécifiques.
Ce qui s’est réellement passé : L’interaction entre l’Art. 344 §1 CIR 92, les dispositions anti-abus spécifiques et le Service des Décisions Anticipées (SDA) implique une chaîne d’exception à l’exception. Une décision anticipée du SDA sur une opération spécifique ne l’immunise pas automatiquement contre l’Art. 344 §1 — mais l’analyse dépend de savoir si la décision a spécifiquement abordé la question anti-abus et des faits matériels présentés.
Pourquoi cela échoue architecturalement : Le raisonnement juridique implique souvent des chaînes d’exceptions, où la disposition A a l’exception B, qui elle-même a l’exception C. L’IA générique traite chaque disposition comme un bloc de texte indépendant. Elle ne modélise pas les relations logiques entre elles — les chaînes “sauf lorsque” et “nonobstant” et “sans préjudice de” qui définissent comment les dispositions interagissent réellement.
Ce que cela vous coûte : L’analyse anti-abus fait partie du travail fiscal le plus à enjeux. Une analyse incomplète qui manque une exception — ou une exception à une exception — peut faire la différence entre une structure qui survit à un audit et une qui ne survit pas.
4. L’angle mort inter-domaines
La question : “Quelles sont toutes les implications fiscales pour un résident belge convertissant un ETF distribuant en ETF capitalisé ?”
Ce que l’IA générique dit : Elle couvre généralement les implications TOB (taxe sur les opérations de bourse) — parfois correctement — mais manque la plupart des autres domaines. Les réponses que nous avons reçues couvraient 1 à 2 des 5 domaines fiscaux pertinents.
Ce qui s’est réellement passé : Cette opération touche au moins cinq domaines fiscaux distincts :
- TOB — taxe de transaction sur la vente du fonds distribuant et l’achat du fonds capitalisé
- Art. 19bis CIR 92 — taxation de la “composante d’intérêt” à la sortie d’un fonds de dette si >10 % en instruments de dette
- Impôt sur le revenu — traitement de toute plus-value réalisée (ordinaire vs. spéculation vs. professionnelle)
- Précompte mobilier — traitement de tout dividende accumulé au moment de la conversion
- Obligations déclaratives — déclaration de compte étranger si le fonds capitalisé est détenu à l’étranger
Pourquoi cela échoue architecturalement : L’IA générique traite votre question comme une seule requête contre un index de texte plat. Elle n’a aucun concept de frontières de domaines fiscaux. Elle ne peut pas traverser systématiquement du TOB à l’impôt sur le revenu au précompte mobilier aux obligations déclaratives — parce que son mécanisme de récupération ne sait pas que ces domaines existent comme des zones séparées et interreliées. Les systèmes spécialisés avec taxonomie de domaine peuvent déclencher une récupération multi-domaines et signaler quels domaines ont été couverts et lesquels ne l’ont pas été.
Ce que cela vous coûte : Conseiller un client sur une conversion de fonds tout en manquant trois des cinq implications fiscales n’est pas un conseil partiel — c’est un conseil qui crée un faux sentiment d’exhaustivité. Le client suppose que vous avez tout couvert. Vous supposez que l’IA a tout couvert. Personne n’a vérifié.
5. Le problème d’obsolescence
La question : “La circulaire Fisconetplus du 15 mars 2023 sur le traitement fiscal des récompenses de staking de cryptomonnaies est-elle toujours en vigueur ?”
Ce que l’IA générique dit : Les modèles entraînés avant une certaine date confirmeront soit que la circulaire existe, soit en fabriqueront une. Aucun ne peut vous dire si elle a été remplacée, retirée ou modifiée par des positions administratives ultérieures.
Ce qui s’est réellement passé : Les circulaires et orientations administratives évoluent. Elles sont remplacées par de nouvelles circulaires, modifiées par des décisions judiciaires, ou rendues partiellement obsolètes par des changements législatifs. Une circulaire de 2023 peut ou non refléter la position administrative actuelle en 2026 — et la seule façon de le savoir est de vérifier si des positions ultérieures ont été émises.
Pourquoi cela échoue architecturalement : L’IA générique n’a aucun concept de cycle de vie des documents. Elle ne suit pas quelles circulaires ont été remplacées, quelles décisions ont été annulées, ou quelles dispositions ont été amendées. Sa connaissance est un instantané — et elle ne peut pas vous dire où cet instantané est obsolète. Les systèmes spécialisés avec métadonnées temporelles et suivi de remplacement peuvent signaler quand une source peut ne plus refléter la loi actuelle.
Ce que cela vous coûte : Conseiller sur la base d’une circulaire remplacée, c’est conseiller sur la base d’une loi qui n’existe plus. Les implications en matière de responsabilité professionnelle sont claires.
Le schéma
Ces cinq échecs ne sont pas des bugs qui seront corrigés dans GPT-6 ou la prochaine version du modèle. Ce sont des conséquences structurelles de la façon dont l’IA générique traite le texte :
- Pas de versionnage temporel → mauvaises réponses historiques
- Pas de marquage juridictionnel → confusion régionale
- Pas de modélisation de relations logiques → chaînes d’exceptions brisées
- Pas de taxonomie de domaine → couverture inter-domaines incomplète
- Pas de suivi du cycle de vie des documents → dépendance à des sources obsolètes
Chaque échec correspond à une capacité architecturale que les modèles généralistes n’ont pas — et ne peuvent pas développer par un meilleur entraînement seul. Ceux-ci nécessitent une infrastructure de recherche spécialisée, des corpus juridiques structurés et des pipelines de récupération spécifiques au domaine.
La question n’est pas de savoir si l’IA générique “s’améliore”. Elle s’améliore. La question est de savoir si l’architecture peut supporter un travail fiscal de niveau professionnel. Ces cinq tests disent non.
Articles connexes
- J’ai posé les mêmes questions fiscales belges à ChatGPT et Auryth — voici ce qui s’est passé
- Hallucinations IA : pourquoi ChatGPT fabrique des sources (et comment les repérer)
- Qu’est-ce que le RAG — et pourquoi ce n’est pas suffisant pour l’IA juridique seul
Comment Auryth TX traite ces cinq questions
Ces cinq catégories d’échec sont exactement ce pour quoi l’architecture de fusion recherche-RAG d’Auryth TX a été construite pour répondre :
-
Temporel — Chaque disposition dans notre corpus porte des métadonnées temporelles. Lorsque vous posez une question sur l’exercice d’imposition 2020, le système récupère la version de la loi qui s’appliquait à cette période — pas la version d’aujourd’hui.
-
Régional — Marqueurs de juridiction sur chaque document. Une question sur les droits de succession à Bruxelles récupère les taux bruxellois du code fiscal bruxellois. Les dispositions flamandes sont exclues sauf si vous demandez explicitement une comparaison.
-
Chaînes d’exceptions — Cartographie des références croisées entre dispositions. Lorsque l’Art. 344 §1 est récupéré, le système récupère également les dispositions qui le modifient, le limitent ou l’étendent — et présente la structure relationnelle.
-
Inter-domaines — La taxonomie de domaine déclenche une récupération multi-domaines. Une question de conversion d’ETF traverse systématiquement TOB, impôt sur le revenu, précompte mobilier, Art. 19bis et obligations déclaratives — et signale quels domaines ont été couverts.
-
Obsolescence — Suivi de remplacement et validation temporelle. Lorsque vous posez une question sur une circulaire de 2023, le système vérifie si des positions administratives ultérieures ont été émises.
Ce ne sont pas des fonctionnalités que nous avons ajoutées au-dessus d’un chatbot. Ce sont les fondations architecturales du système.
Testez ces cinq questions vous-même — rejoignez la liste d’attente →
Sources : 1. Code des impôts sur les revenus belge (CIR 92), Art. 215, Art. 344, Art. 19bis. 2. Code des droits de succession de la Région de Bruxelles-Capitale, Art. 48-54. 3. Magesh, V. et al. (2025). « Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools. » Journal of Empirical Legal Studies.