Dans les coulisses : comment une modification législative traverse un système d'IA juridique
Quand la loi-programme belge modifie 47 dispositions en une nuit, que se passe-t-il dans l'outil d'IA sur lequel vous comptez ? Un regard transparent sur le pipeline d'ingestion.
Par Auryth Team
La loi-programme a été votée un jeudi. Elle a modifié 47 dispositions réparties sur six codes — impôt sur le revenu, TVA, sécurité sociale, droit des sociétés, incitants régionaux et droits de succession. Vendredi matin, l’ancienne loi appartenait au passé. Lundi, les professionnels devaient conseiller leurs clients sur les nouvelles règles.
À quelle vitesse votre outil d’IA le sait-il ?
La plupart des fournisseurs d’IA juridique promettent un « contenu toujours à jour ». Aucun d’entre eux n’explique ce que cela signifie en pratique. Ils ne vous disent pas combien de temps dure l’écart entre la publication d’une loi et sa consultabilité. Ils n’expliquent pas ce qui se passe pendant cet écart. Ils ne montrent pas qui vérifie que le texte ingéré correspond effectivement à ce qui a été publié.
Ce silence devrait préoccuper quiconque s’appuie sur ces outils pour du conseil professionnel.
Ce que « toujours à jour » exige réellement
Le Moniteur belge publie quotidiennement de nouvelles législations en néerlandais et en français. En 2024, il a publié un record de 141 310 pages — environ 390 pages par jour. Les lois-programmes arrivent deux fois par an, chacune modifiant des dizaines de dispositions dans des domaines sans rapport entre eux au sein d’un seul acte législatif.
Ce volume rend la surveillance manuelle impossible. Mais il rend aussi la surveillance automatisée véritablement difficile. Le texte juridique n’est pas du contenu web. Il possède des hiérarchies imbriquées — sections, sous-sections, articles, paragraphes, points — que le traitement de texte standard ignore. Les amendements utilisent un langage spécialisé : « L’article 145/1 du CIR 92 est remplacé par ce qui suit… » Le système doit comprendre non seulement le nouveau texte, mais aussi quelle disposition existante il remplace, quand la modification entre en vigueur, et quelles références croisées sont affectées.
Les systèmes RAG standard n’atteignent que 58 % de précision sur les questions sensibles aux versions car ils récupèrent du contenu sémantiquement similaire sans vérifier la validité temporelle. Les systèmes conscients des versions peuvent atteindre 90 % — mais cela nécessite une architecture dédiée, pas simplement une « mise à jour de la base de données » (Huwiler et al., 2025).
Le pipeline en sept étapes
Voici ce qui doit se passer entre la publication d’une loi et le moment où un professionnel peut la rechercher :
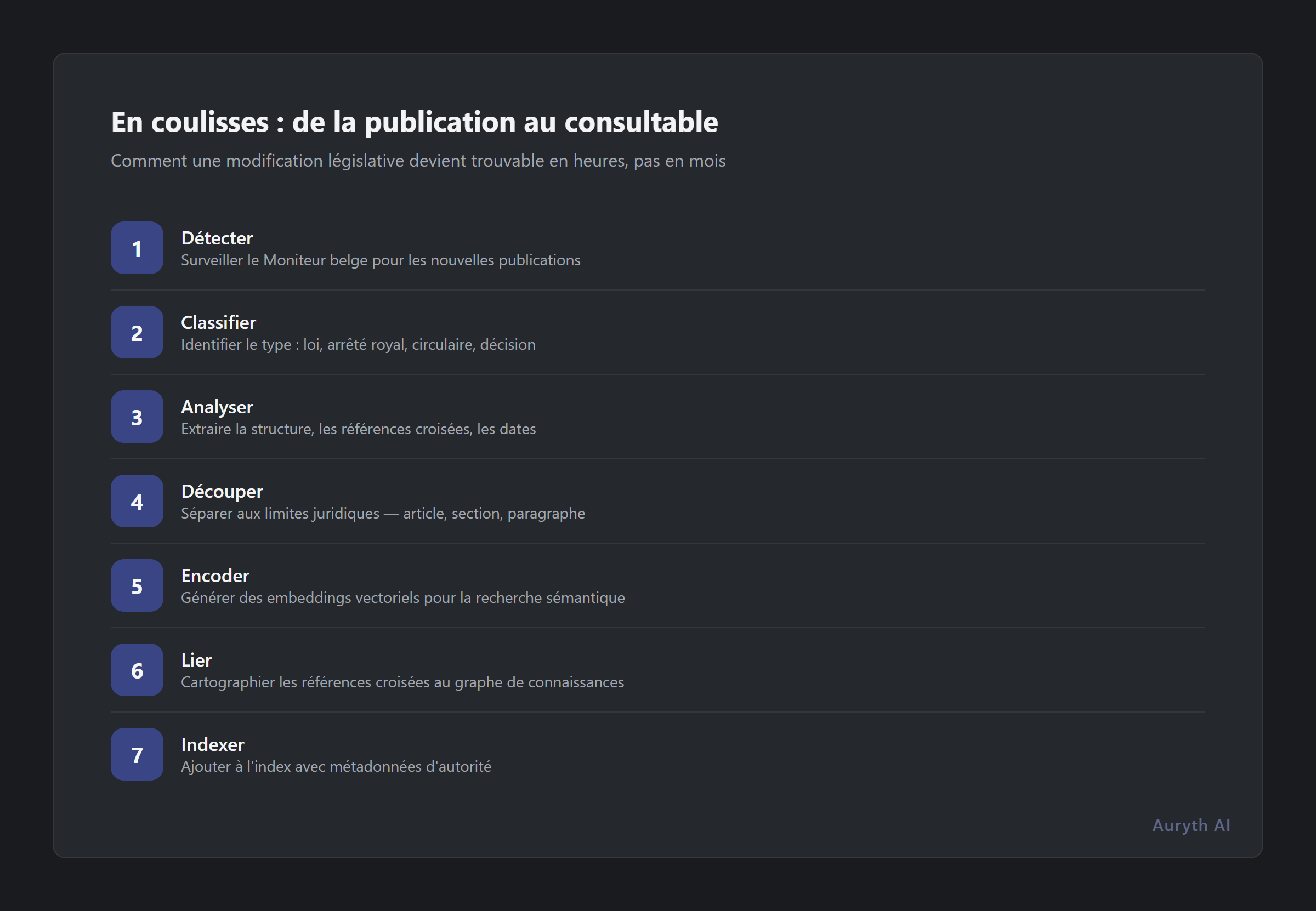
Étape 1 : Détection. Un agent de surveillance observe le Moniteur belge pour détecter les nouvelles publications. Ce processus tourne en continu — pas hebdomadairement, pas quotidiennement. Les nouvelles publications sont détectées dans les heures suivant leur parution au journal officiel.
Étape 2 : Classification. Tout ce qui est publié ne nécessite pas le même traitement. Une nouvelle loi fédérale, un arrêté royal, une circulaire administrative et une décision judiciaire ont chacun des niveaux d’autorité, des portées et des exigences de traitement différents. Le système classe chaque document par type avant traitement.
Étape 3 : Extraction du texte. La publication brute est analysée en texte structuré. Cela semble simple jusqu’à ce que vous rencontriez un formatage bilingue, des structures d’articles imbriquées, des tableaux de taux et un langage modificatif qui référence des dispositions dans d’autres codes. Les versions néerlandaise et française sont toutes deux authentiques — la cohérence interlinguistique doit être préservée.
Étape 4 : Résolution des amendements. C’est l’étape la plus difficile et celle que la plupart des fournisseurs sautent ou simplifient. Quand une loi-programme dit « L’article 215 du CIR 92 est modifié comme suit », le système doit identifier la disposition existante, appliquer l’amendement et créer une nouvelle version tout en préservant l’ancienne avec ses dates de validité. Une seule loi-programme peut déclencher des dizaines de ces opérations à travers plusieurs codes.
Étape 5 : Découpage et vectorisation. Le texte traité est divisé en unités sémantiquement significatives — pas des paragraphes arbitraires, mais des segments conscients de la structure des articles qui préservent l’organisation juridique. Chaque segment est converti en embeddings vectoriels pour la recherche sémantique, tandis que le texte intégral est indexé pour la recherche par mots-clés. Des métadonnées sont attachées : date d’entrée en vigueur, niveau d’autorité, juridiction et références croisées.
Étape 6 : Vérification. Avant que le nouveau contenu n’entre dans le corpus en production, il passe des contrôles qualité. Le texte analysé correspond-il à la source publiée ? Les numéros d’articles sont-ils correctement extraits ? Les références croisées pointent-elles vers des dispositions existantes ? Les dates d’entrée en vigueur sont-elles exactes ? Cette étape détecte les erreurs d’analyse avant qu’elles ne deviennent de mauvais conseils.
Étape 7 : Propagation d’impact. Le graphe de connaissances identifie quelles dispositions, décisions et commentaires existants sont affectés par la modification. Les recherches sauvegardées citant ces dispositions sont signalées comme potentiellement obsolètes. C’est là que le système ajoute de la valeur au-delà du simple fait de « contenir la nouvelle loi » — il vous dit quoi d’autre a changé parce que la loi a changé.
Là où ça se complique : les défis dont personne ne parle
Le langage modificatif est ambigu. « Le premier alinéa de l’article 344 est complété par une phrase… » — quelle phrase ? Où exactement ? La rédaction juridique n’est pas toujours précise sur les points d’insertion, et l’analyse automatisée doit gérer ces ambiguïtés correctement ou pas du tout.
Les modifications implicites sont invisibles. Certaines modifications législatives affectent le sens de dispositions existantes sans les modifier explicitement. Une nouvelle directive européenne peut primer sur le droit national sans que le texte national soit modifié. La recherche sur la détection des modifications implicites montre une précision de seulement 60 % — un problème véritablement non résolu (Huwiler et al., 2025).
Les cascades inter-domaines sont complexes. Une modification du CIR 92 peut affecter la façon dont les produits d’assurance branche 23 sont taxés, ce qui affecte à son tour le traitement en matière de droits de succession VCF en Flandre. Ces impacts inter-domaines nécessitent un raisonnement sur graphe de connaissances, pas un simple traitement textuel.
La divergence bilingue existe. Les versions néerlandaise et française du droit belge sont toutes deux authentiques mais pas toujours parfaitement alignées. Les différences de traduction créent occasionnellement une véritable ambiguïté juridique — et le système doit les signaler plutôt que de choisir silencieusement une version.
Les questions auxquelles votre fournisseur devrait répondre
Si votre outil d’IA juridique prétend être « toujours à jour », posez ces cinq questions :
| Question | Pourquoi c’est important |
|---|---|
| Combien de temps après la publication au Moniteur une nouvelle loi est-elle consultable ? | Des heures ? Des jours ? Des semaines ? L’écart est là où se situe le risque |
| Comment les amendements aux dispositions existantes sont-ils traités ? | Automatisé ? Manuel ? Les deux ? La méthode détermine la précision |
| Qui vérifie que le contenu ingéré correspond à la source publiée ? | Contrôles automatisés ? Revue humaine ? Aucun des deux ? |
| Que se passe-t-il pour les recherches sauvegardées quand la loi sous-jacente change ? | L’utilisateur est-il notifié ? Ou découvre-t-il l’obsolescence à ses dépens ? |
| Quel est le taux d’erreur de votre pipeline d’ingestion ? | S’ils refusent de partager ce chiffre, demandez pourquoi |
L’absence de réponses à ces questions est en soi une réponse.
Questions fréquentes
À quelle vitesse une modification législative devrait-elle être reflétée dans un système d’IA juridique ?
Pour les modifications critiques — nouveaux taux d’imposition, délais modifiés, obligations de déclaration amendées — l’ingestion le jour même est la norme appropriée. Pour du contenu moins urgent comme les commentaires doctrinaux ou les décisions de juridictions inférieures, 24 à 48 heures est acceptable. Tout système qui prend des semaines pour refléter les modifications législatives publiées opère sur un calendrier qui crée un risque professionnel.
Le pipeline d’ingestion peut-il faire des erreurs ?
Oui. Les erreurs d’analyse, la résolution incorrecte des amendements, les références croisées manquées et les échecs d’extraction de métadonnées surviennent tous. La question n’est pas si des erreurs se produisent — c’est si le système les détecte et les corrige avant qu’elles n’atteignent le professionnel. C’est pourquoi l’étape de vérification existe, et pourquoi elle ne devrait jamais être sacrifiée au profit de la vitesse.
Pourquoi le traitement bilingue est-il important pour le droit belge ?
Les versions néerlandaise et française du droit fédéral belge sont également authentiques. Si un système n’ingère qu’une seule version linguistique, il manque du contenu juridique qui n’existe que dans l’autre. Plus important encore, lorsque les deux versions divergent en sens — ce qui arrive — le système devrait signaler cette divergence plutôt que de servir silencieusement une seule interprétation.
Articles connexes
- Qu’est-ce que le versionnage temporel — et pourquoi votre outil d’IA juridique vous sert probablement la loi d’hier → /fr/blog/versionnement-temporel-ia-juridique/
- Qu’est-ce que le chunking — et pourquoi c’est le fondement invisible de la qualité en IA juridique → /fr/blog/quest-ce-que-chunking-ia-juridique/
- Qu’est-ce qu’un graphe de connaissances — et pourquoi il change la façon dont l’IA navigue le droit fiscal belge → /fr/blog/graphe-connaissances-droit-fiscal/
Comment Auryth TX applique ceci
Auryth TX assure une surveillance continue du Moniteur belge et des sources officielles associées. Les nouvelles législations sont détectées, classées et analysées dans les heures suivant leur publication. Le pipeline utilise un découpage conscient de la structure des articles qui préserve l’organisation hiérarchique des textes juridiques belges, avec les amendements résolus contre les dispositions existantes pour maintenir l’historique des versions.
Chaque document ingéré passe par une vérification automatisée avant d’entrer dans le corpus en production. Le graphe de connaissances propage les modifications aux dispositions affectées, et les recherches sauvegardées citant des articles impactés sont signalées pour révision. Nous ne prétendons pas à une ingestion parfaite — nous prétendons à une ingestion transparente, où les erreurs sont détectées et corrigées plutôt que dissimulées.
Quand le droit fiscal belge change demain, notre système le sait demain. Pas la semaine prochaine. Pas « éventuellement ».
Sources : 1. Huwiler, D. et al. (2025). « VersionRAG: Version-Aware Retrieval-Augmented Generation for Evolving Documents ». arXiv preprint. 2. Premasiri, D. et al. (2025). « Survey on legal information extraction: current status and open challenges ». Knowledge and Information Systems, 67, 11287-11358. 3. Ariai, F. & Demartini, G. (2024). « Natural Language Processing for the Legal Domain: A Survey ». ACM Computing Surveys.