Pourquoi nous ne créons pas un chatbot
Les interfaces de chat semblent modernes mais produisent des réponses éphémères et indéfendables. La recherche fiscale professionnelle nécessite des réponses structurées que vous pouvez archiver, reproduire et défendre.
Par Auryth Team
Votre client vous appelle. Il veut savoir comment vous êtes arrivé à la position sur le précompte mobilier que vous avez recommandée il y a six semaines. Vous ouvrez votre outil IA — et vous faites défiler un historique de chat qui ressemble à un monologue de type flux de conscience. Quelque part entre une question de TVA et un fil sur une restructuration d’entreprise, l’échange pertinent est enfoui. Peut-être. Si la session n’a pas été supprimée.
Ce n’est pas un cas isolé. C’est l’expérience par défaut de chaque professionnel utilisant un chatbot pour des recherches sérieuses.
Le paradigme du chatbot a un problème structurel
Toute l’industrie de l’IA juridique a convergé vers le chat. ChatGPT a formé des centaines de millions d’utilisateurs à attendre une zone de texte et une conversation. Tous les concurrents ont suivi. Le résultat : la recherche fiscale professionnelle entassée dans une interface conçue pour la conversation informelle.
Le problème n’est pas la précision — bien que cela compte aussi. Le problème est l’éphémérité. Les conversations de chat sont :
- Non structurées. La réponse est dispersée sur plusieurs échanges, mélangée à vos questions de suivi et aux hésitations de l’IA
- Irreproductibles. Posez la même question demain et obtenez une réponse différente — sans possibilité de comparer
- Inexportables. Essayez de transformer une transcription de chat en note client. Vous réécrirez tout de zéro
- Indéfendables. Quand un collègue, un régulateur ou un client demande « comment êtes-vous arrivé à cette conclusion ? » — un journal de chat n’est pas une réponse
Depuis mi-2023, des centaines de cas d’hallucinations juridiques générées par IA ont été documentés mondialement, dont plus de 50 en juillet 2025 impliquant des citations fabriquées. La plupart concernaient des professionnels qui traitaient les résultats de chat comme de la recherche. Ce n’était pas le cas.
Le test de responsabilité
Avant de vous fier à un outil IA pour un travail professionnel, posez trois questions :
| Question | IA de chat | Plateforme de recherche |
|---|---|---|
| Puis-je reproduire ce résultat la semaine prochaine ? | Non — session différente, réponse différente | Oui — même requête, même output structuré |
| Puis-je exporter ceci comme livrable client ? | Copier-coller une transcription de conversation ? | Output structuré avec citations, prêt à archiver |
| Puis-je défendre ceci en cas de contestation ? | « L’IA me l’a dit dans un chat » | Recherche documentée avec chaîne de sources et indicateurs de confiance |
Si la réponse à l’une de ces questions est non, vous ne faites pas de recherche. Vous avez une conversation.
Ce que vous ne pouvez pas reproduire, vous ne pouvez pas le défendre.
Pourquoi le chat fonctionne — et où il s’arrête
Pour être juste : les interfaces de chat ne sont pas inutiles. Elles fonctionnent bien pour les tâches à faible enjeu où la responsabilité n’importe pas. Prise de contact client sur un site web, notes de brainstorming, rédaction d’un e-mail initial — le chat convient.
L’échec se produit quand les enjeux augmentent. Quand un conseiller fiscal belge s’appuie sur une réponse IA pour une demande de décision anticipée au SDA (Service des Décisions Anticipées), cette réponse doit être traçable à des sources légales spécifiques. Quand un comptable prépare une position pour un peer review ITAA, la recherche doit être reproductible. Quand un notaire structure un plan successoral, l’analyse doit être exportable comme note formelle.
Le chat ne peut faire aucune de ces choses. Non pas parce que le modèle sous-jacent est mauvais, mais parce que l’interface est structurellement incapable de produire un produit de travail défendable.
La réalité réglementaire belge
L’Ordre des barreaux flamands (OVB) a publié des directives IA détaillées exigeant que les professionnels documentent leur utilisation d’outils IA, maintiennent la traçabilité des sources et démontrent que leur travail assisté par IA est juridiquement et éthiquement solide. L’Autorité de protection des données belge (APD) a suivi en septembre 2024 avec des orientations complètes sur les systèmes IA et la conformité RGPD.
L’AI Act européen, pleinement applicable dès août 2026, exige une journalisation structurée automatique pour les systèmes IA à haut risque en vertu de l’article 12. Une transcription de chat ne constitue pas une journalisation structurée.
Pendant ce temps, les assureurs répondent au risque IA avec des exclusions quasi absolues. Les polices de responsabilité professionnelle excluent de plus en plus la couverture pour les réclamations « liées de quelque manière que ce soit à l’IA » — ce qui signifie que si votre conseil assisté par IA tourne mal et que votre documentation est un historique de chat, votre assureur peut refuser la réclamation entièrement.
La direction réglementaire est claire : l’auditabilité n’est pas optionnelle. Chaque outil utilisé dans la pratique professionnelle doit produire un output qui peut être examiné, reproduit et défendu. Les architectures de chat n’ont jamais été conçues pour cela.
Ce que nous construisons à la place : recherche à l’épreuve du dossier
IA à l’épreuve du dossier — dossiervaste AI — signifie que chaque réponse que le système produit peut être archivée, exportée et défendue comme produit de travail professionnel. Pas une conversation. Un livrable de recherche structuré.
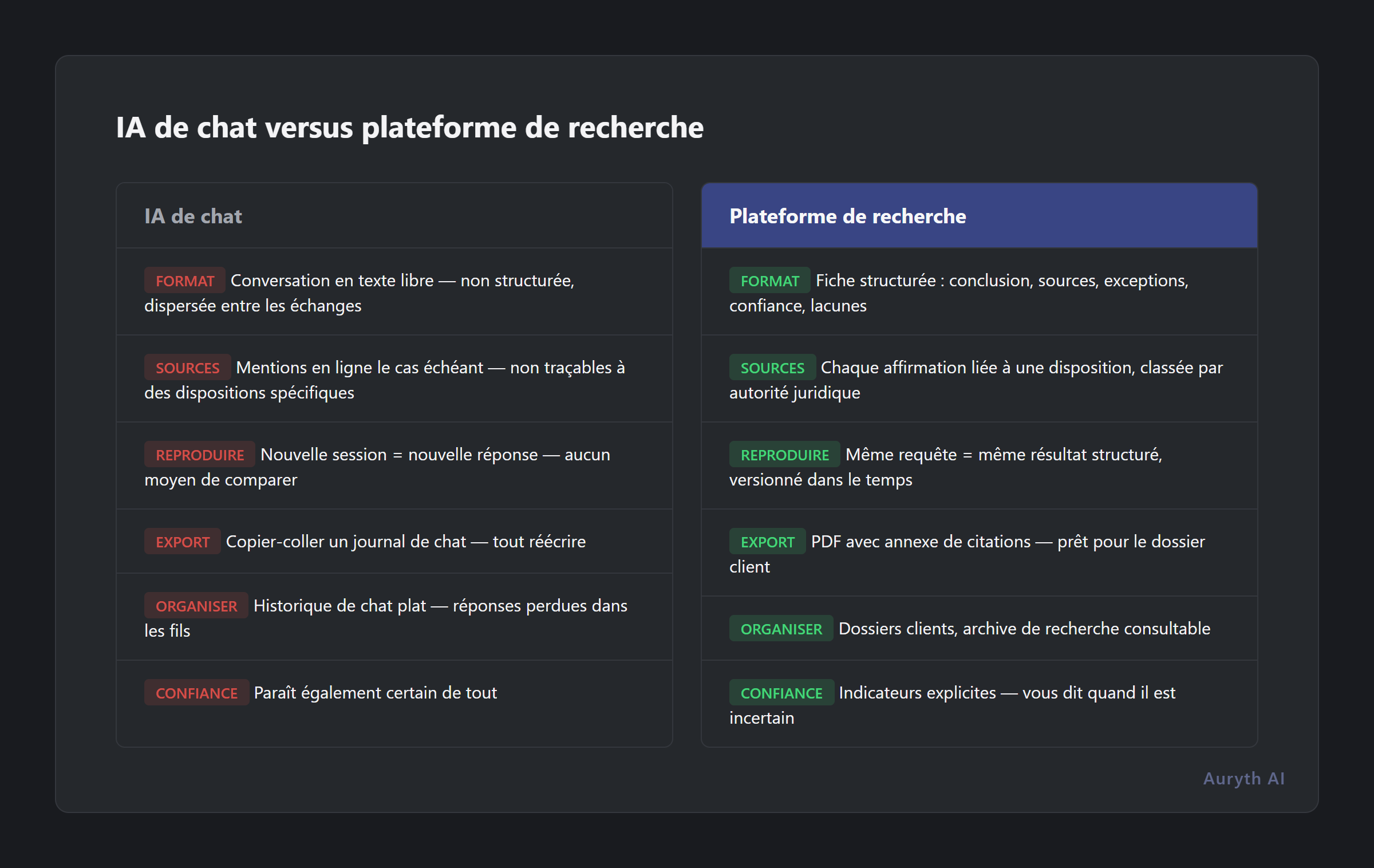
La différence est architecturale, pas cosmétique :
| Aspect | Paradigme du chat | Recherche à l’épreuve du dossier |
|---|---|---|
| Format d’output | Conversation en texte libre | Fiche structurée : conclusion, sources, exceptions, confiance, lacunes |
| Chaîne de sources | Mentions en ligne, le cas échéant | Chaque affirmation liée à une disposition spécifique, classée par autorité juridique |
| Reproductibilité | Nouvelle session = nouvelle réponse | Même requête produit le même résultat structuré, versionné dans le temps |
| Export | Copier-coller un journal de chat | PDF avec annexe de citations, prêt pour le dossier client |
| Organisation | Historique de chat plat | Dossiers clients, archive de recherche consultable |
| Confiance | L’IA semble également certaine de tout | Indicateurs de confiance explicites — le système vous dit quand il est incertain |
Ce n’est pas une préférence de fonctionnalité. C’est la différence entre un outil qui vous aide à brainstormer et un outil qui vous aide à pratiquer.
L’industrie sait déjà que le chat ne suffit pas
Le changement déterminant du legal tech en 2025 a été le passage de l’IA de type chatbot aux systèmes agentiques intégrés. Thomson Reuters, LexisNexis et Harvey ont tous ajouté des fonctionnalités agentiques et intégrées aux workflows en complément de leurs interfaces de chat lors d’ILTACON 2025. Les analystes de l’industrie prédisent que les systèmes IA fourniront de plus en plus des interfaces structurées plutôt que des zones de texte vides.
La question n’est pas de savoir si l’industrie dépasse le chat. C’est de savoir si votre cabinet évolue avant qu’un incident de responsabilité professionnelle ne force la question.
Une part significative du temps des services professionnels est perdue à chercher des réponses dispersées dans des systèmes de connaissances non structurés. Les historiques de chat aggravent cela, au lieu de l’améliorer. Chaque question sans réponse sur « qu’a dit l’IA sur ce cas il y a trois mois ? » représente une connaissance institutionnelle qui a été générée et immédiatement perdue.
Articles connexes
- Qu’est-ce que le classement d’autorité — et pourquoi votre outil IA juridique l’ignore probablement →
- Qu’est-ce que le scoring de confiance — et pourquoi c’est plus honnête qu’une réponse confiante →
- Comment évaluer un outil IA juridique : 10 questions qui comptent vraiment →
Comment Auryth TX applique ceci
Chaque réponse qu’Auryth TX produit suit la même structure : une conclusion claire, une chaîne de sources classée et pondérée par autorité juridique, une carte d’exceptions signalant les risques transversaux, des indicateurs de confiance montrant où le système est certain et où il ne l’est pas, et une détection explicite des lacunes identifiant ce que le système n’a pas pu trouver.
L’output est conçu pour votre dossier client, pas pour votre historique de chat. Exportez en PDF avec une annexe complète de citations. Organisez la recherche par client, par dossier, par question. Revenez à une requête des mois plus tard et obtenez le même résultat structuré — mis à jour si la législation sous-jacente a changé.
Nous n’avons pas créé un chatbot avec de meilleures notes de bas de page. Nous avons créé une plateforme de recherche où chaque réponse est défendable par conception.
Ne conseillez plus jamais sur base de recherches obsolètes — nous vous avertissons automatiquement lorsque les sources changent.
Sources : 1. Charlotin, D. (2025). “AI Hallucination Cases Database.” HEC Paris. 2. Dahl, M. et al. (2024). “Large Legal Fictions: Profiling Legal Hallucinations in Large Language Models.” Journal of Legal Analysis, 16(1), 64-93. 3. Orde van Vlaamse Balies (2024). “AI-richtlijnen voor advocaten.” 4. Autorité de protection des données belge (2024). “Brochure informative : Systèmes IA et RGPD.” Septembre 2024. 5. Règlement UE 2024/1689 (AI Act), Article 12 : Exigences de journalisation automatique pour les systèmes IA à haut risque.