Qu'est-ce que le RAG — et pourquoi il ne suffit pas seul pour l'IA juridique
Comment fonctionne la génération augmentée par la récupération, pourquoi le RAG de base hallucine encore, et ce qu'une architecture de fusion recherche-RAG apporte aux fiscalistes.
Par Auryth Team
Chaque réponse d’IA sans citation de source est une opinion déguisée en recherche. Cela paraît sévère — jusqu’à ce que vous réalisiez que la plupart des outils d’IA utilisés par les professionnels aujourd’hui font exactement cela : générer un texte assuré à partir de la mémoire, sans aucun moyen de vérifier d’où vient la réponse.
L’architecture qui a commencé à résoudre ce problème a un nom : RAG. Mais le RAG de base n’est que le début. Comprendre ce qu’il fait — et où il échoue — est la chose la plus importante qu’un fiscaliste puisse apprendre sur l’IA en 2026.
Qu’est-ce que la génération augmentée par la récupération ?
La Retrieval-Augmented Generation (RAG) est une architecture d’IA dans laquelle le système recherche d’abord des documents pertinents dans une base de connaissances, puis envoie ces documents — accompagnés de votre question — à un modèle de langage qui formule une réponse basée sur ce qu’il a trouvé. Contrairement aux chatbots qui répondent de mémoire, un système RAG fonde chaque réponse sur des sources récupérables.
Imaginez la différence entre deux collègues. L’un répond à votre question fiscale de mémoire — avec assurance, parfois correctement, parfois non. L’autre se rend à la bibliothèque, sort les dispositions pertinentes, les lit, puis vous donne une réponse avec les numéros de page. Le RAG, c’est ce second collègue.
Le concept a été formalisé par Lewis et al. dans un article de 2020 à NeurIPS, combinant la mémoire paramétrique (les connaissances entraînées du modèle de langage) avec la mémoire non paramétrique (un index de documents interrogeable). L’idée était simple mais transformatrice : au lieu de forcer un modèle à tout mémoriser, laissez-le chercher.
Pourquoi le RAG de base ne suffit pas
Voici ce que la plupart des explications sur le RAG ne vous disent pas : le RAG classique — déverser des documents dans une base vectorielle, connecter un modèle de langage, terminé — hallucine encore dans 17–33 % des requêtes juridiques. Les chercheurs de Stanford l’ont prouvé en testant Westlaw AI et Lexis+ AI, deux systèmes RAG construits par les plus grands éditeurs juridiques au monde.
Pourquoi ? Parce que le texte juridique n’est pas comme des articles Wikipédia. Il possède une structure que le RAG de base ignore :
La hiérarchie. Un arrêt de la Cour de cassation prévaut sur une circulaire Fisconetplus. Le RAG de base les traite comme des morceaux de texte équivalents. Quand une circulaire contredit la jurisprudence, un système sans conscience de l’autorité choisit le texte qui correspond le mieux à votre requête — qui pourrait être le mauvais.
La temporalité. Le taux d’impôt des sociétés belge était de 29,58 % en 2019 et de 25 % aujourd’hui. Le RAG de base récupère la version que sa recherche vectorielle fait remonter en premier. Posez une question sur 2019 et vous pourriez obtenir le taux de 2026 — énoncé avec une pleine assurance.
Les renvois croisés. Une seule question fiscale peut couvrir simultanément l’art. 19bis CIR, le cadre TOB et une disposition de la Vlaamse Codex Fiscaliteit. Le RAG de base récupère des fragments. Il ne comprend pas que ces dispositions interagissent.
L’étape de génération aggrave le problème. Même avec une récupération correcte, le modèle de langage peut mal interpréter, surgénéraliser ou combiner des sources d’une manière que les textes originaux ne soutiennent pas. La validation des citations — vérifier que chaque source citée dit effectivement ce que le modèle lui attribue — est une couche supplémentaire nécessaire que le RAG de base n’inclut pas.
Déverser des documents dans une base vectorielle est le RAG minimum viable. Pour le travail juridique, c’est la responsabilité maximum viable.
Du RAG de base à la fusion recherche-RAG
L’intuition qui sépare l’IA juridique de qualité professionnelle d’une démonstration est celle-ci : le RAG est une stratégie de génération, pas une stratégie de recherche. La « récupération » dans RAG n’est aussi bonne que l’infrastructure de recherche en dessous.
Une architecture de fusion recherche-RAG superpose des capacités de recherche professionnelles avant que le modèle de langage ne voie un document :
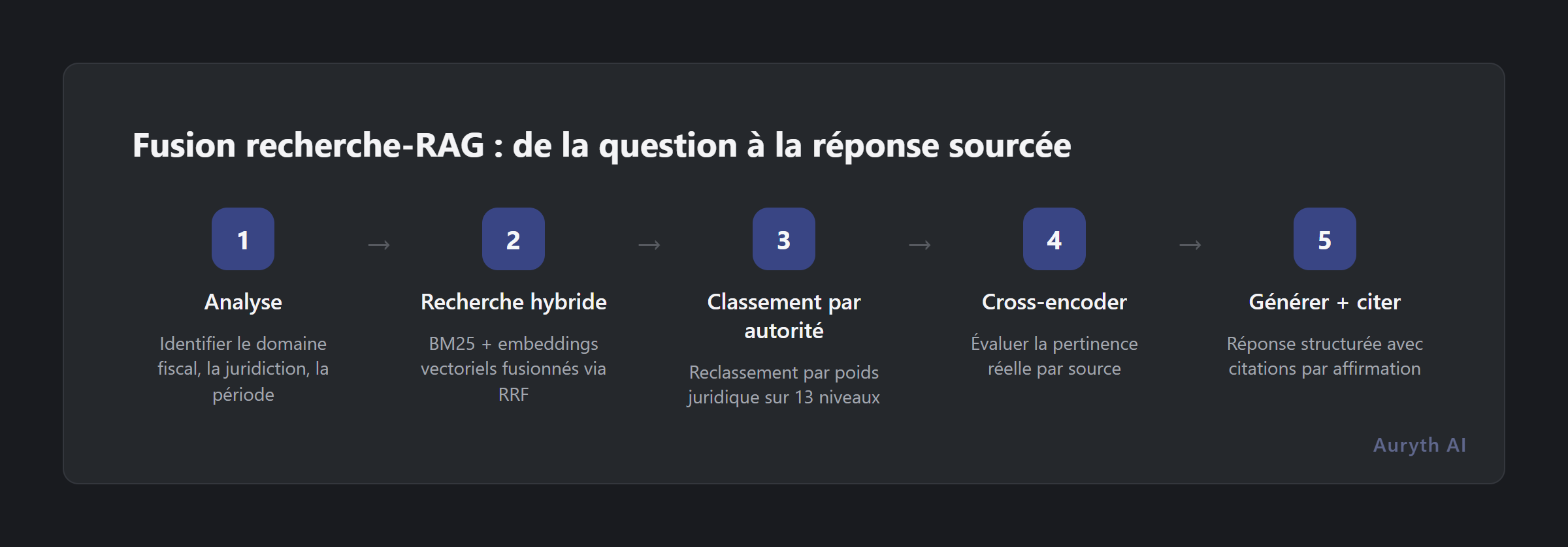
| Étape | Ce qui se passe | Pourquoi le RAG de base ne peut pas faire cela |
|---|---|---|
| 1. Analyse | Le système identifie le domaine fiscal, la juridiction et la période temporelle à partir de votre question | Le RAG de base encode simplement la question brute — aucune conscience du domaine |
| 2. Recherche hybride | Deux stratégies de recherche s’exécutent en parallèle : BM25 (termes juridiques exacts comme « Art. 344 CIR ») et embeddings vectoriels (sens sémantique). Les résultats sont fusionnés via Reciprocal Rank Fusion | Le RAG de base n’utilise que la recherche vectorielle — rate les références exactes d’articles |
| 3. Classement par autorité | Les résultats sont reclassés par poids juridique : Constitution → droit UE → lois fédérales → jurisprudence → circulaires → doctrine | Le RAG de base traite tous les documents de manière égale |
| 4. Reclassement par cross-encoder | Un modèle spécialisé lit chaque source en regard de votre question et évalue la pertinence réelle | Le RAG de base s’appuie sur la similarité des embeddings, qui manque les nuances |
| 5. Génération + citation | Le modèle de langage lit les sources classées et produit une réponse structurée — chaque affirmation liée à sa source | Identique au RAG de base, mais avec des inputs bien meilleurs |
La différence entre l’étape 2 seule (RAG de base) et les étapes 1–4 ensemble (fusion recherche-RAG) est la différence entre trouver un texte pertinent et trouver la bonne loi, de la bonne autorité, au bon moment dans le temps.
Pourquoi la vérifiabilité compte plus que la précision
La plupart des explications sur le RAG se concentrent sur la précision — le RAG réduit les hallucinations, le RAG donne de meilleures réponses. C’est vrai, mais cela passe à côté de l’essentiel.
Le véritable avantage n’est pas la précision. C’est la vérifiabilité.
Un modèle affiné peut être précis à 95 %. Un système recherche-RAG à 92 %. Mais le système recherche-RAG vous montre exactement quelles sources il a utilisées, classées par autorité juridique, de sorte que vous pouvez vérifier les 8 % vous-même. Le modèle affiné ne vous offre aucun moyen de savoir quelles réponses font partie des 5 %.
Pour un fiscaliste, cette différence est déterminante. Votre responsabilité professionnelle ne dépend pas de la précision de l’outil. Elle dépend de votre vérification du conseil donné à votre client.
La question n’est pas « cette IA est-elle précise ? » La question est « puis-je vérifier ? »
Nous appelons cela le principe de vérifiabilité : un outil précis à 90 % et transparent est plus sûr qu’un outil précis à 95 % et opaque. Chaque point de pourcentage de précision que vous ne pouvez pas vérifier est un risque de responsabilité que vous ne pouvez pas gérer.
Fusion recherche-RAG vs. fine-tuning : la bibliothèque vs. le manuel
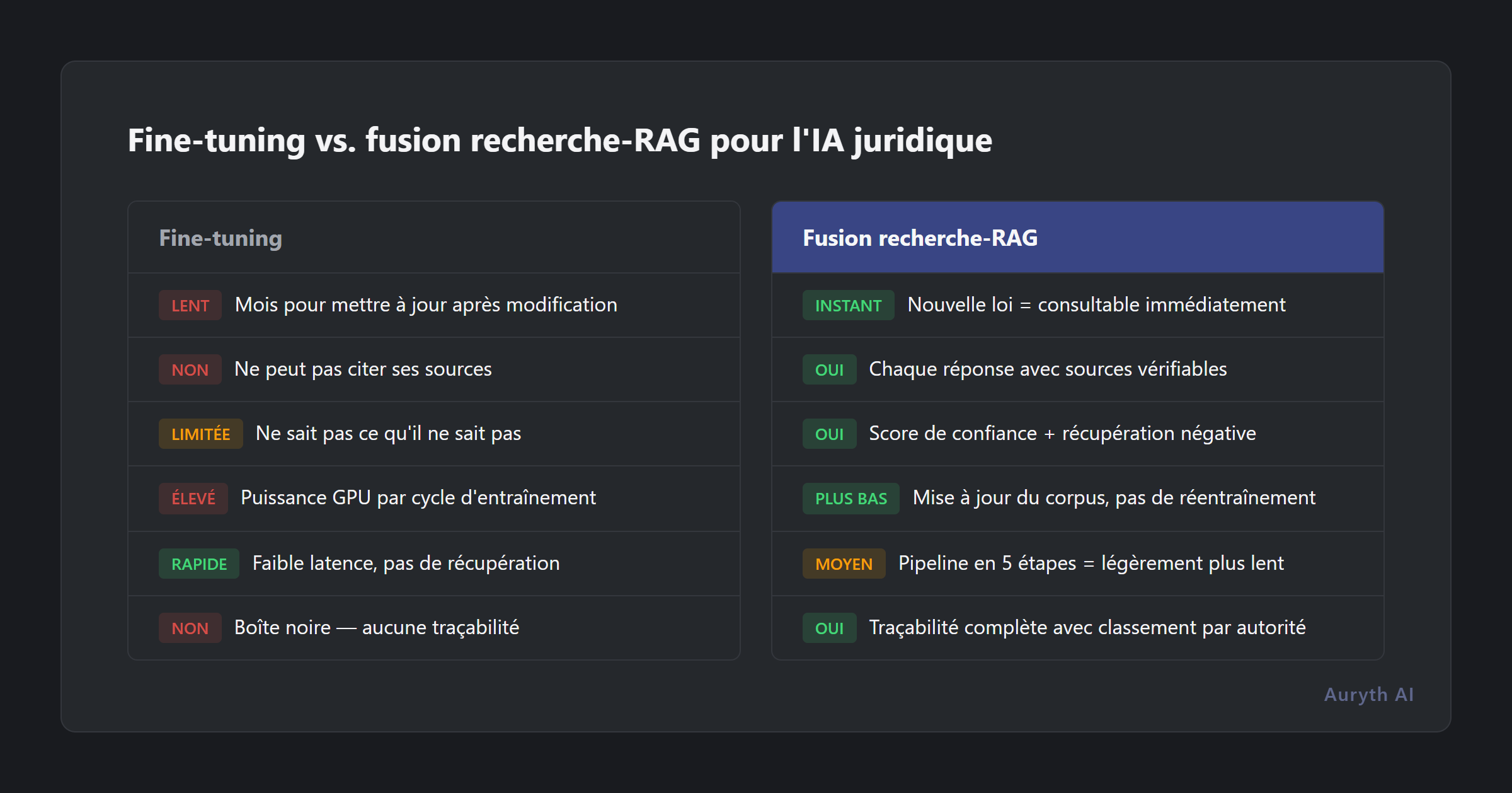
L’alternative principale aux approches basées sur le RAG est le fine-tuning — entraîner un modèle sur des données spécifiques au domaine pour que les connaissances soient intégrées dans ses poids. Imaginez mémoriser un manuel versus avoir accès à une bibliothèque avec un bibliothécaire professionnel.
| Aspect | Fine-tuning | Fusion recherche-RAG |
|---|---|---|
| Source de connaissance | Intégrée dans les poids du modèle | Récupérée depuis un corpus structuré et curé |
| Mise à jour | Réentraîner le modèle (semaines, coûteux) | Mettre à jour le corpus (heures, abordable) |
| Transparence | Boîte noire — réponses non traçables aux sources | Chaîne de citation complète avec classement par autorité |
| Adaptation au droit fiscal belge | La loi change plus vite que les modèles ne sont réentraînés | Nouvelle disposition = immédiatement consultable avec métadonnées |
| Coût | Élevé (puissance GPU pour l’entraînement) | Plus bas (infrastructure de recherche) |
| Risque d’hallucination | Hallucine avec assurance, aucun moyen de vérifier | Peut encore halluciner, mais chaque source est vérifiable |
Harvey, soutenu par plus d’un milliard de dollars d’investissements, a initialement choisi le fine-tuning pour son IA juridique centrée sur les États-Unis. C’est logique pour un système juridique relativement stable avec des moyens considérables pour un réentraînement continu. Le droit fiscal belge — avec trois régions, deux langues officielles, des modifications législatives constantes et un paysage réglementaire qui évolue chaque trimestre — exige une approche différente.
Quand les tranches d’impôt successoral en Flandre changent, un modèle affiné nécessite un réentraînement. Un système recherche-RAG nécessite une mise à jour du corpus.
Ce que cela donne dans la pratique fiscale belge
Prenons une question que tout fiscaliste belge peut rencontrer : « Quelles sont les implications TOB du passage d’un ETF de distribution à un ETF de capitalisation ? »
Un modèle de langage généraliste répondra à partir de données d’entraînement — potentiellement obsolètes de plusieurs mois ou années, pouvant confondre les règles belges et néerlandaises, et incapable de citer l’article spécifique du CIR 92 ou la circulaire Fisconetplus pertinente.
Un système de fusion recherche-RAG conçu pour le droit fiscal belge procède ainsi :
- Analyse la question — identifie la TOB comme domaine fiscal, détermine la période d’imposition pertinente, signale que la classification du fonds est déterminante
- Recherche dans le corpus juridique belge avec une recherche hybride — BM25 trouve « TOB » et les numéros d’articles spécifiques exactement, la recherche vectorielle trouve les dispositions sémantiquement liées à la fiscalité des fonds
- Classe par autorité — une disposition législative prévaut sur une circulaire ; un arrêt de la Cour de cassation prévaut sur la doctrine
- Reclasse par pertinence — un modèle cross-encoder évalue chaque candidat par rapport à votre question réelle, filtrant les faux positifs
- Génère une réponse structurée citant chaque source, avec un score de confiance par affirmation
- Signale les lacunes — si aucune décision spécifique n’existe sur une nuance de votre question, il vous le dit
Ce dernier point compte autant que la réponse elle-même. Dans la pratique fiscale professionnelle, savoir qu’aucune autorité n’existe sur un point spécifique est une information précieuse — cela signifie que vous êtes en territoire d’interprétation et devez agir en conséquence.
Les limites honnêtes
Même un système de fusion recherche-RAG bien conçu a des limites réelles :
La qualité de la récupération est le plafond. Si le bon document n’est pas dans le corpus, ou si le pipeline de recherche ne le fait pas remonter, le modèle ne peut pas l’utiliser. Le système n’est aussi bon que sa base de connaissances et ses algorithmes de recherche.
L’étape de génération peut encore fabriquer. Même avec une récupération et un classement parfaits, le modèle de langage peut mal interpréter des sources ou les combiner d’une manière que les originaux ne soutiennent pas. C’est pourquoi la validation des citations — vérifier indépendamment que chaque source citée dit ce que le modèle prétend — est une couche post-génération nécessaire.
La complexité a un coût. Un pipeline en cinq étapes est plus lent qu’une simple recherche vectorielle. Le compromis en vaut la peine pour le travail professionnel où l’exactitude compte plus que la vitesse — mais c’est un compromis néanmoins.
L’évaluation honnête : la fusion recherche-RAG réduit le problème de catastrophique (58–88 % d’hallucination dans les LLM généralistes) à gérable (significativement en dessous des 17–33 % du RAG juridique de base, avec des couches de vérification supplémentaires). Mais « gérable » signifie encore que le jugement professionnel reste essentiel. Le système accélère votre recherche — il ne remplace pas votre expertise.
Articles connexes
- Hallucinations de l’IA : pourquoi ChatGPT fabrique des sources (et comment les repérer)
- J’ai posé à ChatGPT et Auryth les mêmes questions fiscales belges — voici ce qui s’est passé
- Fine-tuning vs. RAG : deux façons de rendre l’IA intelligente
Comment Auryth TX applique ceci
Auryth TX n’utilise pas le RAG de base. Il fusionne une infrastructure de recherche professionnelle avec la génération augmentée par la récupération — parce que la qualité de la récupération détermine la qualité de la réponse.
Chaque question passe par un pipeline en cinq étapes : recherche hybride (BM25 + embeddings vectoriels fusionnés via Reciprocal Rank Fusion), classement par autorité à travers une hiérarchie juridique belge à 13 niveaux, reclassement par cross-encoder pour la précision, génération de réponses structurées avec citations par affirmation, et validation post-génération des citations avec score de confiance.
Le corpus juridique belge est notre base de connaissances : CIR 92, Fisconetplus, décisions anticipées du SDA, VCF, jurisprudence et publications doctrinales — le tout structuré avec des métadonnées temporelles, des tags de juridiction et des niveaux d’autorité. Quand des sources se contredisent, les deux positions sont présentées. Quand les preuves sont insuffisantes, le score de confiance vous le signale explicitement. Quand la loi change, le corpus est mis à jour en quelques heures.
Nous ne vous demandons pas de faire confiance à l’IA. Nous vous demandons de vérifier les sources qu’elle vous montre. C’est le principe de vérifiabilité en pratique.
Découvrez comment notre pipeline recherche-RAG fonctionne — rejoignez la liste d’attente →
Sources : 1. Lewis, P. et al. (2020). « Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. » NeurIPS. 2. Magesh, V. et al. (2025). « Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools. » Journal of Empirical Legal Studies. 3. Schwarcz, D. et al. (2025). « AI-Powered Lawyering: AI Reasoning Models, Retrieval Augmented Generation, and the Future of Legal Practice. » SSRN.