Achter de schermen: hoe een wetswijziging door een juridisch AI-systeem stroomt
Wanneer de Belgische programmawet in één nacht 47 bepalingen wijzigt, wat gebeurt er dan in de AI-tool waar u op vertrouwt? Een transparante kijk op de ingestion pipeline.
Door Auryth Team
De programmawet werd op een donderdag gestemd. Ze wijzigde 47 bepalingen over zes wetboeken — inkomstenbelasting, btw, sociale zekerheid, vennootschapsrecht, gewestelijke incentives en erfbelasting. Vrijdagochtend was de oude wet verleden tijd. Maandag moesten professionals cliënten adviseren over de nieuwe regels.
Hoe snel weet uw AI-tool dat?
De meeste juridische AI-aanbieders beloven “altijd actuele content.” Geen van hen legt uit wat dat in de praktijk betekent. Ze vertellen niet hoe lang de kloof duurt tussen publicatie en doorzoekbaarheid van een wet. Ze leggen niet uit wat er tijdens die kloof gebeurt. Ze tonen niet wie verifieert dat de opgenomen tekst daadwerkelijk overeenkomt met wat gepubliceerd werd.
Deze stilte zou iedereen moeten verontrusten die op deze tools vertrouwt voor professioneel advies.
Wat “altijd actueel” werkelijk vereist
Het Belgisch Staatsblad publiceert dagelijks nieuwe wetgeving in zowel het Nederlands als het Frans. In 2024 alleen al publiceerde het een record van 141.310 pagina’s — ruwweg 390 pagina’s per dag. Programmawetten landen twee keer per jaar, waarbij elk ervan tientallen bepalingen over niet-gerelateerde domeinen wijzigt in één wetgevend instrument.
Dit volume maakt handmatige monitoring onmogelijk. Maar het maakt ook geautomatiseerde monitoring oprecht moeilijk. Juridische tekst is geen webcontent. Ze heeft geneste hiërarchieën — afdelingen, onderafdelingen, artikelen, paragrafen, punten — die standaard tekstverwerking negeert. Wijzigingen gebruiken gespecialiseerd taalgebruik: “Artikel 145/1 van het WIB 92 wordt vervangen door het volgende…” Het systeem moet niet alleen de nieuwe tekst begrijpen, maar ook welke bestaande bepaling het vervangt, wanneer de wijziging in werking treedt, en welke kruisverwijzingen beïnvloed worden.
Standaard RAG-systemen halen slechts 58% nauwkeurigheid op versiegevoelige vragen omdat ze semantisch vergelijkbare content ophalen zonder temporele geldigheid te controleren. Versiebewuste systemen kunnen 90% bereiken — maar dat vereist een specifieke architectuur, niet enkel “de database updaten” (Huwiler et al., 2025).
De zevenstapspijplijn
Dit is wat er moet gebeuren tussen publicatie van een wet en het moment dat een professional ernaar kan zoeken:
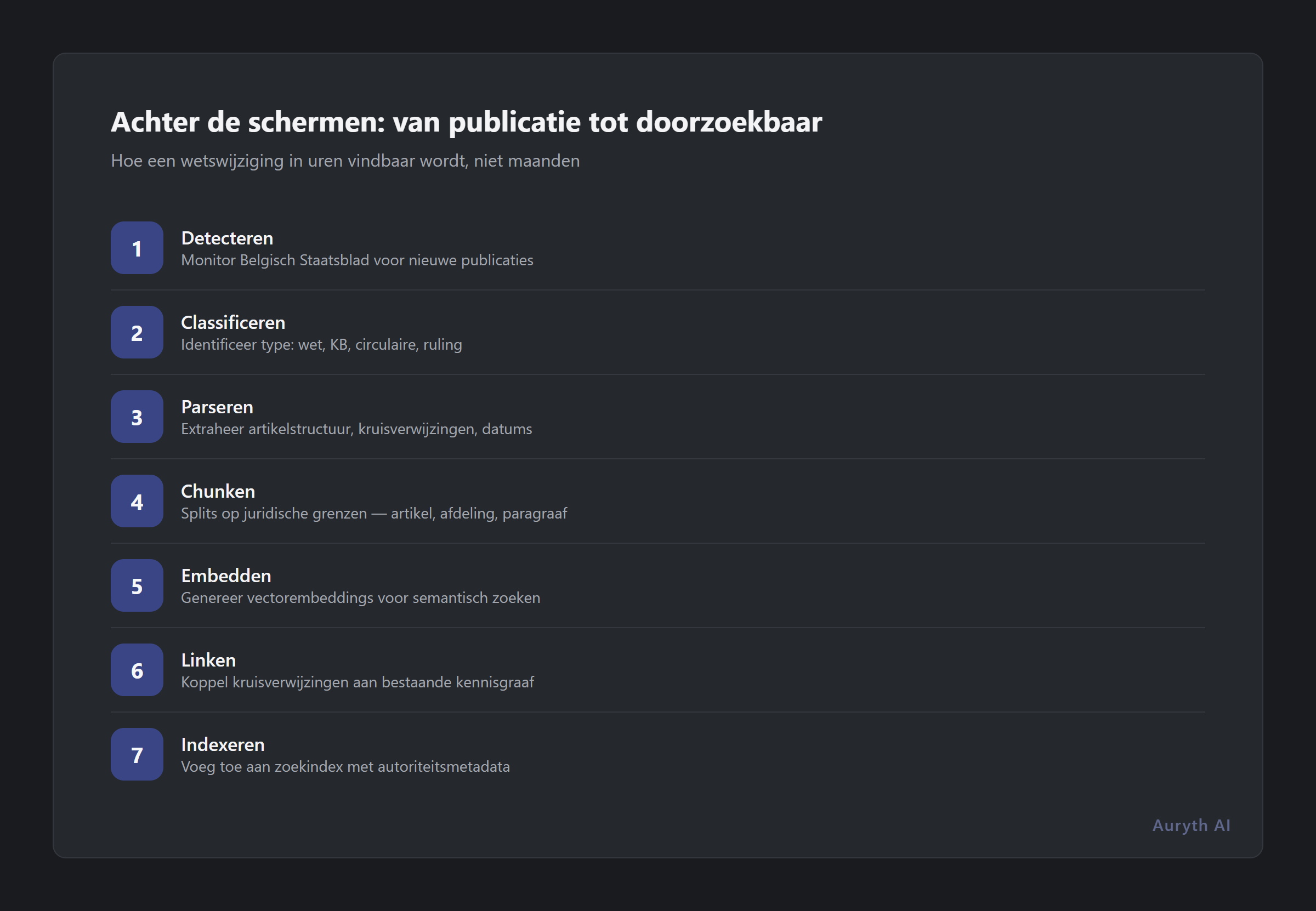
Stap 1: Detectie. Een monitoring-agent houdt het Belgisch Staatsblad in de gaten voor nieuwe publicaties. Dit draait continu — niet wekelijks, niet dagelijks. Nieuwe publicaties worden binnen uren na verschijning in het Staatsblad gedetecteerd.
Stap 2: Classificatie. Niet alles wat gepubliceerd wordt, vereist dezelfde behandeling. Een nieuwe federale wet, een koninklijk besluit, een administratieve circulaire en een rechterlijke uitspraak hebben elk verschillende autoriteitsniveaus, verschillende reikwijdtes en verschillende verwerkingsvereisten. Het systeem classificeert elk document op type vóór verwerking.
Stap 3: Tekstextractie. De ruwe publicatie wordt geparseerd naar gestructureerde tekst. Dit klinkt eenvoudig totdat u tweetalige opmaak, geneste artikelstructuren, tarieftabellen en wijzigingstaal die naar bepalingen in andere wetboeken verwijst, tegenkomt. Zowel de Nederlandse als de Franse versie zijn authentiek — meertalige consistentie moet behouden blijven.
Stap 4: Wijzigingsresolutie. Dit is de moeilijkste stap en degene die de meeste aanbieders overslaan of vereenvoudigen. Wanneer een programmawet zegt “Artikel 215 van het WIB 92 wordt als volgt gewijzigd,” moet het systeem de bestaande bepaling identificeren, de wijziging toepassen, en een nieuwe versie aanmaken terwijl de oude bewaard blijft met haar geldigheidsdatums. Een enkele programmawet kan tientallen van deze bewerkingen over meerdere wetboeken triggeren.
Stap 5: Chunking en embedding. De verwerkte tekst wordt opgesplitst in semantisch betekenisvolle eenheden — niet willekeurige paragrafen, maar artikelbewuste chunks die de juridische structuur behouden. Elke chunk wordt omgezet in vectorembeddings voor semantisch zoeken, terwijl de volledige tekst geïndexeerd wordt voor zoeken op trefwoord. Metadata wordt toegevoegd: inwerkingstredingsdatum, autoriteitsniveau, jurisdictie en kruisverwijzingen.
Stap 6: Verificatie. Voordat nieuwe content het live corpus betreedt, doorloopt het kwaliteitscontroles. Komt de geparseerde tekst overeen met de gepubliceerde bron? Zijn artikelnummers correct geëxtraheerd? Verwijzen kruisverwijzingen naar bestaande bepalingen? Zijn inwerkingstredingsdatums nauwkeurig? Deze stap vangt parseerfouten op voordat ze slecht advies worden.
Stap 7: Impactpropagatie. De kennisgraaf identificeert welke bestaande bepalingen, rechtspraak en commentaar beïnvloed worden door de wijziging. Opgeslagen onderzoek dat naar die bepalingen verwijst, wordt gemarkeerd als mogelijk verouderd. Hier voegt het systeem waarde toe voorbij enkel “de nieuwe wet bevatten” — het vertelt u wat er nog meer veranderde doordat de wet veranderde.
Waar het moeilijk wordt: de uitdagingen waar niemand over praat
Wijzigingstaal is ambigu. “Het eerste lid van artikel 344 wordt aangevuld met een zin…” — welke zin? Waar precies? Juridische redactie is niet altijd precies over invoegpunten, en geautomatiseerde parsing moet deze ambiguïteiten correct afhandelen of helemaal niet.
Impliciete wijzigingen zijn onzichtbaar. Sommige wetswijzigingen beïnvloeden de betekenis van bestaande bepalingen zonder ze expliciet te wijzigen. Een nieuwe EU-richtlijn kan binnenlands recht overrulen zonder dat de binnenlandse tekst wordt aangepast. Onderzoek naar detectie van impliciete wijzigingen toont een nauwkeurigheid van slechts 60% — een oprecht onopgelost probleem (Huwiler et al., 2025).
Domeinoverschrijdende cascades zijn complex. Een wijziging in het WIB 92 kan beïnvloeden hoe TAK 23-verzekeringsproducten belast worden, wat op zijn beurt de VCF-erfbelastingbehandeling in Vlaanderen beïnvloedt. Deze domeinoverschrijdende effecten vereisen kennisgraaf-redenering, niet enkel tekstverwerking.
Tweetalige divergentie komt voor. De Nederlandse en Franse versies van Belgisch recht zijn beide authentiek maar niet altijd perfect gealigneerd. Vertaalverschillen creëren af en toe echte juridische ambiguïteit — en het systeem moet deze signaleren in plaats van stilzwijgend één versie te kiezen.
De vragen die uw aanbieder moet beantwoorden
Als uw juridische AI-tool beweert “altijd actueel” te zijn, stel dan deze vijf vragen:
| Vraag | Waarom het ertoe doet |
|---|---|
| Hoe snel na publicatie in het Staatsblad is een nieuwe wet doorzoekbaar? | Uren? Dagen? Weken? De kloof is waar het risico zit |
| Hoe worden wijzigingen aan bestaande bepalingen verwerkt? | Geautomatiseerd? Manueel? Beide? De methode bepaalt de nauwkeurigheid |
| Wie verifieert dat opgenomen content overeenkomt met de gepubliceerde bron? | Geautomatiseerde controles? Menselijke review? Geen van beide? |
| Wat gebeurt er met opgeslagen onderzoek wanneer onderliggende wetgeving wijzigt? | Wordt de gebruiker genotificeerd? Of ontdekt hij veroudering op de harde manier? |
| Wat is het foutpercentage van uw ingestion pipeline? | Als ze dit getal niet willen delen, vraag waarom |
De afwezigheid van antwoorden op deze vragen is op zichzelf een antwoord.
Veelgestelde vragen
Hoe snel moet een wetswijziging weerspiegeld worden in een juridisch AI-systeem?
Voor kritieke wijzigingen — nieuwe belastingtarieven, gewijzigde deadlines, aangepaste rapportageverplichtingen — is inname op dezelfde dag de juiste standaard. Voor minder urgente content zoals doctrinair commentaar of uitspraken van lagere rechtbanken is 24–48 uur acceptabel. Elk systeem dat weken nodig heeft om gepubliceerde wetswijzigingen weer te geven, opereert op een tijdlijn die professioneel risico creëert.
Kan de ingestion pipeline fouten maken?
Ja. Parseerfouten, incorrecte wijzigingsresolutie, gemiste kruisverwijzingen en fouten in metadata-extractie komen allemaal voor. De vraag is niet of fouten voorkomen — het is of het systeem ze detecteert en corrigeert voordat ze de professional bereiken. Daarom bestaat de verificatiestap, en daarom mag die nooit worden overgeslagen voor snelheid.
Waarom is tweetalige verwerking belangrijk voor Belgisch recht?
Zowel de Nederlandse als de Franse versie van federaal Belgisch recht zijn evenwaardig authentiek. Als een systeem slechts één taalversie opneemt, mist het juridische content die alleen in de andere bestaat. Belangrijker nog: wanneer de twee versies in betekenis divergeren — wat voorkomt — moet het systeem deze divergentie signaleren in plaats van stilzwijgend één interpretatie te serveren.
Gerelateerde artikelen
- Wat is temporele versionering — en waarom uw juridische AI-tool u wellicht de wet van gisteren voorschotelt → /nl/blog/temporele-versionering-juridische-ai/
- Wat is chunking — en waarom het de onzichtbare basis is van kwaliteit in juridische AI → /nl/blog/wat-is-chunking-juridische-ai/
- Wat is een kennisgraaf — en waarom het verandert hoe AI Belgisch fiscaal recht navigeert → /nl/blog/knowledge-graph-fiscaal-recht/
Hoe Auryth TX dit toepast
Auryth TX draait continue monitoring van het Belgisch Staatsblad en gerelateerde officiële bronnen. Nieuwe wetgeving wordt binnen uren na publicatie gedetecteerd, geclassificeerd en geparseerd. De pipeline gebruikt artikelbewuste chunking die de hiërarchische structuur van Belgische juridische teksten behoudt, met wijzigingen die worden opgelost tegen bestaande bepalingen om versiegeschiedenis te bewaren.
Elk opgenomen document doorloopt geautomatiseerde verificatie voordat het het live corpus betreedt. De kennisgraaf propageert wijzigingen naar beïnvloede bepalingen, en opgeslagen onderzoek dat naar beïnvloede artikelen verwijst, wordt gemarkeerd voor review. We beweren geen perfecte inname — we beweren transparante inname, waarbij fouten worden gevangen en gecorrigeerd in plaats van verborgen.
Wanneer Belgisch fiscaal recht morgen verandert, weet ons systeem het morgen. Niet volgende week. Niet “uiteindelijk.”
Bronnen: 1. Huwiler, D. et al. (2025). “VersionRAG: Version-Aware Retrieval-Augmented Generation for Evolving Documents.” arXiv preprint. 2. Premasiri, D. et al. (2025). “Survey on legal information extraction: current status and open challenges.” Knowledge and Information Systems, 67, 11287-11358. 3. Ariai, F. & Demartini, G. (2024). “Natural Language Processing for the Legal Domain: A Survey.” ACM Computing Surveys.