Ik vroeg ChatGPT en Auryth dezelfde Belgische fiscale vragen — dit is wat er gebeurde
Drie fiscale vragen, twee AI-tools, één duidelijke les: voor professioneel onderzoek wint verifieerbaarheid van zelfvertrouwen.
Door Auryth Team
U hebt het gedaan. Uw collega heeft het gedaan. De afgelopen twee jaar heeft elke fiscalist in België wel eens een fiscale vraag ingetypt in ChatGPT.
Het antwoord klonk waarschijnlijk aannemelijk. Misschien zelfs indrukwekkend. Maar de vraag die niemand achteraf stelt: hoe zou u het controleren?
Wij deden een eenvoudig experiment. Drie Belgische fiscale vragen van toenemende complexiteit — het soort vragen dat een fiscalist wekelijks behandelt. We stelden ze aan ChatGPT (GPT-4o) en aan Auryth TX, ons specifiek voor Belgisch fiscaal onderzoek gebouwde platform. Dezelfde vragen, dezelfde dag, geen prompt-engineering-trucjes.
De resultaten onthullen iets interessanters dan “juist versus fout.”
Vraag 1: “Wat is het huidige Belgische vennootschapsbelastingtarief?”
ChatGPT antwoordde correct: 25%, met het verlaagd tarief van 20% voor kmo’s op de eerste €100.000 belastbare winst. Helder. Correct.
Auryth gaf dezelfde cijfers — maar verwees rechtstreeks naar art. 215 WIB 92, linkte naar de specifieke wetsbepaling, en signaleerde de voorwaarden van art. 215, lid 3: de bezoldigingsvereiste en de participatiedrempel.
Beide tools hadden het cijfer juist. Maar slechts één toonde waarom het klopte en welke voorwaarden van toepassing zijn. Wanneer uw cliënt vraagt “komen wij in aanmerking voor het verlaagd tarief?” — is het zelfverzekerde cijfer een vertrekpunt. Het bronvermeldende antwoord is de basis voor advies.
De kloof tussen een correct cijfer en een verifieerbaar antwoord is precies waar de beroepsaansprakelijkheid zit.
Vraag 2: “Wat is het TOB-tarief op een kapitaliserende ETF?”
Hier wordt het interessant.
ChatGPT antwoordde: 1,32%. Stellig geformuleerd. Zonder voorbehoud.
Dat antwoord is onvolledig. TOB-tarieven voor ETF’s zijn 0,12%, 0,35% of 1,32% — afhankelijk van de kenmerken van het fonds. Een kapitaliserende ETF die in België is geregistreerd betaalt 1,32%, maar dezelfde kapitaliserende ETF elders in de EER geregistreerd betaalt slechts 0,12% — een elfvoudig verschil. Of een fonds als “in België geregistreerd” telt, hangt af van of een van de compartimenten bij de FSMA is geregistreerd. Distributie-ETF’s betalen 0,12%. Niet-EER-instrumenten: 0,35%. Een professional die adviseert over een ETF-aankoop moet de specifieke registratie- en distributiestatus van het fonds kennen — niet enkel één tarief.
Auryth identificeerde alle drie de toepasselijke TOB-tarieven, verklaarde de classificatiecriteria — registratielocatie, kapitalisatie versus distributie, EER-status — en signaleerde welk tarief gold voor het specifieke fonds in de vraag.
Dit is classificatieblindheid — een faalwijze van generieke AI. ChatGPT kiest het meest voorkomende antwoord en presenteert het als het enige. De Belgische fiscale wetgeving zit vol classificatieafhankelijkheden: tarieven die verschuiven op basis van productstructuur, registratie, domicilie en houdperiode. Een AI die deze onderscheiden comprimeert tot één zelfverzekerd cijfer is niet gewoon onvolledig — het is gevaarlijk voor professioneel advies.
; Magesh et al. (2025), Stanford HAI")
Vraag 3: “Wat zijn alle fiscale gevolgen van een TAK 23-verzekeringsproduct voor een Belgisch rijksinwoner?”
Nu betreden we echt professioneel terrein.
ChatGPT identificeerde de inkomstenbelasting (met vermelding van art. 19bis WIB voor de Reynders-taks op meerwaarden) en de premietaks. Twee domeinen. Gepresenteerd met hetzelfde onwankelbare vertrouwen als bij vraag 1.
Het miste er drie:
- Schenk- en erfbelasting — essentieel voor successieplanning, geregeld door de Vlaamse Codex Fiscaliteit (VCF) in Vlaanderen, het Wetboek der Successierechten in Wallonië en Brussel
- TOB-vrijstelling — switchen van fondsen binnen een TAK 23-wrapper is niet onderworpen aan beurstaks, in tegenstelling tot directe ETF-transacties. ChatGPT signaleerde dit cruciale structuurvoordeel niet
- Effectentaks — de jaarlijkse taks van 0,15% op effectenrekeningen boven €1 miljoen, die via het doorkijkbeginsel ook op TAK 23-producten van toepassing kan zijn
Een TAK 23-product raakt minstens vijf belastingdomeinen. ChatGPT behandelde er twee. De drie die het miste, zijn precies de domeinen waar cliënten geld verliezen en adviseurs aansprakelijkheidsclaims riskeren.
Auryth structureerde het antwoord als een domeinoverschrijdende analyse: een domeinradar die alle vijf gebieden identificeert, conclusies per domein met bronnen gerangschikt op rechtskracht, betrouwbaarheidsscores (hoog voor inkomstenbelasting, matig voor regionale variaties gezien de evoluerende rechtspraak), en een sectie “geïdentificeerde leemtes” met wat niet gevonden werd.
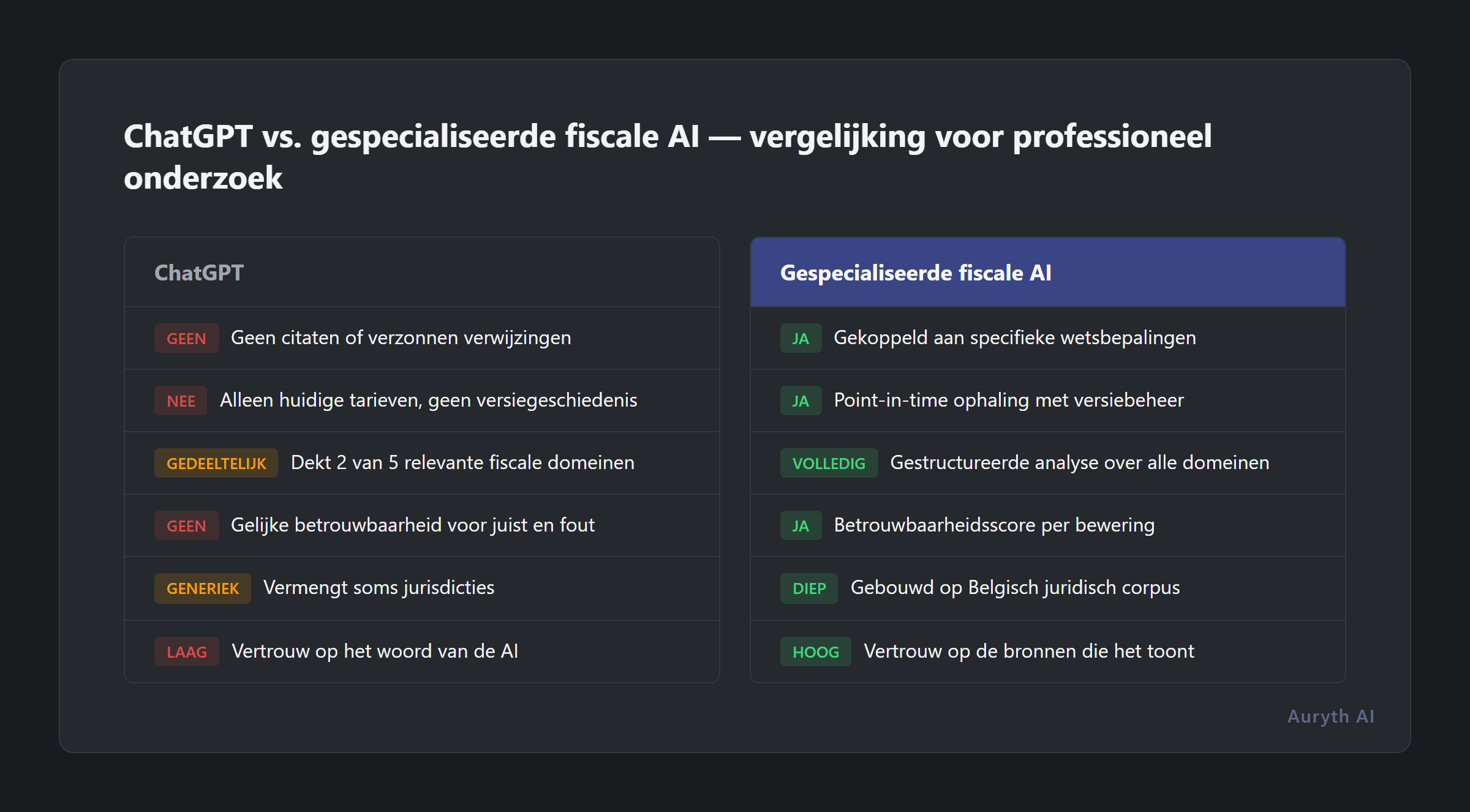
| Dimensie | ChatGPT | Gespecialiseerde fiscale AI |
|---|---|---|
| Bronvermeldingen | Geen of verzonnen | Gelinkt aan specifieke wetsbepalingen |
| Temporeel bewustzijn | Enkel huidige tarieven | Point-in-time opvraging met versiegeschiedenis |
| Domeinoverschrijdende dekking | Gedeeltelijk (2 van 5 domeinen) | Gestructureerde multidomeinanalyse |
| Betrouwbaarheidssignalen | Gelijk vertrouwen voor alles | Betrouwbaarheidsscore per bewering |
| Belgische specificiteit | Generiek, mengt soms jurisdicties | Gebouwd op Belgisch juridisch corpus |
| Verifieerbaarheid | Vertrouw de AI | Vertrouw de bronnen die het u toont |
De Verificatiekloof
Het patroon doorheen alle drie de vragen gaat niet over nauwkeurigheid. Het gaat over verifieerbaarheid.
ChatGPT geeft misschien het juiste simpele antwoord. Maar het vertelt u nooit:
- Waar het antwoord vandaan komt (geen bronvermelding)
- Wanneer het antwoord geldt (geen temporele context)
- Wat ontbreekt in het antwoord (geen dekkingsbeoordeling)
- Hoeveel vertrouwen u erin mag hebben (geen onzekerheidssignaal)
Wij noemen dit de Verificatiekloof: de afstand tussen het zelfverklaarde vertrouwen van een AI en uw mogelijkheid om de beweringen onafhankelijk te controleren. Hoe groter de kloof, hoe groter het professionele risico.
Voor een snelle Google-zoekopdracht doet de Verificatiekloof er niet toe. Voor professioneel fiscaal advies — waar foute antwoorden financiële en juridische gevolgen hebben — is het allesbepalend.
Een tool die 90% nauwkeurig is en daar eerlijk over is, is veiliger dan een tool die 95% nauwkeurig is en u nooit vertelt wanneer het fout zit.
Laten we eerlijk zijn — gespecialiseerde AI is ook niet perfect
Stanford-onderzoekers stelden vast dat zelfs doelgebouwde juridische AI-tools zoals Westlaw AI en LexisNexis+ AI in 17–33% van de gevallen hallucineren. RAG — retrieval-augmented generation, de architectuur achter de meeste gespecialiseerde juridische AI — vermindert hallucinaties drastisch vergeleken met het 58–88%-percentage bij generieke LLM’s. Maar het elimineert ze niet.
Het verschil is geen perfectie. Het is transparantie. Wanneer een gespecialiseerde tool onzeker is, zegt die dat. Wanneer het een bron aanhaalt, kunt u die nakijken. Wanneer het iets mist, signaleert een goed ontworpen systeem de leemte in plaats van een gedeeltelijk antwoord als volledig te presenteren.
De Belgische fiscale wetgeving bevat echte ambiguïteiten: rulings die circulaires tegenspreken, regionale variaties die uiteenlopen, bepalingen met meerdere verdedigbare interpretaties. Geen enkele AI zou het tegendeel mogen beweren.
De Drielagentest
Voordat u op eender welk AI-gegenereerd fiscaal antwoord vertrouwt — ook het onze — pas drie controles toe:
| Laag | Vraag | Hoe falen eruitziet |
|---|---|---|
| Bron | Kunt u het antwoord herleiden tot een specifieke wetsbepaling? | ”Het tarief is 25%” zonder artikelverwijzing |
| Precisie | Houdt het antwoord rekening met alle relevante voorwaarden? | Één tarief bij drie mogelijke tarieven afhankelijk van fondskenmerken |
| Volledigheid | Heeft de tool alle relevante belastingdomeinen gecontroleerd? | Twee domeinen gedekt terwijl er vijf van toepassing zijn |
Als één laag faalt, doet u geen onderzoek — dan gokt u met het geld van uw cliënt en uw beroepsreputatie.
Verwante artikelen
- Wat is RAG — en waarom het ertoe doet voor fiscalisten
- AI-hallucinaties: waarom ChatGPT bronnen verzint
- Wat is Confidence Scoring — en waarom is het eerlijker dan een zelfverzekerd antwoord?
Hoe Auryth TX dit toepast
Auryth TX is specifiek gebouwd voor Belgische fiscalisten die verifieerbare antwoorden nodig hebben, geen zelfverzekerde gissingen. Elk antwoord bevat:
- Bronvermeldingen gerangschikt op rechtskracht — gelinkt aan specifieke bepalingen uit WIB 92, VCF, WBTW en het bredere Belgische juridische corpus, gerangschikt volgens de bronnenhiërarchie
- Temporele versionering — stel een vraag over eender welke datum en ontvang de versie van de wet die toen gold, niet enkel de versie van vandaag
- Domeinoverschrijdende detectie — automatische identificatie van alle belastingdomeinen die een vraag raakt, met gestructureerde analyse per domein
- Betrouwbaarheidsscore — expliciete indicatie van hoe goed elke bewering onderbouwd is, inclusief wat het systeem zocht maar niet vond
Het doel is niet om uw oordeel te vervangen. Het is om u het volledige beeld te geven — met bronnen — zodat uw oordeel de best mogelijke basis heeft.
Probeer het zelf — stel Auryth en ChatGPT dezelfde vraag en vergelijk.
Bronnen: 1. Dahl, M. et al. (2024). “Large Legal Fictions: Profiling Legal Hallucinations in Large Language Models.” Journal of Legal Analysis, 16(1), 64–93. 2. Magesh, V. et al. (2025). “Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools.” Journal of Empirical Legal Studies. 3. Lewis, P. et al. (2020). “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.” NeurIPS. 4. EY Nederland (2023). “Is ChatGPT uw nieuwe belastingadviseur?”