J'ai posé les mêmes questions fiscales belges à ChatGPT et Auryth — voici ce qui s'est passé
Trois questions fiscales, deux outils IA, une leçon claire : pour la recherche professionnelle, la vérifiabilité l'emporte.
Par Auryth Team
Vous l’avez fait. Votre collègue l’a fait. À un moment donné au cours des deux dernières années, chaque fiscaliste en Belgique a tapé une question fiscale dans ChatGPT.
La réponse semblait probablement raisonnable. Peut-être même impressionnante. Mais voici la question que personne ne pose ensuite : comment la vérifieriez-vous ?
Nous avons mené une expérience simple. Trois questions fiscales belges de complexité croissante — le genre qu’un professionnel fiscal traite chaque semaine. Nous les avons posées à ChatGPT (GPT-4o) et à Auryth TX, notre plateforme de recherche fiscale belge spécialement conçue. Mêmes questions, même jour, aucune astuce d’ingénierie de prompt.
Les résultats révèlent quelque chose de plus intéressant que « correct vs. incorrect ».
Question 1 : « Quel est le taux actuel de l’impôt des sociétés belge ? »
ChatGPT a répondu correctement : 25 %, avec le taux réduit de 20 % pour les PME sur les premiers 100 000 € de bénéfice imposable. Clair. Précis.
Auryth a donné les mêmes chiffres — mais a cité l’Art. 215 CIR 92 (WIB 92) directement, avec un lien vers la disposition spécifique, et a signalé les conditions de l’Art. 215, paragraphe 3 : l’exigence de rémunération et le seuil de participation.
Les deux outils ont donné le bon chiffre. Mais un seul a montré pourquoi c’était correct et quelles conditions s’appliquent. Lorsque votre client demande « remplissons-nous les conditions pour le taux réduit ? » — le chiffre confiant est un point de départ. La réponse sourcée est une fondation pour le conseil.
L’écart entre un chiffre correct et une réponse vérifiable est l’endroit où vit la responsabilité professionnelle.
Question 2 : « Quel est le taux de TOB sur un ETF de capitalisation ? »
C’est là que cela devient intéressant.
ChatGPT a répondu : 1,32 %. Affirmé avec confiance. Sans réserves.
Cette réponse est incomplète. Les taux de TOB pour les ETF sont de 0,12 %, 0,35 % ou 1,32 % selon les caractéristiques du fonds. Un ETF de capitalisation enregistré en Belgique paie 1,32 %, mais le même ETF de capitalisation enregistré ailleurs dans l’EEE ne paie que 0,12 % — une différence de onze fois. Qu’un fonds soit considéré comme « enregistré en Belgique » dépend de l’enregistrement de l’un de ses compartiments auprès de la FSMA. Les ETF de distribution paient 0,12 %. Les instruments hors EEE : 0,35 %. Un professionnel conseillant sur l’achat d’un ETF doit connaître le statut d’enregistrement et de distribution spécifique du fonds — pas seulement un taux unique.
Auryth a identifié les trois taux de TOB applicables, expliqué les critères de classification — lieu d’enregistrement, capitalisation vs. distribution, statut EEE — et signalé quel taux s’appliquait au fonds spécifique dans la question.
C’est la cécité de classification — un mode de défaillance de l’IA généraliste. ChatGPT choisit la réponse la plus courante et la présente comme la seule. Le droit fiscal belge est plein de dépendances de classification : des taux qui changent selon la structure du produit, l’enregistrement, le domicile et la période de détention. Une IA qui réduit ces distinctions à un seul chiffre confiant n’est pas seulement incomplète — elle est dangereuse pour le conseil professionnel.
 ; Magesh et al. (2025), Stanford HAI")
Question 3 : « Quelles sont toutes les implications fiscales d’un produit d’assurance TAK 23 pour un résident belge ? »
Nous sommes maintenant en territoire professionnel.
ChatGPT a identifié l’impôt sur les revenus (mentionnant l’Art. 19bis CIR pour la taxe Reynders sur les plus-values) et la taxe sur les primes d’assurance. Deux domaines. Présentés avec la même confiance inébranlable que la Question 1.
Il en a manqué trois :
- Droits de donation et de succession — essentiels pour la planification successorale, régis par le Code flamand de la Fiscalité (VCF) en Flandre, le Code des droits de succession en Wallonie et à Bruxelles
- Exonération de TOB — les arbitrages au sein d’un contrat TAK 23 ne sont pas soumis à la taxe boursière, contrairement aux transactions directes sur ETF. ChatGPT n’a pas signalé cet avantage structurel clé
- Taxe sur les comptes-titres — la taxe annuelle de 0,15 % sur les comptes-titres dépassant 1 million d’euros, qui peut s’appliquer aux produits TAK 23 via le principe de transparence fiscale
Un produit TAK 23 touche au moins cinq domaines fiscaux. ChatGPT en a couvert deux. Les trois qu’il a manqués sont exactement ceux où les clients perdent de l’argent et les conseillers font face à des réclamations de responsabilité.
Auryth a structuré sa réponse comme une analyse inter-domaines : un radar de domaines identifiant les cinq zones, des conclusions par domaine avec des sources classées par autorité, des scores de confiance (élevé pour l’impôt sur les revenus, modéré pour les variations régionales compte tenu de la jurisprudence évolutive), et une section « lacunes identifiées » notant ce qui n’a pas été trouvé.
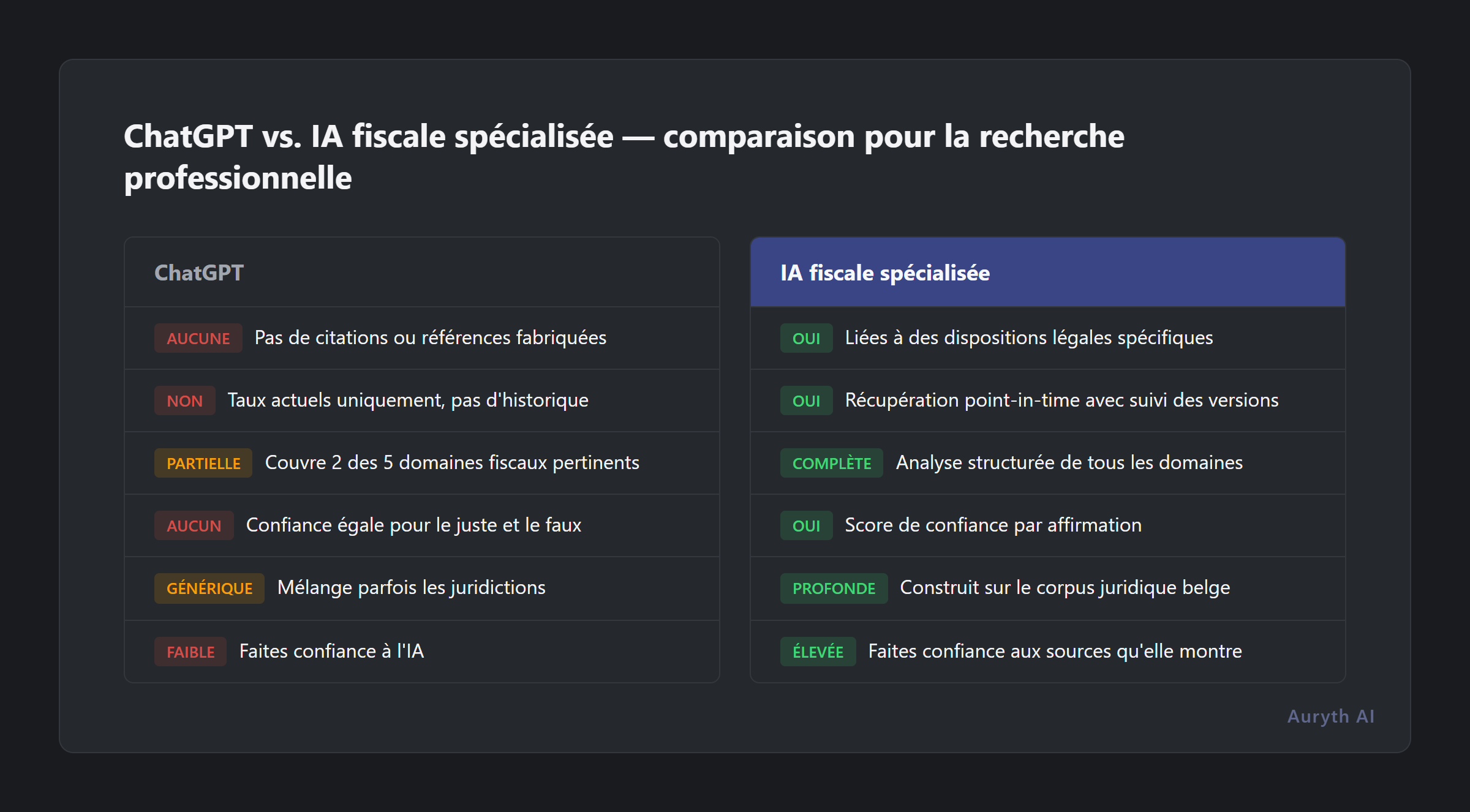
| Dimension | ChatGPT | IA fiscale spécialisée |
|---|---|---|
| Citations de sources | Aucune ou fabriquées | Liées à des dispositions légales spécifiques |
| Conscience temporelle | Taux actuels uniquement | Récupération ponctuelle avec historique des versions |
| Couverture inter-domaines | Partielle (2 domaines sur 5) | Analyse structurée multi-domaines |
| Signaux de confiance | Confiance égale pour tout | Notation de confiance par affirmation |
| Spécificité belge | Générique, mélange parfois les juridictions | Construit sur le corpus juridique belge |
| Vérifiabilité | Faites confiance à l’IA | Faites confiance aux sources qu’elle vous montre |
Le fossé de vérification
Le schéma à travers les trois questions ne concerne pas l’exactitude. Il concerne la vérifiabilité.
ChatGPT peut obtenir la réponse simple correctement. Mais il ne vous dit jamais :
- D’où vient la réponse (pas de citation de source)
- Quand la réponse s’applique (pas de contexte temporel)
- Ce qui manque dans la réponse (pas d’évaluation de la couverture)
- Quelle confiance vous devriez avoir (pas de signal d’incertitude)
Nous appelons cela le Fossé de Vérification : la distance entre la confiance affirmée d’une IA et votre capacité à vérifier indépendamment ses affirmations. Plus le fossé est large, plus le risque professionnel est grand.
Pour une recherche Google rapide, le Fossé de Vérification n’a pas d’importance. Pour un conseil fiscal professionnel — où les mauvaises réponses entraînent des conséquences financières et juridiques — c’est tout.
Un outil précis à 90 % et honnête à ce sujet est plus sûr qu’un outil précis à 95 % qui ne vous dit jamais quand il se trompe.
Mais soyons honnêtes — l’IA spécialisée n’est pas parfaite non plus
Les chercheurs de Stanford ont constaté que même les outils d’IA juridique spécialement conçus comme Westlaw AI et LexisNexis+ AI hallucinent 17 à 33 % du temps. Le RAG — génération augmentée par récupération, l’architecture derrière la plupart des IA juridiques spécialisées — réduit considérablement les hallucinations par rapport au taux de 58 à 88 % observé dans les LLM généralistes. Mais il ne les élimine pas.
La différence n’est pas la perfection. C’est la transparence. Lorsqu’un outil spécialisé est incertain, il vous le dit. Lorsqu’il cite une source, vous pouvez la vérifier. Lorsqu’il manque quelque chose, un système bien conçu signale la lacune plutôt que de présenter une réponse partielle comme complète.
Le droit fiscal belge contient de véritables ambiguïtés : des décisions qui contredisent des circulaires, des variations régionales qui divergent, des dispositions avec plusieurs interprétations valides. Aucune IA ne devrait prétendre le contraire.
Le test à trois niveaux
Avant de vous fier à toute réponse fiscale générée par IA — y compris la nôtre — appliquez trois vérifications :
| Niveau | Question | À quoi ressemble l’échec |
|---|---|---|
| Source | Pouvez-vous retracer la réponse jusqu’à une disposition légale spécifique ? | « Le taux est de 25 % » sans référence d’article |
| Précision | La réponse tient-elle compte de toutes les conditions pertinentes ? | Un seul taux donné quand trois s’appliquent selon les caractéristiques du fonds |
| Exhaustivité | L’outil a-t-il vérifié tous les domaines fiscaux pertinents ? | Deux domaines couverts quand cinq s’appliquent |
Si un niveau échoue, vous ne faites pas de recherche — vous jouez avec l’argent de votre client et votre réputation professionnelle.
Articles connexes
- Qu’est-ce que le RAG — et pourquoi c’est important pour les fiscalistes
- Hallucinations de l’IA : pourquoi ChatGPT fabrique des sources
- Qu’est-ce que le confidence scoring — et pourquoi c’est plus honnête qu’une réponse confiante ?
Comment Auryth TX applique ceci
Auryth TX est construit spécifiquement pour les fiscalistes belges qui ont besoin de réponses vérifiables, pas de suppositions confiantes. Chaque réponse inclut :
- Citations de sources classées par autorité — liées à des dispositions spécifiques du CIR 92, VCF, Code TVA et du corpus juridique belge plus large — classées par hiérarchie juridique
- Versionnage temporel — posez une question sur n’importe quelle date et obtenez la version de la loi qui s’appliquait alors, pas seulement la version actuelle
- Détection inter-domaines — identification automatique de tous les domaines fiscaux qu’une question touche, avec une analyse structurée par domaine
- Scoring de confiance — indication explicite du degré de soutien de chaque affirmation, y compris ce que le système a cherché mais n’a pas trouvé
L’objectif n’est pas de remplacer votre jugement. C’est de vous donner le tableau complet — avec sources — pour que votre jugement ait la meilleure fondation possible.
Découvrez par vous-même — posez à Auryth et ChatGPT la même question et comparez.
Sources : 1. Dahl, M. et al. (2024). “Large Legal Fictions: Profiling Legal Hallucinations in Large Language Models.” Journal of Legal Analysis, 16(1), 64–93. 2. Magesh, V. et al. (2025). “Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools.” Journal of Empirical Legal Studies. 3. Lewis, P. et al. (2020). “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.” NeurIPS. 4. EY Nederland (2023). “Is ChatGPT uw nieuwe belastingadviseur?”