Fine-tuning vs. RAG : deux façons de rendre l'IA intelligente — et pourquoi le choix de votre outil fiscal compte
Le fine-tuning mémorise la loi d'hier. Le RAG consulte celle d'aujourd'hui. Pour les fiscalistes belges, ce choix d'architecture détermine si votre outil d'IA est à jour ou confidemment obsolète.
Par Auryth Team
Harvey, l’entreprise d’IA juridique la mieux financée au monde, a levé plus d’un milliard de dollars et construit son système sur le fine-tuning — entraîner un modèle sur des données juridiques jusqu’à ce que le savoir soit intégré dans ses paramètres. Si vous évaluez des outils d’IA pour la recherche fiscale, vous rencontrerez cette approche. Vous rencontrerez aussi le RAG, la génération augmentée par récupération, où le modèle consulte une base de connaissances organisée au lieu de réciter de mémoire.
Ce ne sont pas de simples détails techniques. Ce sont des décisions d’architecture qui déterminent si votre outil d’IA peut montrer ses sources, rester à jour quand la loi change, et vous dire quand il ne sait pas quelque chose. Pour un fiscaliste belge, cette distinction compte plus que n’importe quel benchmark de précision.
Ce que le fine-tuning fait réellement
Le fine-tuning prend un modèle de langage pré-entraîné et le réentraîne sur des données spécifiques au domaine — arrêts, codes fiscaux, commentaires juridiques — jusqu’à ce que le modèle « absorbe » ces connaissances dans ses paramètres. Voyez-le comme la mémorisation d’un manuel très épais et très coûteux.
Le résultat : le modèle parle le langage du droit plus couramment. Il reconnaît la terminologie juridique, comprend les schémas de raisonnement et produit des résultats que les juristes préfèrent. Le partenariat de Harvey avec OpenAI a produit un modèle personnalisé de jurisprudence où les avocats préféraient le résultat dans 97% des cas.
Mais le savoir est figé au moment de l’entraînement. Le mettre à jour signifie réentraîner — un processus qui coûte des dizaines de milliers par itération et prend des semaines à des mois. Quand la loi-programme belge de juillet 2025 a modifié le régime de déduction pour investissement, un modèle entraîné en mars 2025 ne le savait pas.
Ce que le RAG fait réellement
La génération augmentée par récupération ne modifie pas le modèle. Elle lui donne accès à une base de connaissances interrogeable. Quand vous posez une question, le système cherche d’abord dans le corpus, récupère les documents pertinents, puis envoie ces documents — avec votre question — au modèle pour la génération de réponse.
Voyez la différence entre un collègue qui répond de mémoire et un qui va d’abord à la bibliothèque. Les détails techniques — recherche hybride, classement par autorité, reranking par cross-encoder — sont traités dans notre article sur la fusion recherche-RAG.
L’avantage crucial : quand la loi change, vous mettez à jour le corpus. Le modèle n’a pas besoin d’être réentraîné. Et parce que chaque réponse est générée à partir de documents récupérés, chaque affirmation peut être retracée jusqu’à une source spécifique.
La comparaison qui compte
Internet regorge de comparaisons fine-tuning vs. RAG. La plupart se concentrent sur la précision et le coût. Ceux-ci comptent, mais pour les professionnels du droit, ils ne sont pas les facteurs décisifs. Voici ce qui détermine réellement quelle architecture sert le travail fiscal professionnel :
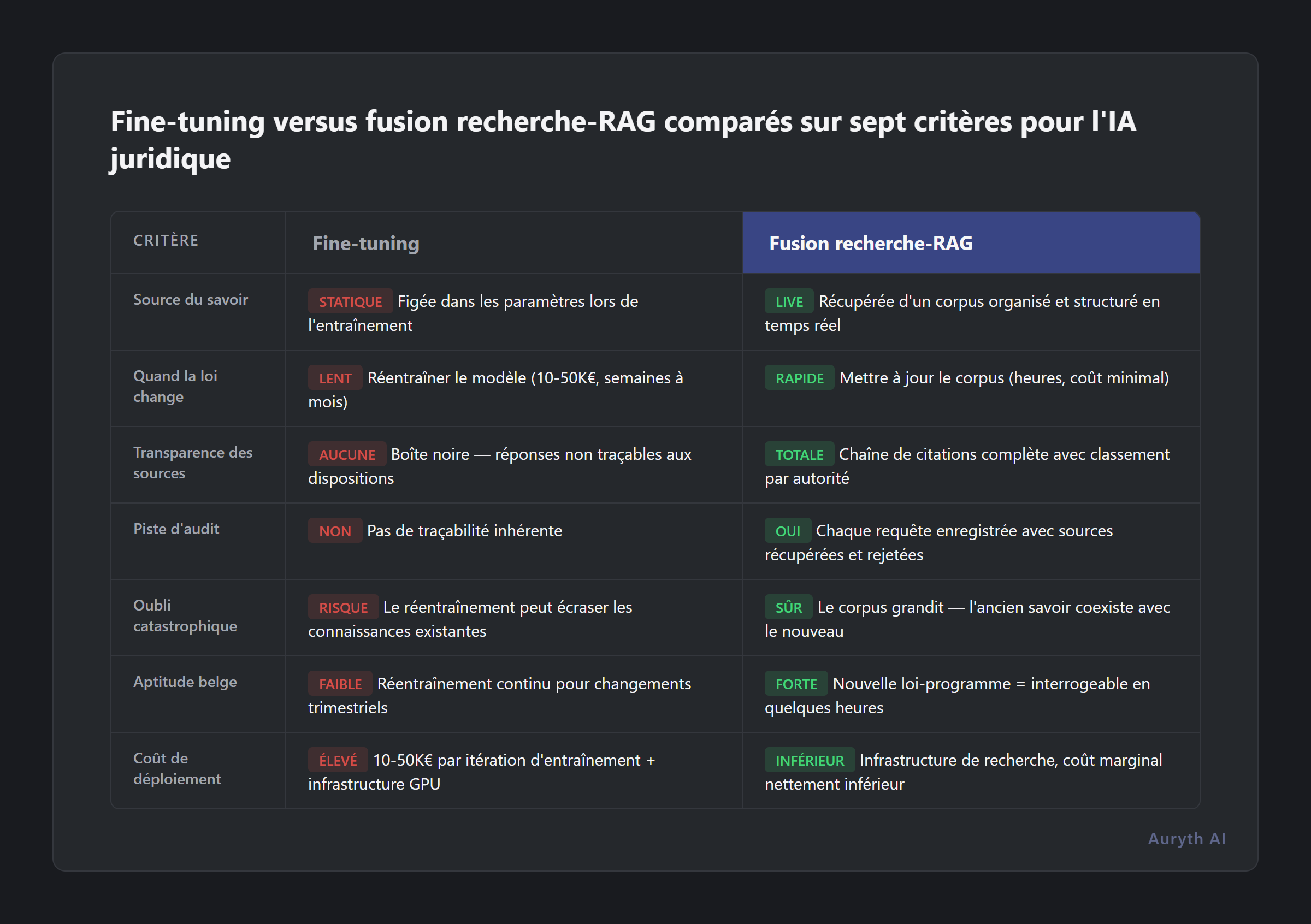
| Critère | Fine-tuning | Fusion recherche-RAG |
|---|---|---|
| Source du savoir | Intégrée dans les paramètres du modèle lors de l’entraînement | Récupérée d’un corpus organisé et structuré en temps réel |
| Quand la loi change | Réentraîner le modèle (10–50k€, semaines à mois) | Mettre à jour le corpus (heures, coût minimal) |
| Transparence des sources | Boîte noire — réponses non traçables jusqu’aux dispositions spécifiques | Chaîne de citations complète avec classement par autorité |
| Piste d’audit | Pas de traçabilité inhérente | Chaque requête enregistrée avec sources récupérées et rejetées |
| Oubli catastrophique | Le réentraînement peut écraser les connaissances existantes | Le corpus grandit — l’ancien savoir coexiste avec le nouveau |
| Aptitude belge | Nécessite un réentraînement continu pour un système juridique qui change trimestriellement | Nouvelle loi-programme = interrogeable en quelques heures |
| Coût de déploiement | 10–50k€ par itération d’entraînement + infrastructure GPU | Infrastructure de recherche, coût marginal nettement inférieur |
La ligne transparence est celle qui devrait vous arrêter. Un modèle fine-tuné qui vous donne la bonne réponse mais ne peut pas montrer pourquoi — quel article précis, quel arrêt, quelle circulaire — vous met dans la même position qu’un collègue qui dit « faites-moi confiance, je m’en souviens. » La responsabilité professionnelle exige plus que la mémoire.
Pourquoi Harvey a choisi le fine-tuning (et pourquoi cela ne s’applique pas ici)
Le choix de Harvey est logique pour leur marché. Le droit américain et britannique — notamment la jurisprudence et la rédaction de contrats — est relativement stable. Des cycles de réentraînement de plusieurs mois sont acceptables quand la loi ne change pas trimestriellement. Leur clientèle (grands cabinets facturant 500$+/heure) peut absorber les tarifs enterprise. Et leur cas d’utilisation (révision de contrats, rédaction de documents, mémos juridiques) bénéficie des avantages de fluidité du fine-tuning.
Le droit fiscal belge est un tout autre animal. Deux grandes lois-programmes par an. Trois régions avec des règles divergentes. Deux langues officielles avec des terminologies juridiques différentes. Un cycle de réforme qui a apporté en 2025 seul une nouvelle taxe sur les plus-values, remanié le régime des expatriés, restructuré la déduction pour investissement et réécrit les délais d’imposition.
Un modèle entraîné en janvier 2025 est déjà obsolète en juillet 2025. Ce n’est pas une préoccupation théorique. C’est la réalité de la pratique fiscale belge.
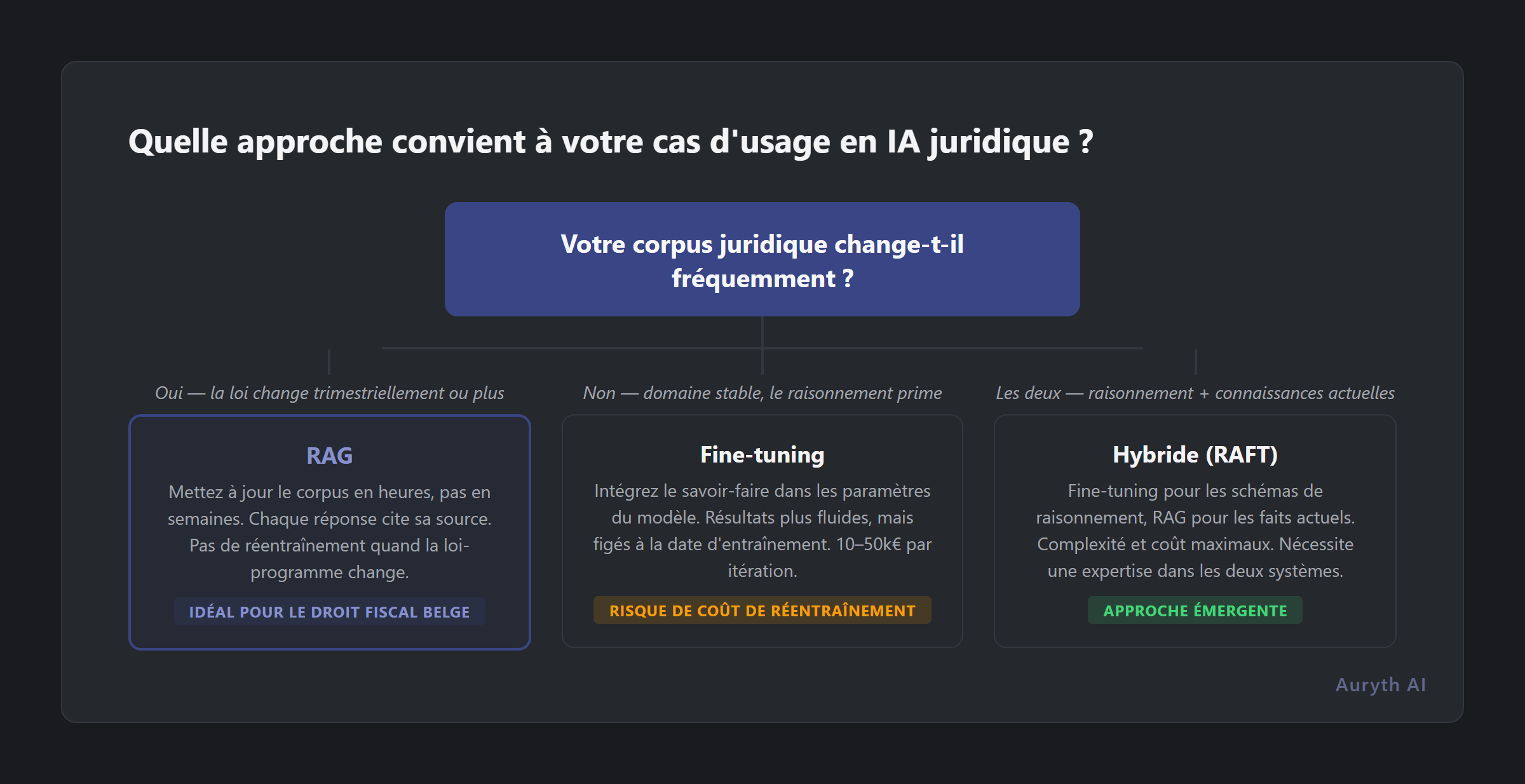
Le test de fraîcheur : si votre droit change plus vite que votre modèle ne se réentraîne, le fine-tuning est la mauvaise architecture.
L’argument hybride (et ses limites)
La réponse honnête est que l’industrie évolue vers des approches hybrides — le fine-tuning pour les schémas de raisonnement, le RAG pour les connaissances actuelles. La recherche appelle cela RAFT (Retrieval-Augmented Fine-Tuning). L’idée est solide : apprendre au modèle à raisonner comme un juriste via le fine-tuning, puis lui donner des faits actuels via le RAG.
Mais les approches hybrides héritent de la complexité des deux systèmes. Vous avez besoin d’expertise en entraînement de modèles et en infrastructure de recherche. Vous devez maintenir les connaissances du modèle fine-tuné synchronisées avec le corpus de récupération. Et l’équation de coût double.
Pour l’IA fiscale belge, le choix pragmatique est clair : commencez par une excellente récupération. Si le fine-tuning apporte de la valeur pour des tâches de raisonnement spécifiques, ajoutez-le sélectivement. Mais la qualité de récupération est le fondement — sans elle, même le meilleur modèle fine-tuné ne peut pas citer l’article spécifique qui répond à votre question.
Où le RAG échoue
L’honnêteté intellectuelle exige de reconnaître les vraies limites du RAG :
La qualité de récupération est le plafond. Si le corpus ne contient pas le bon document, ou si le pipeline de recherche ne le fait pas remonter, le modèle ne peut pas l’utiliser. Les modèles fine-tunés peuvent parfois raisonner par analogie de manières que les systèmes RAG purs peinent à reproduire.
Moins fluide sur les tâches spécialisées. Les modèles fine-tunés produisent souvent des résultats plus polis et natifs du domaine. Les systèmes RAG génèrent des réponses à partir du contexte récupéré, ce qui peut sembler moins « juridique » en ton.
Complexité du pipeline. Un pipeline de fusion recherche-RAG en cinq étapes a plus de parties mobiles qu’un simple appel de modèle fine-tuné. Plus de composants signifie plus de points de défaillance potentiels.
Le compromis est réel. Mais pour la recherche fiscale professionnelle — où la vérifiabilité compte plus que la fluidité, et l’actualité plus que le polissage — le compromis favorise la récupération.
Articles connexes
- Qu’est-ce que le RAG — et pourquoi il ne suffit pas seul pour l’IA juridique
- Pourquoi la transparence compte plus que la précision en IA juridique
- Hallucinations de l’IA : pourquoi ChatGPT fabrique des sources (et comment les repérer)
Comment Auryth TX applique ceci
Auryth TX a choisi la fusion recherche-RAG — non pas parce que le fine-tuning est mauvais, mais parce que le droit fiscal belge exige une architecture capable de suivre le rythme.
Chaque question passe par un pipeline en cinq étapes : recherche hybride (BM25 + embeddings vectoriels), classement par autorité à travers la hiérarchie juridique belge, reranking par cross-encoder, génération de réponse structurée avec citations par affirmation, et validation des citations post-génération. La base de connaissances est le corpus juridique belge — CIR 92, VCF, Fisconetplus, décisions anticipées du SDA, arrêts — tous structurés avec des métadonnées temporelles et des tags de juridiction.
Quand la loi-programme de juillet 2025 a restructuré le régime de déduction pour investissement, notre corpus reflétait le changement en quelques heures. Un modèle fine-tuné aurait eu besoin d’être réentraîné. Le nôtre a eu besoin d’une mise à jour du corpus.
Nous ne vous demandons pas de faire confiance à la mémoire du modèle. Nous vous demandons de vérifier les sources qu’il récupère. C’est la décision d’architecture qui rend cela possible.
Sources : 1. Harvey AI (2025). « Harvey Raises Series E. » Annonce blog. 2. Soudani, H., Kanoulas, E. & Hasibi, F. (2024). « Fine Tuning vs. Retrieval Augmented Generation for Less Popular Knowledge. » arXiv:2403.01432. 3. Magesh, V. et al. (2025). « Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools. » Journal of Empirical Legal Studies.