Qu'est-ce que le chunking — et pourquoi c'est le fondement invisible de la qualité de l'IA juridique
Avant qu'un outil d'IA juridique puisse répondre à une question, il doit découper la loi en morceaux. La façon dont il découpe détermine si la réponse inclut l'exception qui change tout — ou si elle l'omet complètement.
Par Auryth Team
Toute discussion sur la qualité de l’IA juridique aboutit invariablement au même point : la récupération (retrieval). Le système trouve-t-il les bonnes sources ? Renvoie-t-il les dispositions pertinentes ? Détecte-t-il l’exception enfouie dans le troisième alinéa ?
Mais avant que la récupération puisse se produire, quelque chose de plus fondamental doit intervenir. Le système doit décider comment découper le corpus juridique en morceaux — des morceaux suffisamment petits pour être recherchés, suffisamment grands pour rester significatifs. Ce processus s’appelle le chunking, et c’est le facteur le plus sous-estimé de la qualité de l’IA juridique.
Si c’est mal fait, le meilleur modèle de récupération au monde renverra des réponses incomplètes. Si c’est bien fait, même un système modeste peut produire des résultats défendables.
Pourquoi l’IA a besoin de chunks
Les modèles de langage modernes ont des fenêtres de contexte de plus en plus grandes — tant Claude que GPT-4.1 supportent désormais jusqu’à un million de tokens. On pourrait penser que cela élimine complètement le besoin de chunking : il suffirait de fournir à l’IA le code juridique complet et de poser la question.
Cela ne fonctionne pas pour trois raisons.
Dilution de l’attention. La recherche montre systématiquement que les LLM peinent avec les informations placées au milieu d’entrées très longues — un phénomène connu sous le nom d’effet « lost in the middle ». Le modèle prête fortement attention au début et à la fin du texte, mais s’affaiblit entre les deux. Pour un corpus juridique où l’exception critique peut se situer au paragraphe 47 d’une entrée de 200 paragraphes, ce n’est pas une préoccupation théorique.
Précision de la récupération. Un système RAG (Retrieval-Augmented Generation) ne fournit pas l’ensemble du corpus au modèle. Il recherche dans le corpus les morceaux les plus pertinents, récupère les meilleurs résultats et ne fournit que ceux-ci au modèle. Cela nécessite que le corpus soit divisé en unités consultables — des chunks. La qualité de ces chunks détermine la qualité de ce que voit le modèle.
Coût et latence. Le traitement d’un million de tokens coûte 2 à 15 € par requête selon le modèle. Pour un outil de recherche fiscale qui traite des dizaines de requêtes par jour, bourrer le contexte avec l’intégralité du corpus n’est pas économiquement viable.
Le chunking n’est pas un contournement pour des fenêtres de contexte limitées. C’est une exigence architecturale pour les systèmes basés sur la récupération — et tout système d’IA juridique sérieux est basé sur la récupération.
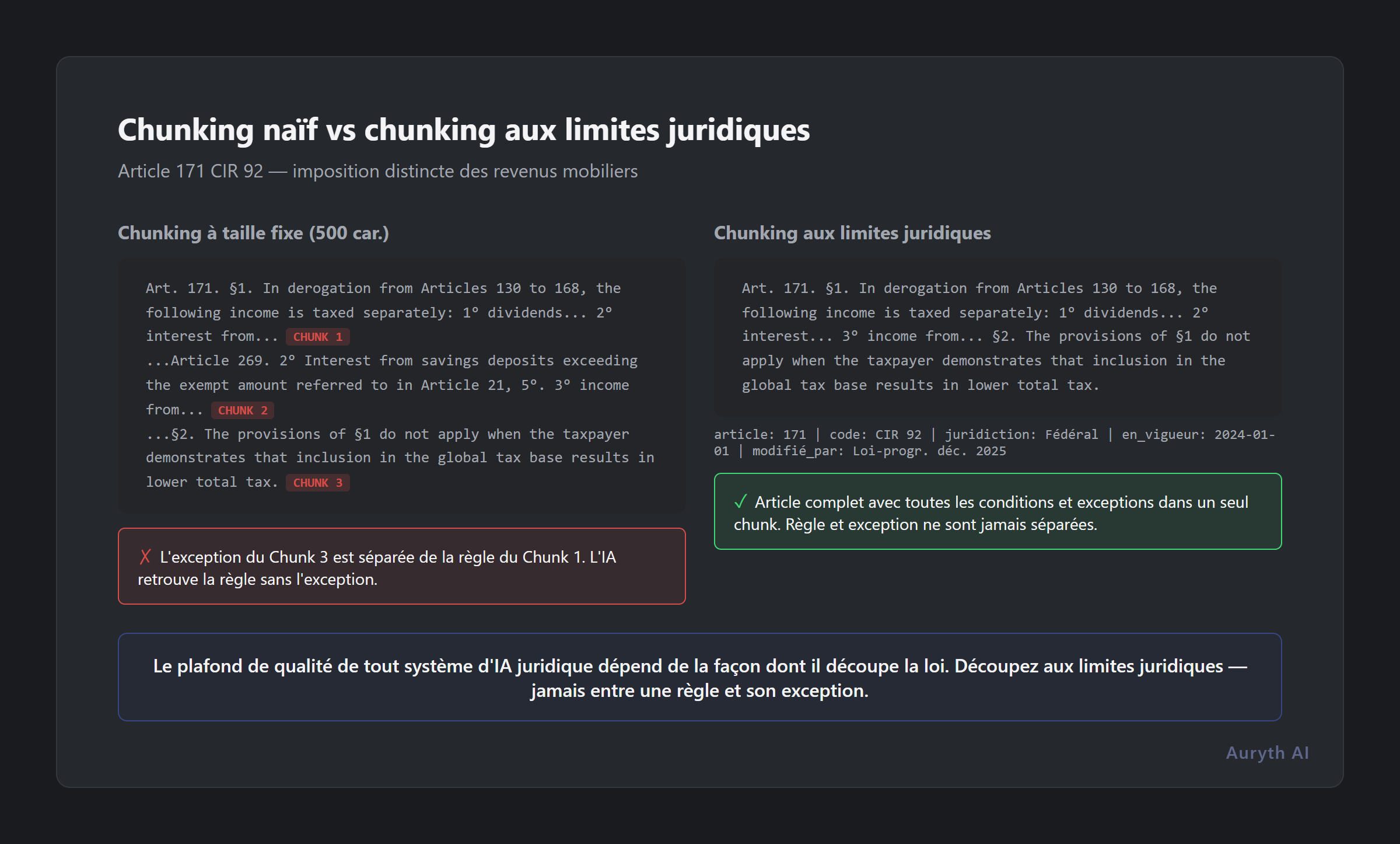
Le chunking naïf : la mauvaise façon de découper
L’approche la plus simple est le chunking à taille fixe : diviser le texte tous les 500 caractères ou 200 tokens, quel que soit le contenu.
C’est ainsi que de nombreux outils d’IA polyvalents traitent les documents. Cela fonctionne assez bien pour les articles de blog, les e-mails clients et les manuels de produits — du texte où le sens d’un paragraphe ne dépend pas de manière critique du suivant.
Pour le texte juridique, c’est catastrophique.
Prenons l’article 171 du Code des impôts sur les revenus belge (CIR 92), qui régit l’imposition distincte des revenus mobiliers. Une structure simplifiée :
Article 171. §1. Par dérogation aux articles 130 à 168, les revenus suivants sont imposés distinctement :
1° dividendes [conditions]…
2° intérêts [conditions]…
[plusieurs catégories numérotées avec des taux spécifiques]
§2. Les dispositions du §1 ne s’appliquent pas lorsque le contribuable démontre que l’inclusion dans la base imposable globale entraîne une charge fiscale totale inférieure.
Un chunker naïf qui divise tous les 500 caractères pourrait produire :
Chunk 1 : « Article 171. §1. Par dérogation aux articles 130 à 168, les revenus suivants sont imposés distinctement : 1° dividendes soumis à… » (coupe en plein milieu de la disposition)
Chunk 2 : « …un précompte mobilier au taux fixé par l’article 269. 2° intérêts provenant de… » (continue de nulle part)
Chunk 3 : « …§2. Les dispositions du §1 ne s’appliquent pas lorsque le contribuable démontre que l’inclusion dans la base imposable globale… » (l’exception, désormais orpheline de son contexte)
Une IA qui ne récupère que le Chunk 1 affirmera que les dividendes sont imposés distinctement — point final. Elle manquera le fait que le contribuable peut choisir de les inclure dans le revenu global si cela entraîne une imposition inférieure. Ce n’est pas une nuance. Pour un client ayant peu d’autres revenus, cette exception change tout le résultat du conseil.
Le problème du « sauf »
Le texte juridique belge a une structure caractéristique qui rend le chunking naïf particulièrement dangereux. Les dispositions suivent régulièrement un schéma :
Règle générale → sauf (exception) → à moins que (unless) → à condition que (provided that)
Chaque qualification restreint ou inverse la règle générale. Le sens juridique de toute disposition dépend de la chaîne complète — règle plus toutes ses qualifications.
Lorsqu’un chunker à taille fixe divise cette chaîne, la règle générale apparaît absolue. L’IA voit « les dividendes sont imposés distinctement à 30 % » sans voir « sauf lorsque la base imposable globale entraînerait une imposition inférieure » ou « à moins que l’exonération RDT ne s’applique ».
Ce n’est pas de l’hallucination au sens technique. L’IA reproduit fidèlement ce qui lui a été fourni. L’échec s’est produit en amont, lors du chunking, où la disposition complète a été découpée en fragments qui ont détruit son sens juridique.
Le chunking aux frontières juridiques : découper aux articulations
L’alternative consiste à découper aux frontières juridiques — les divisions structurelles que le législateur a réellement prévues.
Le droit fiscal belge suit une structure hiérarchique :
Code (CIR 92, Code TVA, VCF)
└─ Titre (Titre I : Impôts sur les revenus)
└─ Chapitre (Chapitre III : Impôt des sociétés)
└─ Section (Section II : Base imposable)
└─ Article (Article 215)
└─ Paragraphe (§1, §2, §3)
└─ Alinéa (alinéa 1, alinéa 2)
└─ Point numéroté (1°, 2°, 3°)Le chunking aux frontières juridiques respecte cette hiérarchie. L’unité par défaut est l’article — la pierre angulaire fondamentale du droit codifié. Chaque article traite d’un concept juridique distinct et est conçu pour être autonome (bien qu’il puisse faire référence à d’autres articles).
Les articles courts comme l’article 1 CIR 92 (« Un impôt sur l’ensemble des revenus est établi… ») tiennent facilement dans un seul chunk avec de la marge.
Les articles moyens comme l’article 215 CIR 92 (taux d’imposition des sociétés, taux réduit PME, conditions d’éligibilité) remplissent un chunk avec toutes les conditions intactes.
Les articles longs avec des dizaines de paragraphes et de points numérotés peuvent dépasser les limites pratiques d’un chunk. Pour ceux-ci, le système divise aux frontières de paragraphes (§), préservant des unités sémantiques complètes. Si les paragraphes sont encore trop longs, il divise aux frontières d’alinéas — mais jamais en milieu de phrase, jamais en milieu de clause, jamais entre une règle et son exception.
Le Code flamand de la fiscalité (VCF) ajoute une couche supplémentaire de précision structurelle avec sa numérotation hiérarchique distinctive : l’article 2.10.4.0.1 encode directement le Titre 2, Chapitre 10, Section 4 dans le numéro d’article. Cette carte de structure intégrée rend le chunking aux frontières juridiques particulièrement propre.
Ce que chaque chunk emporte avec lui
Un fragment de texte sans métadonnées est un fragment sans contexte. Dans l’IA juridique, le contexte est tout.
Chaque chunk dans un système correctement conçu porte des métadonnées d’identification :
- Numéro d’article et référence de code — « Article 215 CIR 92 » ou « Article 2.7.1.0.3 VCF »
- Juridiction — Fédéral, ou régional (Flandre, Wallonie, Bruxelles)
- Dates d’effet — Quand cette version de la disposition est entrée en vigueur et, le cas échéant, quand elle a été remplacée
- Historique des modifications — Quelle loi-programme a modifié pour la dernière fois cette disposition, et ce qui a changé
- Références croisées — Quels autres articles cette disposition cite, et quels articles la citent
- Niveau d’autorité — Législation primaire, arrêté royal, circulaire ou ruling administratif
Ces métadonnées transforment la récupération de « trouver du texte qui ressemble à la question » en « trouver la disposition actuelle et faisant autorité de la juridiction correcte qui s’applique à la période spécifique du client ».
Sans cela, le système pourrait récupérer une version 2019 de l’article 215 indiquant un taux d’impôt des sociétés de 29,58 % — texte techniquement exact, mais erroné pour toute question sur le régime actuel.
Comment la qualité du chunking se propage dans le système
Le pipeline de récupération fonctionne comme une chaîne :
Chunking → Embedding → Retrieval → Reranking → Génération de réponse
Chaque étape dépend de la sortie de la précédente. Un mauvais chunking propage des erreurs à travers toutes les étapes suivantes.
L’embedding convertit chaque chunk en un vecteur mathématique. Si le chunk est un fragment de phrase qui se termine en plein milieu d’une clause, l’embedding capture une pensée incomplète — et correspondra aux mauvaises requêtes.
Le retrieval recherche les chunks dont les embeddings sont les plus similaires à la question. Si l’exception critique a été séparée de la règle lors du chunking, la récupération peut renvoyer la règle sans l’exception — ou l’exception sans la règle.
Le reranking réévalue les meilleurs résultats avec un modèle plus sophistiqué. Il peut détecter certaines erreurs de chunking en reconnaissant qu’un résultat est incomplet. Mais il ne peut pas reconstruire des informations qui ont été réparties sur des chunks qu’il ne voit jamais.
La génération de réponse synthétise les chunks récupérés en une réponse. Si elle reçoit cinq dispositions bien découpées et complètes avec métadonnées, elle peut produire une réponse défendable avec des citations appropriées. Si elle reçoit cinq fragments de texte sans numéros d’article et sans dates d’effet, même le modèle le plus performant produira une réponse qui semble confiante mais ne peut être vérifiée.
C’est l’intuition fondamentale : le plafond de qualité de tout système d’IA juridique basé sur RAG est fixé par sa stratégie de chunking. Aucune sophistication de modèle en aval ne peut compenser une destruction structurelle en amont.
Ce que cela signifie pour les praticiens
Lors de l’évaluation d’un outil d’IA juridique, la stratégie de chunking n’est pas un détail technique à ignorer. C’est la décision architecturale qui détermine si l’outil peut renvoyer de manière fiable des dispositions juridiques complètes avec leurs exceptions, conditions et contexte temporel.
Trois questions à poser :
-
L’outil préserve-t-il les articles complets avec toutes les conditions et exceptions ? Si la réponse concerne la façon dont l’outil « résume » les dispositions ou « extrait les points clés », le chunking détruit peut-être la structure juridique au lieu de la préserver.
-
Chaque résultat comporte-t-il des métadonnées — numéro d’article, juridiction, date d’effet ? Si les résultats affichent du texte sans provenance claire, le système découpe probablement sans métadonnées. Cela rend la vérification et la citation impossibles.
-
L’outil peut-il distinguer les dispositions actuelles des dispositions historiques ? Si le système renvoie des versions obsolètes sans les signaler, les métadonnées temporelles manquent — un échec de chunking et d’indexation.
L’ironie du chunking, c’est que lorsqu’il fonctionne bien, il est invisible. L’utilisateur voit simplement des réponses correctes, complètes et bien citées. L’architecture qui a rendu ces réponses possibles — le découpage minutieux, la préservation des métadonnées, la détection des frontières — fonctionne entièrement en coulisses.
Lorsqu’il fonctionne mal, les échecs sont également invisibles — jusqu’à ce qu’un client se fie à un conseil qui a manqué l’exception dans le troisième alinéa.
Articles connexes
- Qu’est-ce que le RAG — et pourquoi c’est la seule architecture qui rend l’IA juridique défendable →
- Qu’est-ce que le classement d’autorité — et pourquoi votre outil d’IA juridique l’ignore probablement →
- Qu’est-ce que le scoring de confiance — et pourquoi c’est plus honnête qu’une réponse confiante →
Comment Auryth TX applique cela
Auryth TX découpe aux frontières juridiques — articles, paragraphes et alinéas — jamais à des limites arbitraires de caractères ou de tokens. Le CIR 92, le Code TVA, le VCF et les codes régionaux sont chacun analysés selon leurs conventions structurelles spécifiques. La numérotation hiérarchique du VCF, la structure paragraphe-et-alinéa du CIR, l’organisation article-et-arrêté-royal du Code TVA — chacun nécessite une approche d’analyse différente, et chacun en reçoit une.
Chaque chunk porte sa provenance complète : numéro d’article, référence de code, juridiction, plage de dates d’effet, chaîne de modifications et références croisées aux dispositions connexes. Lorsque le système récupère l’article 215 CIR 92, il récupère la version actuelle — avec des métadonnées signalant quand il a été modifié pour la dernière fois par la loi-programme de juillet 2025 et ce qui a changé.
Le résultat : lorsque le système dit « les dividendes sont imposés distinctement selon l’article 171 CIR 92 », la disposition complète est derrière cette réponse — y compris l’exception du §2 pour les contribuables qui bénéficient de l’inclusion globale. L’exception n’est pas dans un chunk différent. Elle est là, parce que le système n’a jamais séparé la règle de ses qualifications.
Chunking aux frontières juridiques. Chaque disposition complète. Chaque exception préservée.
Sources : 1. Liu, N.F. et al. (2024). “Lost in the Middle: How Language Models Use Long Contexts.” Transactions of the ACL, 12, 157-173. 2. ResearchGate (2024). “Legal Chunking: Evaluating Methods for Effective Legal Text Retrieval.” 3. Milvus (2025). “Best practices for chunking lengthy legal documents for vectorization.” 4. Weaviate (2024). “Chunking Strategies for RAG.” 5. Elvex (2026). “Context Length Comparison: Leading AI Models in 2026.”