Qu'est-ce que le scoring de confiance — et pourquoi c'est plus honnête qu'une réponse assurée
Les LLM surestiment leur propre exactitude de 20 à 60%. Le scoring de confiance ne résout pas ce problème — il le rend visible. Pour les fiscalistes, cette visibilité fait la différence entre un outil de recherche et une machine à deviner.
Par Auryth Team
Posez une question fiscale belge à ChatGPT et vous obtiendrez une réponse claire, bien structurée et autoritaire. Posez-lui une question dont il ne peut pas connaître la réponse, et vous obtiendrez exactement le même ton. Même structure. Même assurance. Aucun signal indiquant que la seconde réponse est inventée.
Ce n’est pas un bug. C’est ainsi que fonctionnent les modèles de langage. Ils sont entraînés à produire du texte fluide et assuré — pas à vous dire quand ils devinent. Des recherches portant sur cinq LLM majeurs montrent qu’ils surestiment la probabilité que leurs réponses soient correctes de 20 à 60 pour cent. Plus la question est difficile, plus la calibration se détériore.
Pour un fiscaliste, cette confiance uniforme est la propriété la plus dangereuse des outils IA. Cela signifie que le système traite une réponse bien étayée — soutenue par trois arrêts de la Cour de cassation et une disposition légale claire — de manière identique à une réponse qu’il a inventée à partir de motifs dans ses données d’entraînement. Vous n’obtenez aucun signal. Vous ne pouvez pas faire la différence sans vérifier chaque réponse vous-même.
Le scoring de confiance est la réponse architecturale à ce problème. Pas une solution — un signal.
Ce que le scoring de confiance mesure réellement
Un score de confiance est un indicateur numérique qui vous indique à quel point une réponse est bien étayée — non par la certitude interne du modèle (qui est peu fiable), mais par les preuves que le système a trouvées.
Dans un système bien conçu, la confiance a deux dimensions :
Couverture des sources — combien de sources pertinentes le système a-t-il trouvées ? A-t-il récupéré des dispositions légales, de la jurisprudence et des circulaires administratives ? Ou n’a-t-il trouvé qu’un seul document vaguement lié ?
Certitude du raisonnement — dans quelle mesure les sources récupérées soutiennent-elles clairement la conclusion ? Sont-elles d’accord ? En conflit ? Traitent-elles de la question exacte, ou seulement d’une question connexe ?
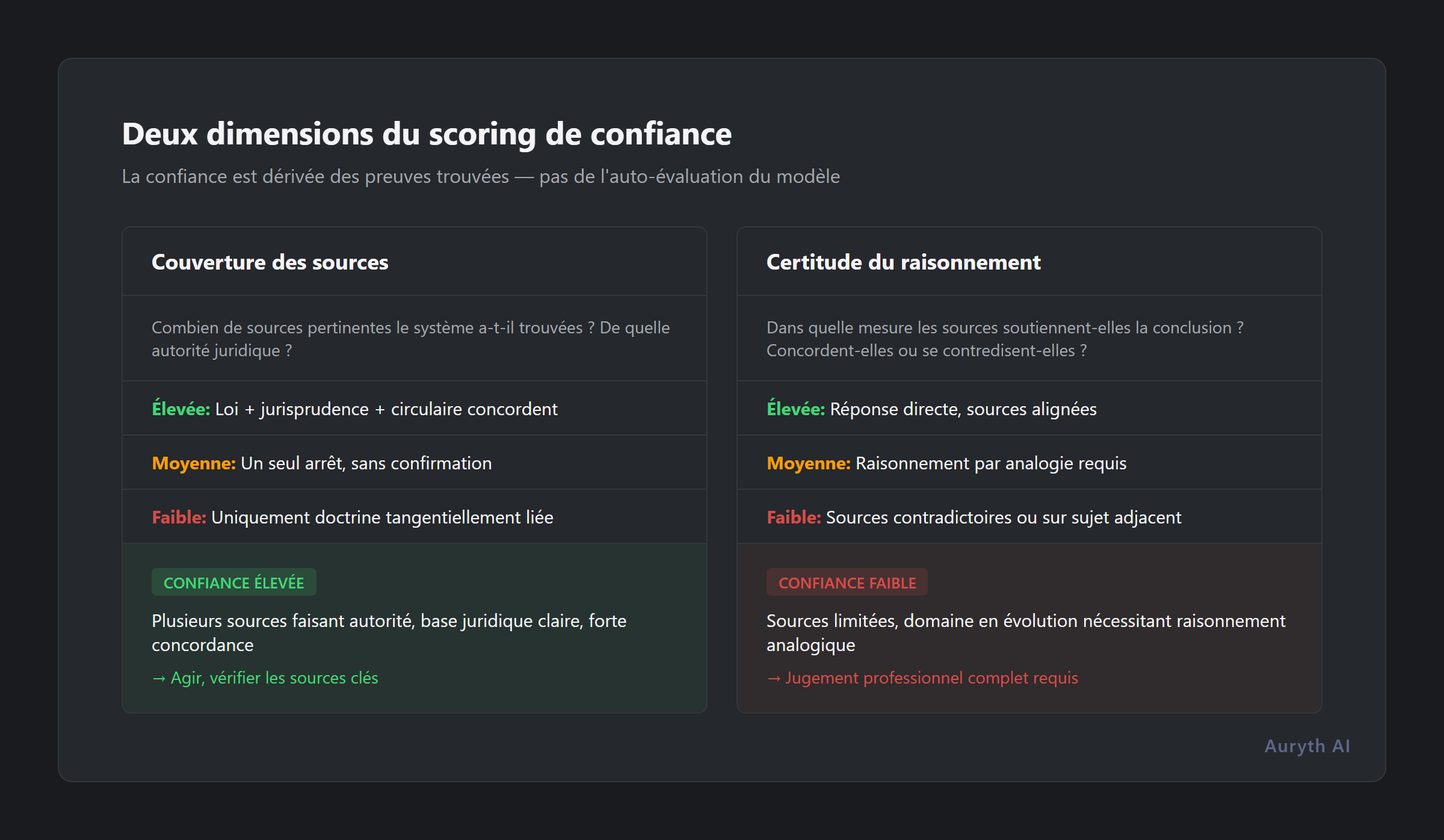
Une réponse à haute confiance ressemble à : « Sur la base de l’art. 21 CIR 92, confirmé par l’arrêt de la Cour de cassation du 12 mars 2024 et cohérent avec la circulaire Fisconetplus 2025/C/71, le taux de précompte mobilier sur dividendes est de 30 %. » Plusieurs sources faisant autorité. Base juridique claire. Accord fort.
Une réponse à faible confiance ressemble à : « Sur la base d’une décision anticipée du SDA de 2022, cette structure pourrait être éligible au régime de participation, bien qu’aucune jurisprudence n’ait été trouvée traitant de cette configuration spécifique. » Source unique. Aucune confirmation. Raisonnement analogique.
Les deux réponses pourraient être correctes. Mais elles exigent des niveaux très différents d’examen professionnel. Sans signal de confiance, elles semblent identiques.
Pourquoi les LLM sont systématiquement surconfiants
Le problème de surconfiance n’est pas une limitation qui sera corrigée dans la prochaine version du modèle. C’est structurel.
Les modèles de langage sont entraînés par apprentissage par renforcement à partir de retours humains (RLHF), où des évaluateurs humains notent la qualité des réponses. Les réponses confiantes et bien structurées reçoivent systématiquement des notes plus élevées que les réponses prudentes et incertaines — même lorsque les deux sont également exactes. Le processus d’entraînement enseigne littéralement aux modèles que la confiance est récompensée.
La recherche montre que les modèles de récompense utilisés dans le RLHF présentent des biais inhérents vers des scores de confiance élevés, indépendamment de la qualité réelle de la réponse. Le modèle apprend : paraître certain obtient de meilleurs scores. Il paraît donc certain — qu’il le doive ou non.
Les chiffres de calibration le confirment. Les erreurs de calibration attendues (Expected Calibration Errors) à travers les LLM testés vont de 0,108 à 0,427 — ce qui signifie que l’écart entre la confiance déclarée et l’exactitude réelle est substantiel. Les modèles plus grands se calibrent légèrement mieux, mais même les meilleurs modèles restent significativement surconfiants sur les tâches nécessitant une expertise de domaine.
Lorsqu’un système IA dit « J’en suis sûr », cette déclaration ne vous dit rien sur l’exactitude. Elle vous dit quelque chose sur les incitations à l’entraînement.
Ce que coûte la confiance uniforme en pratique
Considérez un fiscaliste belge posant deux questions :
Question A : « Quel est le taux d’impôt des sociétés standard pour les PME en Belgique ? »
Question B : « Un résident belge qui transfère des cryptomonnaies vers une plateforme d’échange étrangère et les convertit ensuite en stablecoins peut-il invoquer l’exemption pour ‘gestion normale du patrimoine privé’ en vertu de l’art. 90 CIR 92 ? »
Un LLM généraliste répond aux deux avec le même ton autoritaire. Même formatage. Même certitude. Mais la question A a une réponse simple et bien documentée (20 % sur les premiers 100 000 € pour les PME éligibles en vertu de l’art. 215 CIR 92). La question B se situe à l’intersection d’une politique fiscale en évolution rapide, d’une jurisprudence limitée et de positions administratives qui varient selon la période d’imposition.
Sans scoring de confiance, le professionnel doit effectuer le même niveau de vérification sur les deux réponses. Avec le scoring de confiance, le système signale la question A comme étant à haute confiance (plusieurs autorités claires) et la question B comme étant à faible confiance (autorités limitées, domaine politique évolutif, raisonnement analogique requis). Le professionnel peut allouer son examen là où cela compte.
Cette allocation n’est pas de la paresse — c’est la définition d’une pratique professionnelle efficace.
La différence entre confiance du modèle et confiance des preuves
Voici une distinction que la plupart des explications sur l’IA manquent : il existe deux types entièrement différents de « confiance » dans les systèmes IA, et un seul d’entre eux est utile.
La confiance du modèle est la probabilité que le modèle de langage attribue à ses propres tokens de sortie. C’est ce qui est disponible en interne dans tout LLM. La recherche montre qu’elle est mal calibrée et systématiquement surconfiante. Elle vous indique à quel point les choix de mots du modèle sont « attendus » — pas si la réponse est correcte.
La confiance des preuves est dérivée du pipeline de récupération — combien de sources ont été trouvées, quelle est leur autorité, dans quelle mesure elles traitent directement de la question, et si elles sont d’accord. C’est externe au modèle. Elle est basée sur des faits vérifiables concernant ce que le système a trouvé, pas sur l’auto-évaluation du modèle.
Un système de scoring de confiance utile utilise la confiance des preuves, pas la confiance du modèle. Le score devrait vous dire : « Nous avons trouvé trois dispositions légales, deux arrêts et une circulaire qui traitent directement de votre question, et ils sont d’accord » — pas « le modèle est sûr à 87 % de ses choix de mots ».
Ce que le scoring de confiance ne peut pas faire
L’honnêteté intellectuelle exige de reconnaître les limites :
Il ne peut pas détecter les inconnues inconnues. Si la disposition pertinente n’est pas dans le corpus, le système peut renvoyer une réponse plausible à partir de sources adjacentes — avec une confiance modérée. Le score de confiance reflète ce qui a été trouvé, pas ce qui existe.
Certaines incertitudes résistent à la quantification. Un article récent dans le journal de la Royal Statistical Society fait directement ce point : « De nombreuses formes conséquentes d’incertitude dans les contextes professionnels résistent à la quantification. » La question de savoir si une structure fiscale se qualifie comme « gestion normale du patrimoine privé » n’est pas un problème de score de confiance — c’est un problème de jugement professionnel. Le système peut vous montrer les sources. L’interprétation vous appartient.
Les scores de confiance peuvent créer une fausse précision. Un score de 0,73 vs 0,71 est un bruit insignifiant. Ce qui compte, c’est le signal catégorique : haute confiance (preuves solides, agissez), confiance modérée (quelques preuves, vérifiez les sources clés), faible confiance (preuves minces, cela nécessite votre plein jugement professionnel).
La bonne conception évite la fausse précision en communiquant par bandes, pas par décimales.
Articles connexes
- Pourquoi la transparence compte plus que l’exactitude dans l’IA juridique
- Hallucinations IA : pourquoi ChatGPT invente des sources (et comment le repérer)
- Comment évaluer un outil d’IA juridique : 10 questions qui comptent vraiment
Comment Auryth TX applique ceci
Chaque réponse dans Auryth TX comporte un score de confiance — non dérivé de l’auto-évaluation du modèle, mais du pipeline de récupération.
Le score reflète trois dimensions de preuve : nombre et autorité des sources (combien de sources pertinentes, et quel est leur poids juridique), pertinence directe (les sources traitent-elles de votre question exacte ou seulement d’une question connexe), et consensus (les sources sont-elles d’accord, ou existe-t-il un conflit nécessitant une interprétation professionnelle).
Lorsque la confiance est élevée, vous voyez la réponse avec ses sources de soutien et pouvez procéder efficacement. Lorsque la confiance est faible, le système vous le dit explicitement — et vous montre ce qu’il a trouvé, ce qu’il a cherché et n’a pas trouvé (récupération négative), et où se situent les lacunes en autorité.
Nous ne prétendons pas que chaque réponse est également fiable. Nous vous donnons le signal dont vous avez besoin pour allouer votre jugement professionnel là où cela compte le plus.
Sources : 1. Cash, T.N. et al. (2025). « Quantifying uncert-AI-nty: Testing the accuracy of LLMs’ confidence judgments. » Memory & Cognition. 2. Leng, J. et al. (2025). « Taming Overconfidence in LLMs: Reward Calibration in RLHF. » ICLR 2025. 3. Steyvers, M. et al. (2025). « What Large Language Models Know and What People Think They Know. » Nature Machine Intelligence. 4. Delacroix, S. et al. (2025). « Beyond Quantification: Navigating Uncertainty in Professional AI Systems. » RSS: Data Science and Artificial Intelligence.