5 Belgische fiscale vragen waar generieke AI gegarandeerd faalt
Dit zijn geen strikvragen. Het zijn routinevragen die elke fiscalist tegenkomt. Maar ze leggen vijf architecturale blinde vlekken bloot die geen enkel generiek AI-model met een betere prompt kan oplossen.
Door Auryth Team
We hebben ChatGPT, Copilot en Gemini getest op vijf Belgische fiscale vragen die elke professional tijdens een gewone werkdag zou kunnen stellen. Geen randgevallen. Geen strikvragen. Het soort vragen dat u zou afvuren tijdens de evaluatie van een cliëntendossier.
Alle vijf produceerden zelfverzekerde, goed gestructureerde antwoorden. Alle vijf waren fout — of gevaarlijk onvolledig. En de fouten waren niet willekeurig. Elke fout legt een andere architecturale beperking bloot die geen enkele prompt engineering kan oplossen.
Als u generieke AI gebruikt voor fiscaal onderzoek, zijn dit de vragen die u moet begrijpen. Niet omdat het de enige fouten zijn — maar omdat ze de vijf structurele categorieën van fouten vertegenwoordigen die zich herhalen bij elke vraag.
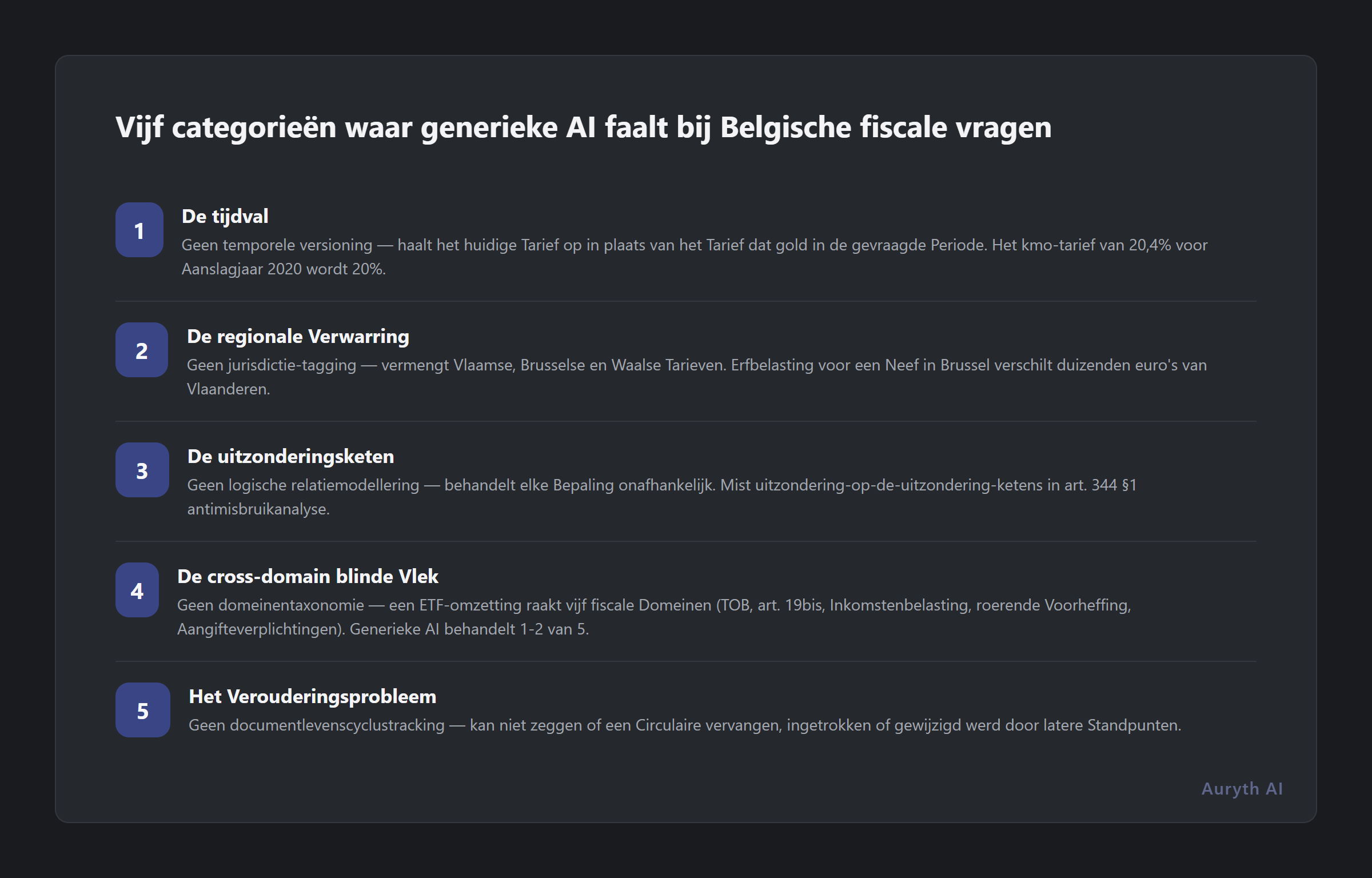
1. De tijdval
De vraag: “Wat was het Belgische vennootschapsbelastingtarief voor kmo’s met belastbare winst tot €100.000 in aanslagjaar 2020?”
Wat generieke AI zegt: “Het kmo-tarief is 20% op de eerste €100.000 belastbare winst volgens art. 215, lid 2 WIB 92.” Zelfverzekerd. Duidelijk. Fout voor de gevraagde periode.
Wat er werkelijk gebeurde: Het verlaagde kmo-tarief was 20,4% voor aanslagjaar 2020 (inkomstenjaar 2019), als onderdeel van de overgangstarieven tijdens de vennootschapsbelastinghervorming. Het tarief van 20% geldt pas vanaf aanslagjaar 2021. De AI haalt het huidige tarief op en projecteert het achterwaarts — omdat het geen concept heeft van temporele versioning.
Waarom dit architecturaal faalt: Generieke AI-modellen hebben één momentopname van kennis. Ze behouden geen temporele versies van wettelijke bepalingen. Wanneer u naar een historische periode vraagt, heeft het model geen mechanisme om de wet op te halen zoals die destijds was. Het geeft u wat het zich “herinnert” — wat meestal de meest recente versie is waarop het getraind werd.
Wat het u kost: Een incorrect tarief in een belastingaangifte leidt op zijn best tot een administratieve correctie, op zijn slechtst tot een boete. Voor een professional is het ook een reputatierisico — het soort fout dat cliënten aan uw aandacht voor detail doet twijfelen.
2. De regionale verwarring
De vraag: “Wat is het erfbelastingtarief in Brussel voor een erfenis van €300.000 ontvangen door een neef?”
Wat generieke AI zegt: Het produceert doorgaans een tarieventabel — maar vermengt Vlaamse en Brusselse tarieven, of geeft enkel de tarieven van één regio zonder te specificeren welke. Verschillende modellen die we testten gaven het Vlaamse tariefschema (dat verschillende schijven en drempels gebruikt) terwijl ze beweerden over Brussel te antwoorden.
Wat er werkelijk gebeurde: Brussel past zijn eigen tariefschema toe voor de categorie “tussen broers en zussen” en “tussen ooms/tantes en neven/nichten”, met andere schijven dan Vlaanderen of Wallonië. Het tarief voor een neef op €300.000 in Brussel verschilt enkele duizenden euro’s van dat in Vlaanderen.
Waarom dit architecturaal faalt: België heeft drie fiscale gewesten met uiteenlopende erfbelastingregimes. Generieke AI behandelt België als één jurisdictie — of erger, pikt bepalingen uit de eerste bron die zijn vector search vindt. Het heeft geen jurisdictie-tagging op zijn trainingsdata en geen mechanisme om Vlaamse, Brusselse en Waalse regels te onderscheiden wanneer ze vergelijkbare terminologie gebruiken.
Wat het u kost: Een Brusselse cliënt adviseren op basis van Vlaamse tarieven is niet gewoon onnauwkeurig — het is adviseren onder een volledig verkeerd juridisch kader. De cliënt vertrouwt op uw cijfer. Als het fout is, is de aansprakelijkheid de uwe.
3. De uitzonderingsketen
De vraag: “Is er een uitzondering op de algemene antimisbruikbepaling van art. 344 §1 WIB 92 voor verrichtingen die specifiek goedgekeurd zijn door een voorafgaande beslissing?”
Wat generieke AI zegt: De meeste modellen erkennen art. 344 en beschrijven de algemene antimisbruikregel, maar missen de kritieke nuance: de relatie tussen art. 344 §1 (algemeen antimisbruik), specifieke antimisbruikbepalingen (zoals art. 344 §2), en de rol van voorafgaande beslissingen (DVB) in het bieden van rechtszekerheid over specifieke verrichtingen.
Wat er werkelijk gebeurde: De interactie tussen art. 344 §1 WIB 92, de specifieke antimisbruikbepalingen en de Dienst Voorafgaande Beslissingen (DVB) omvat een uitzondering-op-de-uitzondering-keten. Een DVB-voorafgaande beslissing over een specifieke verrichting immuniseert die niet automatisch tegen art. 344 §1 — maar de analyse hangt af van of de beslissing specifiek de antimisbruikvraag behandelde en van de gepresenteerde materiële feiten.
Waarom dit architecturaal faalt: Juridische redenering omvat vaak ketens van uitzonderingen, waarbij bepaling A uitzondering B heeft, die zelf uitzondering C heeft. Generieke AI behandelt elke bepaling als een onafhankelijk tekstfragment. Het modelleert niet de logische relaties ertussen — de “behalve wanneer” en “niettegenstaande” en “onverminderd” ketens die definiëren hoe bepalingen werkelijk interageren.
Wat het u kost: Antimisbruikanalyse behoort tot het fiscale werk met de hoogste inzet. Een onvolledige analyse die een uitzondering mist — of een uitzondering op een uitzondering — kan het verschil betekenen tussen een structuur die een controle doorstaat en een die dat niet doet.
4. De cross-domain blinde vlek
De vraag: “Wat zijn alle fiscale implicaties voor een Belgische ingezetene die een distribuerende ETF omzet in een kapitaliserende ETF?”
Wat generieke AI zegt: Het behandelt doorgaans de TOB-implicaties (taks op beursverrichtingen) — soms correct — maar mist de meeste andere domeinen. De antwoorden die we ontvingen behandelden 1-2 van de 5 relevante fiscale domeinen.
Wat er werkelijk gebeurde: Deze verrichting raakt minstens vijf afzonderlijke fiscale domeinen:
- TOB — transactietaks op de verkoop van het distribuerende fonds en aankoop van het kapitaliserende fonds
- Art. 19bis WIB 92 — belasting op het “interestbestanddeel” bij uitstap uit een schuldfonds indien >10% in schuldinstrumenten
- Inkomstenbelasting — behandeling van eventuele gerealiseerde meerwaarde (gewone vs. speculatie vs. beroepsmatige)
- Roerende voorheffing — behandeling van eventueel aangegroeid dividend op het moment van omzetting
- Aangifteverplichtingen — aangifte buitenlandse rekeningen indien het kapitaliserende fonds in het buitenland aangehouden wordt
Waarom dit architecturaal faalt: Generieke AI verwerkt uw vraag als één enkele query tegen een platte tekstindex. Het heeft geen concept van fiscale domeingrenzen. Het kan niet systematisch traverseren van TOB naar inkomstenbelasting naar roerende voorheffing naar aangifteverplichtingen — omdat zijn retrievalmechanisme niet weet dat deze domeinen bestaan als afzonderlijke, onderling gerelateerde gebieden. Doelgebouwde systemen met domeinentaxonomie kunnen multi-domain retrieval triggeren en aangeven welke domeinen behandeld werden en welke niet.
Wat het u kost: Een cliënt adviseren over een fondsomzetting terwijl drie van de vijf fiscale implicaties gemist worden, is geen gedeeltelijk advies — het is advies dat een vals gevoel van volledigheid creëert. De cliënt veronderstelt dat u alles behandeld hebt. U veronderstelde dat de AI alles behandeld heeft. Niemand controleerde.
5. Het verouderingsprobleem
De vraag: “Is de Fisconetplus-circulaire van 15 maart 2023 over de fiscale behandeling van cryptocurrency staking rewards nog van kracht?”
Wat generieke AI zegt: Modellen getraind vóór een bepaalde datum zullen ofwel bevestigen dat de circulaire bestaat, ofwel er een fabriceren. Geen enkele kan u vertellen of die vervangen, ingetrokken of gewijzigd werd door latere administratieve standpunten.
Wat er werkelijk gebeurde: Administratieve circulaires en richtlijnen evolueren. Ze worden vervangen door nieuwe circulaires, gewijzigd door gerechtelijke beslissingen, of gedeeltelijk achterhaald door wetgevende wijzigingen. Een circulaire uit 2023 kan al dan niet het huidige administratieve standpunt in 2026 weerspiegelen — en de enige manier om dat te weten is te controleren of latere standpunten uitgevaardigd werden.
Waarom dit architecturaal faalt: Generieke AI heeft geen concept van documentlevenscyclus. Het volgt niet op welke circulaires vervangen werden, welke rulings vernietigd werden, of welke bepalingen gewijzigd werden. Zijn kennis is een momentopname — en het kan u niet vertellen waar die momentopname verouderd is. Doelgebouwde systemen met temporele metadata en vervangingstracking kunnen aangeven wanneer een bron mogelijk niet langer het huidige recht weerspiegelt.
Wat het u kost: Adviseren op basis van een vervangen circulaire is adviseren op basis van recht dat niet langer bestaat. De beroepsaansprakelijkheidsimplicaties zijn duidelijk.
Het patroon
Deze vijf fouten zijn geen bugs die opgelost zullen worden in GPT-6 of de volgende modelrelease. Het zijn structurele gevolgen van hoe generieke AI tekst verwerkt:
- Geen temporele versioning → foute historische antwoorden
- Geen jurisdictie-tagging → regionale verwarring
- Geen logische relatiemodellering → gebroken uitzonderingsketens
- Geen domeinentaxonomie → onvolledige cross-domain dekking
- Geen documentlevenscyclustracking → vertrouwen op verouderde bronnen
Elke fout correspondeert met een architecturaal vermogen dat generieke modellen niet hebben — en niet kunnen ontwikkelen door enkel betere training. Deze vereisen doelgebouwde zoekinfrastructuur, gestructureerde juridische corpora en domeinspecifieke retrievalpipelines.
De vraag is niet of generieke AI “beter wordt.” Dat doet het. De vraag is of de architectuur professioneel fiscaal werk kan ondersteunen. Deze vijf tests zeggen nee.
Gerelateerde artikels
- Ik stelde ChatGPT en Auryth dezelfde Belgische fiscale vragen — dit gebeurde er
- AI-hallucinaties: waarom ChatGPT bronnen fabriceert (en hoe u het herkent)
- Wat is RAG — en waarom het op zichzelf niet genoeg is voor juridische AI
Hoe Auryth TX deze vijf vragen behandelt
Deze vijf foutcategorieën zijn precies wat Auryth TX’s search-RAG fusion architectuur werd gebouwd om aan te pakken:
-
Temporeel — Elke bepaling in ons corpus draagt temporele metadata. Wanneer u naar aanslagjaar 2020 vraagt, haalt het systeem de versie van de wet op die in die periode gold — niet de versie van vandaag.
-
Regionaal — Jurisdictie-tags op elk document. Een Brusselse erfenisvraag haalt Brusselse tarieven uit het Brusselse belastingwetboek op. Vlaamse bepalingen worden uitgesloten tenzij u expliciet om een vergelijking vraagt.
-
Uitzonderingsketens — Cross-reference mapping tussen bepalingen. Wanneer art. 344 §1 opgehaald wordt, haalt het systeem ook de bepalingen op die het wijzigen, beperken of uitbreiden — en presenteert de relatiestructuur.
-
Cross-domain — Domeinentaxonomie triggert multi-domain retrieval. Een ETF-omzettingsvraag traverseert systematisch TOB, inkomstenbelasting, roerende voorheffing, art. 19bis en aangifteverplichtingen — en geeft aan welke domeinen behandeld werden.
-
Veroudering — Vervangingstracking en temporele validatie. Wanneer u naar een circulaire uit 2023 vraagt, controleert het systeem of latere administratieve standpunten uitgevaardigd werden.
Dit zijn geen features die we bovenop een chatbot toevoegden. Ze zijn de architecturale basis van het systeem.
Test deze vijf vragen zelf — sluit u aan bij de wachtlijst →
Bronnen: 1. Wetboek Inkomstenbelastingen (WIB 92), art. 215, art. 344, art. 19bis. 2. Wetboek Successierechten Brussels Hoofdstedelijk Gewest, art. 48-54. 3. Magesh, V. et al. (2025). “Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools.” Journal of Empirical Legal Studies.