Fine-tuning vs. RAG: twee manieren om AI slim te maken — en waarom het ertoe doet welke uw tool koos
Fine-tuning memoriseert de wet van gisteren. RAG zoekt die van vandaag op. Voor Belgische fiscalisten bepaalt deze architectuurkeuze of uw AI-tool actueel is of met vertrouwen verouderd.
Door Auryth Team
Harvey, het best gefinancierde juridische AI-bedrijf ter wereld, haalde meer dan een miljard dollar op en bouwde zijn systeem op fine-tuning — een model trainen op juridische data tot de kennis in de gewichten gebakken zit. Als u AI-tools evalueert voor fiscaal onderzoek, zult u deze aanpak tegenkomen. U zult ook RAG tegenkomen, retrieval-augmented generation, waarbij het model informatie opzoekt in een samengestelde kennisbank in plaats van die uit het geheugen op te dreunen.
Dit zijn geen technische details. Het zijn architectuurbeslissingen die bepalen of uw AI-tool zijn bronnen kan tonen, actueel blijft wanneer de wet verandert, en u kan vertellen wanneer het iets niet weet. Voor een Belgische fiscalist doet dat verschil er meer toe dan welke nauwkeurigheidsbenchmark dan ook.
Wat fine-tuning eigenlijk doet
Fine-tuning neemt een voorgetraind taalmodel en traint het opnieuw op domeinspecifieke data — arresten, wetboeken, juridisch commentaar — tot het model die kennis “absorbeert” in zijn parameters. Zie het als het memoriseren van een zeer dik, zeer duur handboek.
Het resultaat: het model spreekt de taal van het recht vloeiender. Het herkent juridische terminologie, begrijpt redeneringspatronen en produceert output die juristen verkiezen. Harvey’s samenwerking met OpenAI leverde een op maat getraind rechtspraakmodel op waarbij juristen in 97% van de gevallen de voorkeur gaven aan de output boven het basismodel.
Maar de kennis is bevroren op het moment van training. Bijwerken betekent opnieuw trainen — een proces dat tienduizenden per iteratie kost en weken tot maanden duurt. Toen de Belgische programmawet van juli 2025 het investeringsaftrekregime wijzigde, wist een model dat in maart 2025 was getraind daar niets van.
Wat RAG eigenlijk doet
Retrieval-Augmented Generation verandert het model niet. In plaats daarvan geeft het het model toegang tot een doorzoekbare kennisbank. Wanneer u een vraag stelt, doorzoekt het systeem eerst het corpus, haalt relevante documenten op, en stuurt die documenten — samen met uw vraag — naar het model voor antwoordgeneratie.
Zie het als het verschil tussen een collega die uit het geheugen antwoordt en een die eerst naar de bibliotheek loopt. De technische details — hybride zoeken, autoriteitrangschikking, cross-encoder reranking — behandelden we in ons artikel over zoek-RAG-fusie.
Het cruciale voordeel: wanneer de wet verandert, werkt u het corpus bij. Het model hoeft niet opnieuw getraind te worden. En omdat elk antwoord wordt gegenereerd op basis van opgehaalde documenten, kan elke bewering worden herleid tot een specifieke bron.
De vergelijking die ertoe doet
Het internet staat vol met fine-tuning vs. RAG vergelijkingen. De meeste focussen op nauwkeurigheid en kosten. Die doen ertoe, maar voor juridische professionals zijn ze niet de doorslaggevende factoren. Dit is wat daadwerkelijk bepaalt welke architectuur professioneel fiscaal werk dient:
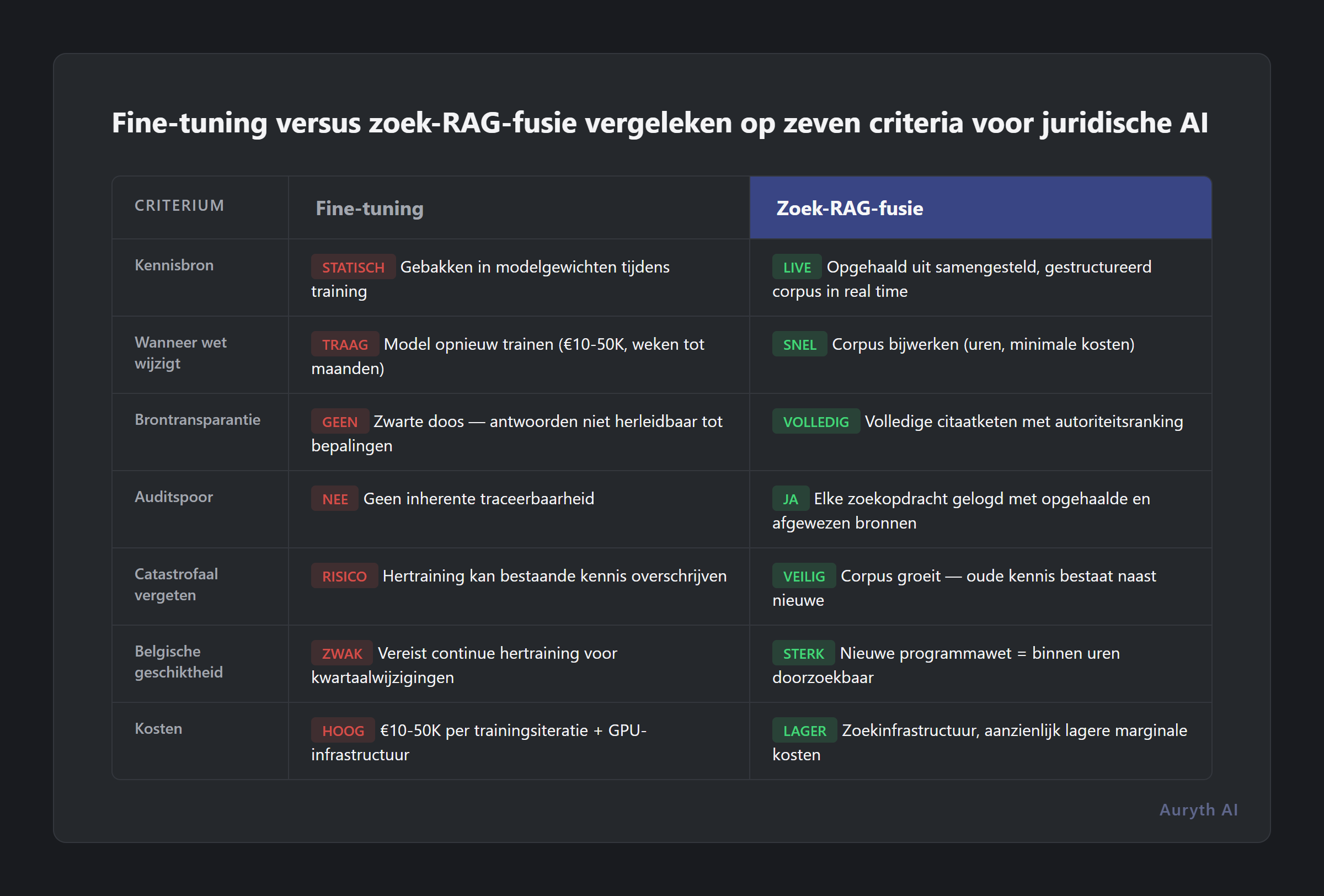
| Criterium | Fine-tuning | Zoek-RAG-fusie |
|---|---|---|
| Kennisbron | Gebakken in modelgewichten tijdens training | Opgehaald uit samengesteld, gestructureerd corpus in real time |
| Wanneer de wet verandert | Model opnieuw trainen (€10–50k, weken tot maanden) | Corpus bijwerken (uren, minimale kosten) |
| Brontransparantie | Zwarte doos — antwoorden niet herleidbaar tot specifieke bepalingen | Volledige citatieketen met autoriteitrangschikking |
| Auditspoor | Geen inherente traceerbaarheid | Elke zoekopdracht gelogd met opgehaalde en afgewezen bronnen |
| Catastrofaal vergeten | Hertraining op nieuwe data kan bestaande kennis overschrijven | Corpus groeit — oude kennis bestaat naast nieuwe |
| Belgische geschiktheid | Vereist continue hertraining voor een rechtssysteem dat per kwartaal verandert | Nieuwe programmawet = binnen uren doorzoekbaar |
| Kosten om in te zetten | €10–50k per trainingsiteratie + GPU-infrastructuur | Zoekinfrastructuur, aanzienlijk lagere marginale kosten |
De transparantierij is degene die u moet doen stoppen. Een fine-tuned model dat u het juiste antwoord geeft maar niet kan tonen waarom — welk specifiek artikel, welk arrest, welke circulaire — plaatst u in dezelfde positie als een collega die zegt “vertrouw me, ik onthoud het.” Beroepsaansprakelijkheid vereist meer dan geheugen.
Waarom Harvey voor fine-tuning koos (en waarom dat hier niet opgaat)
Harvey’s keuze is logisch voor hun markt. Amerikaans en Brits recht — met name rechtspraak en contractredactie — is relatief stabiel. Hertrainingscycli van maanden zijn aanvaardbaar wanneer de wet niet per kwartaal verandert. Hun klantenbestand (grote kantoren die $500+/uur factureren) kan de enterprise-prijzen absorberen. En hun gebruikscasus (contractbeoordeling, documentredactie, juridische memo’s) profiteert van de vloeiendheidsvoordelen van fine-tuning.
Belgisch fiscaal recht is een ander beest. Twee grote programmawetten per jaar. Drie gewesten met uiteenlopende regels. Twee officiële talen met verschillende juridische terminologieën. Een hervormingscyclus die in 2025 alleen al een nieuwe meerwaardebelasting bracht, het expatregime overhoop haalde, de investeringsaftrek herstructureerde en de aanslagtermijnen herschreef.
Een model dat in januari 2025 is getraind, is in juli 2025 al verouderd. Dat is geen theoretische zorg. Het is de realiteit van de Belgische fiscale praktijk.
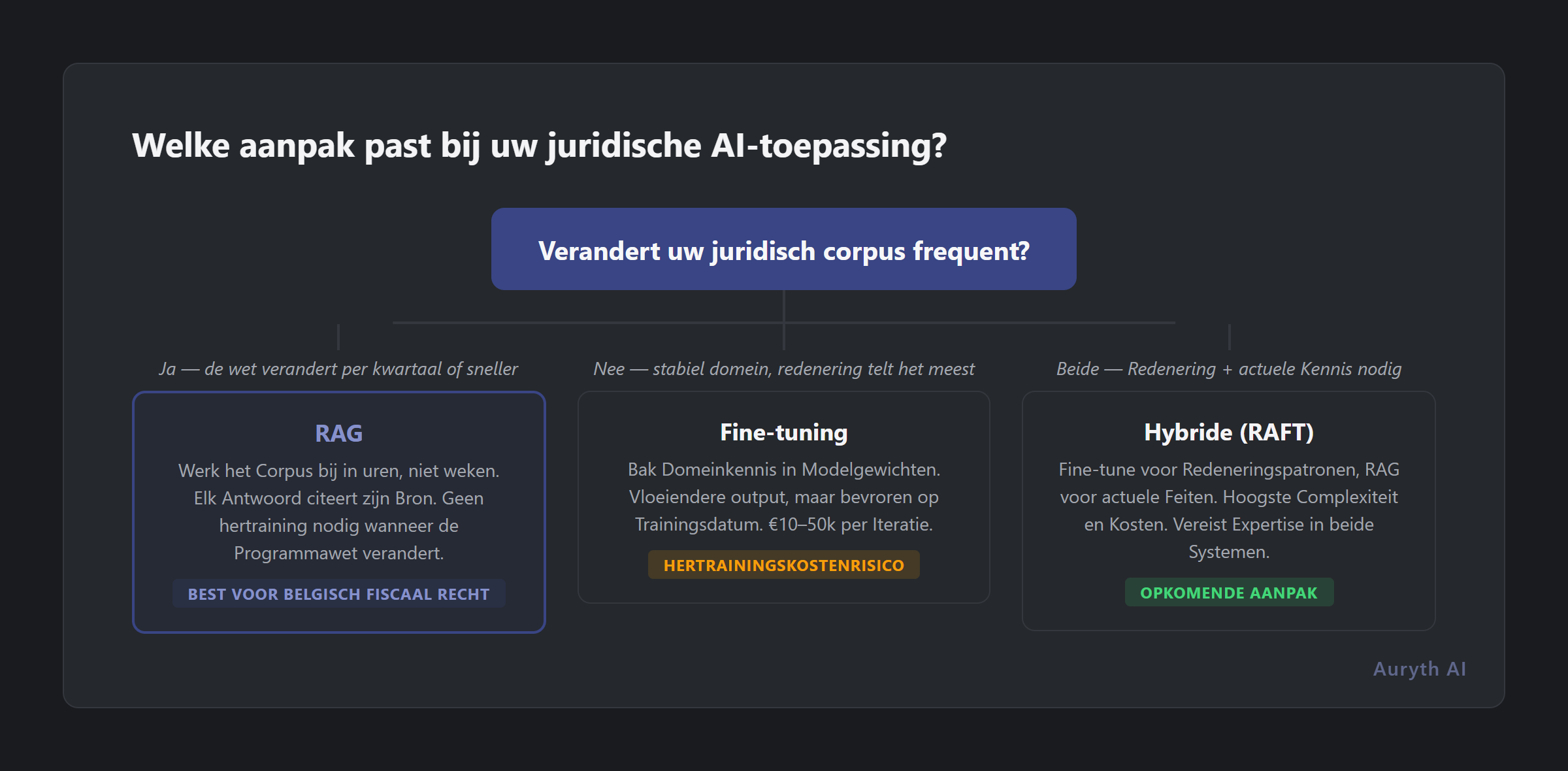
De versheidstest: als uw wet sneller verandert dan uw model hertrained, is fine-tuning de verkeerde architectuur.
Het hybride argument (en de beperkingen ervan)
Het eerlijke antwoord is dat de industrie evolueert richting hybride benaderingen — fine-tuning voor redeneringspatronen, RAG voor actuele kennis. Onderzoek noemt dit RAFT (Retrieval-Augmented Fine-Tuning). Het idee is goed: leer het model via fine-tuning om te redeneren als een jurist, en geef het dan actuele feiten via RAG.
Maar hybride benaderingen erven de complexiteit van beide systemen. U hebt expertise nodig in modeltraining én zoekinfrastructuur. U moet de kennis van het fine-tuned model gesynchroniseerd houden met het ophaalcorpus — als het model op oude regels is getraind maar het corpus nieuwe bevat, kan het resultaat incoherent zijn. En de kostensom verdubbelt.
Voor Belgische fiscale AI is de pragmatische keuze duidelijk: begin met uitstekende retrieval. Als fine-tuning meerwaarde biedt voor specifieke redeneringstaken, voeg het dan selectief toe. Maar retrieval-kwaliteit is het fundament — zonder dit kan zelfs het best getrainde model het specifieke artikel niet citeren dat uw vraag beantwoordt.
Waar RAG tekortschiet
Intellectuele eerlijkheid vereist dat we de echte beperkingen van RAG erkennen:
Retrievalkwaliteit is het plafond. Als het corpus het juiste document niet bevat, of de zoekpipeline het niet naar boven haalt, kan het model het niet gebruiken. Fine-tuned modellen kunnen soms naar analogie redeneren op manieren die pure RAG-systemen moeilijk vinden.
Minder vloeiend bij gespecialiseerde taken. Fine-tuned modellen produceren vaak meer gepolijste, domeinnative output. RAG-systemen genereren antwoorden uit opgehaalde context, wat minder “juridisch” kan aanvoelen in toon.
Pipelinecomplexiteit. Een vijfstaps zoek-RAG-fusiepipeline heeft meer bewegende delen dan een enkel fine-tuned modelaanroep. Meer componenten betekent meer potentiële foutpunten.
De afweging is reëel. Maar voor professioneel fiscaal onderzoek — waar verifieerbaarheid zwaarder weegt dan vloeiendheid, en actualiteit zwaarder dan afwerking — valt de afweging in het voordeel van retrieval uit.
Gerelateerde artikelen
- Wat is RAG — en waarom het alleen niet genoeg is voor juridische AI
- Waarom transparantie belangrijker is dan nauwkeurigheid in juridische AI
- AI-hallucinaties: waarom ChatGPT bronnen verzint (en hoe u dat herkent)
Hoe Auryth TX dit toepast
Auryth TX koos voor zoek-RAG-fusie — niet omdat fine-tuning slecht is, maar omdat Belgisch fiscaal recht een architectuur vereist die kan bijblijven.
Elke vraag doorloopt een vijfstapspipeline: hybride zoeken (BM25 + vector-embeddings), autoriteitrangschikking over de Belgische juridische hiërarchie, cross-encoder reranking, gestructureerde antwoordgeneratie met bronvermeldingen per claim, en citaatvalidatie na generatie. De kennisbank is het Belgisch juridisch corpus — WIB 92, VCF, Fisconetplus, DVB-rulings, arresten — allemaal gestructureerd met temporele metadata en jurisdictietags.
Toen de programmawet van juli 2025 het investeringsaftrekregime herstructureerde, weerspiegelde ons corpus de wijziging binnen uren. Een fine-tuned model zou hertraining nodig hebben. Het onze had een corpusupdate nodig.
Wij vragen u niet om het geheugen van het model te vertrouwen. Wij vragen u om de bronnen te controleren die het ophaalt. Dat is de architectuurbeslissing die dit mogelijk maakt.
Bekijk hoe onze pipeline echte Belgische fiscale vragen behandelt — schrijf u in op de wachtlijst →
Bronnen: 1. Harvey AI (2025). “Harvey Raises Series E.” Blogaankondiging. 2. Soudani, H., Kanoulas, E. & Hasibi, F. (2024). “Fine Tuning vs. Retrieval Augmented Generation for Less Popular Knowledge.” arXiv:2403.01432. 3. Magesh, V. et al. (2025). “Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools.” Journal of Empirical Legal Studies.