Waarom transparantie belangrijker is dan nauwkeurigheid in juridische AI
De AI-industrie is geobsedeerd door nauwkeurigheid. Voor fiscalisten is verifieerbaarheid de maatstaf die u écht beschermt.
Door Auryth Team
Een AI die 95% nauwkeurig is maar nooit zegt “ik weet het niet zeker” is gevaarlijker dan een AI die 90% nauwkeurig is maar altijd zijn bronnen toont.
Dat klinkt tegenstrijdig. De AI-industrie heeft ons jarenlang geleerd om één vraag te stellen: hoe nauwkeurig is uw tool? Hoger cijfer, betere tool, einde discussie. Maar als u een fiscaal adviseur bent die beroepsaansprakelijkheid draagt voor elk advies dat u geeft, is nauwkeurigheid zonder transparantie een val die u pas ziet als het te laat is.
De verkeerde maatstaf
Nauwkeurigheid is een eigenschap van het systeem. Verifieerbaarheid is een eigenschap van de output. Dat is niet hetzelfde.
Wanneer een AI-tool u vertelt dat het TOB-tarief op kapitaliserende fondsen 1,32% bedraagt, betekent nauwkeurigheid dat het antwoord correct is. Verifieerbaarheid betekent dat u kunt zien dat het antwoord terug te voeren is op een specifieke wettelijke bepaling, de bron zelf kunt raadplegen, en kunt bevestigen dat die bron zegt wat de tool beweert.
Een nauwkeurig antwoord dat u niet kunt verifiëren is een mening van een autoriteit die u niet kunt bevragen. Een verifieerbaar antwoord — zelfs als het af en toe fout is — is een vertrekpunt voor professioneel oordeel. U kunt de fout opmerken. U kunt de redenering beoordelen. U kunt uw beslissing verdedigen.
De AI-industrie meet dit niet. Leveranciers publiceren nauwkeurigheidsbenchmarks, geen verifieerbaarheidsscores. Dat komt omdat nauwkeurigheid vleiend is en verifieerbaarheid veeleisend.
Waarom AI zekerder klinkt dan het zou moeten
Moderne AI heeft een ontwerpfout die nauwkeurigheidsmetrieken bijzonder misleidend maakt: het is getraind om zelfverzekerd te klinken.
Grote taalmodellen ondergaan Reinforcement Learning from Human Feedback (RLHF), waarbij menselijke beoordelaars zelfverzekerde, goed gestructureerde antwoorden belonen en nuancering bestraffen. Het resultaat: AI-systemen zijn architecturaal bevooroordeeld richting zekerheid — zelfs wanneer het onderliggende bewijs dun of onbestaand is.
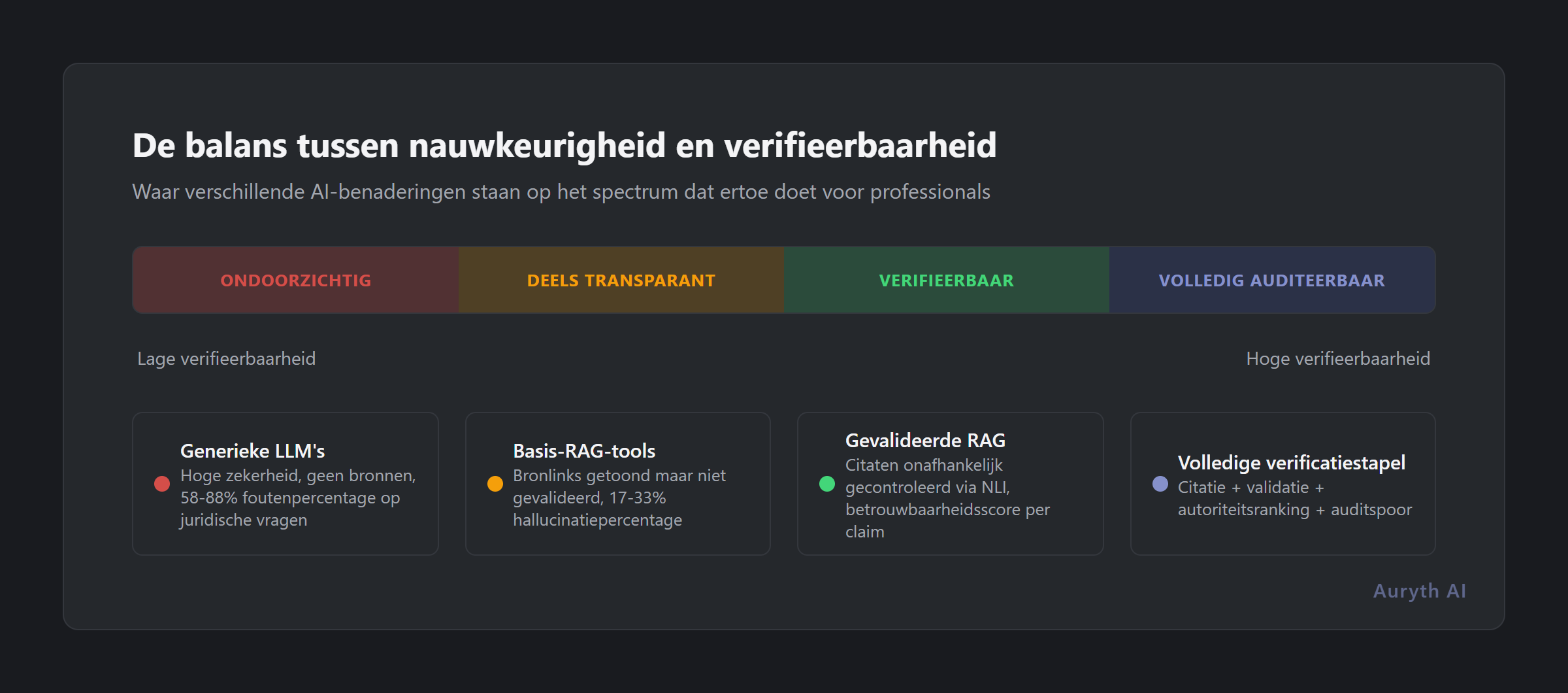
Stanford-onderzoekers ontdekten dat zelfs premium juridische RAG-tools hallucineren bij 17–33% van de vragen. Algemene LLM’s scoren nog slechter: 58–88% foutenpercentage op juridische vragen. Maar het gevaarlijke is niet het foutenpercentage zelf — het is dat de fouten er niet anders uitzien dan de correcte antwoorden. Een gefabriceerde bronvermelding leest precies als een echte. Een fout artikelnummer wordt met dezelfde zekerheid gesteld als het juiste.
Zonder brontransparantie kunt u de 67% die correct is niet onderscheiden van de 33% die het niet is.
Wat transparantie er in de praktijk uitziet
Transparantie in juridische AI is geen marketingvinkje. Het is een reeks specifieke technische beslissingen die veranderen hoe u de tool professioneel kunt inzetten:
| Eigenschap | Ondoorzichtige AI | Transparante AI |
|---|---|---|
| Bronvermeldingen | ”Op basis van Belgisch fiscaal recht" | "Art. 19bis WIB 92, zoals gewijzigd op 25 december 2017” met raadpleegbare bron |
| Vertrouwenssignaal | Elk antwoord met gelijke zekerheid | Betrouwbaarheidsscore per claim op basis van brondekking en overeenstemming |
| Dun bewijs | Antwoordt toch, vol vertrouwen | Signaleert expliciet: “Geen specifieke ruling gevonden over dit punt” |
| Tegenstrijdige bronnen | Kiest er één, presenteert als definitief | Toont beide kanten gerangschikt op juridisch gewicht |
| Auditspoor | Chatgeschiedenis | Gestructureerd logboek: vraag, opgehaalde bronnen, afgewezen bronnen, betrouwbaarheidsredenering |
| Onzekerheid | Nooit uitgedrukt | Expliciet gekwantificeerd — lage betrouwbaarheid activeert een waarschuwing |
Het verschil is niet cosmetisch. Het is het verschil tussen een tool die uw oordeel vervangt en een die het informeert.
De verificatiestapel: drie lagen van vertrouwen
Niet alle transparantie is gelijk. Een bronvermelding die u niet onafhankelijk kunt controleren is theater, geen transparantie. Professionele juridische AI heeft drie lagen nodig:
| Laag | Welke vraag het beantwoordt | Wat het vereist |
|---|---|---|
| 1. Citatietransparantie | Kan ik de bron zien? | Elke claim gekoppeld aan een raadpleegbaar document |
| 2. Citatievalidatie | Zegt de bron dit echt? | Onafhankelijke NLI-controle die de bewering van het model vergelijkt met de brontekst |
| 3. Autoriteitcontext | Hoe sterk is deze bron? | Rangschikking in de juridische hiërarchie — een arrest van het Hof van Cassatie weegt zwaarder dan een circulaire |
Haal een laag weg en de transparantieclaim valt in elkaar. Een bronvermelding tonen zonder validatie is citatiedecoratie — het oogt geloofwaardig zonder iets te bewijzen. Citaties valideren zonder autoriteitcontext behandelt een blogpost en een arrest van het Hof van Cassatie als gelijkwaardig bewijs.
De verificatiestapel: citatietransparantie zonder validatie is decoratie. Validatie zonder autoriteitcontext is democratie. U hebt alle drie nodig.
Waarom dit ertoe doet voor Belgische beroepsaansprakelijkheid
Belgische fiscaal adviseurs en accountants — of ze nu ingeschreven zijn bij het ITAA of onafhankelijk werken — dragen volledige beroepsaansprakelijkheid voor het advies dat ze aan cliënten geven. Geen enkele AI-tool verandert deze fundamentele verplichting. Een tool gebruiken die foutieve output produceerde is geen verweer; vertrouwen op een niet-verifieerbare tool zonder onafhankelijke verificatie kan onvoldoende zorgvuldigheid uitmaken.
De EU AI Act, met transparantie- en menselijk-toezichtvereisten die gefaseerd in werking treden in 2025–2026, voegt een regulatoire dimensie toe. Voor professionals die AI gebruiken in advieswerk is de praktische implicatie eenvoudig: de tools die u gebruikt moeten uw vermogen ondersteunen om hun output te verifiëren en te overzien. Een ondoorzichtig systeem maakt naleving moeilijker, niet makkelijker.
Uit een recent Thomson Reuters-onderzoek bleek dat 59% van de bedrijfsjuristen niet eens weet of hun externe advocaten generatieve AI gebruiken. Die informatieasymmetrie — AI-ondersteund advies zonder kennisgeving — is precies het soort ondoorzichtigheid dat de regulatoire trend wil elimineren.
De praktische vraag voor elke fiscalist die een AI-onderzoekstool evalueert is niet “hoe nauwkeurig is dit?” Het is: kan ik de output snel genoeg verifiëren dat de tool mij daadwerkelijk tijd bespaart?
Het tegenargument: doet nauwkeurigheid er dan niet toe?
Uiteraard wel. Niemand wil een transparante tool die de helft van de tijd fout is. Maar het debat gaat niet over nauwkeurigheid of transparantie — het gaat over het besef dat transparantie nauwkeurigheid bruikbaar maakt.
Een tool die 95% nauwkeurig is zonder verificatiepad betekent dat u elk antwoord onafhankelijk moet onderzoeken om de 5% te vinden die fout is — waarmee de tijdsbesparing verdwijnt. Een tool die 90% nauwkeurig is maar zijn bronnen toont, onzekerheid signaleert en rangschikt op autoriteit, betekent dat u de 90% snel kunt bevestigen en uw expertise kunt richten op de 10%.
De ironie: transparante tools lijken minder indrukwekkend omdat ze hun onzekerheid tonen. Ondoorzichtige tools maken meer indruk in demo’s omdat ze bij elk antwoord zelfvertrouwen uitstralen. Maar in de professionele praktijk is de tool die zegt “ik vond beperkte autoriteit op dit punt — hier zijn twee tegenstrijdige bronnen, gerangschikt op gewicht” oneindig nuttiger dan een die zegt “het antwoord is X” zonder mogelijkheid tot controle.
De gevaarlijkste AI is niet degene die soms fout is. Het is degene die u nooit vertelt wanneer dat het geval is.
Gerelateerde artikelen
- Wat is RAG — en waarom het alleen niet genoeg is voor juridische AI
- AI-hallucinaties: waarom ChatGPT bronnen verzint (en hoe u dat herkent)
- Confidence scoring: waarom het eerlijker is dan een zelfzeker antwoord
Hoe Auryth TX dit toepast
Auryth TX is gebouwd op het verifieerbaarheidsbeginsel — de overtuiging dat een transparante tool veiliger is dan een ondoorzichtige, ongeacht nauwkeurigheidsbenchmarks.
Elk antwoord bevat bronvermeldingen per claim, gekoppeld aan raadpleegbare documenten in het Belgisch juridisch corpus. Elke citatie wordt onafhankelijk gevalideerd: een Natural Language Inference-laag controleert of elke bron daadwerkelijk zegt wat het model eraan toeschrijft. Elke bron draagt een autoriteitsniveau — van grondwettelijke bepalingen via wetgeving, rechtspraak, circulaires tot doctrine — zodat u het gewicht van het bewijs kent, niet alleen het bestaan ervan.
Wanneer bewijs dun is, daalt de betrouwbaarheidsscore en vertelt u waarom. Wanneer bronnen tegenstrijdig zijn, worden beide kanten getoond met hun autoriteitrangschikking. Wanneer het systeem zoekt en niets relevants vindt, vertelt het u dat — omdat weten dat er geen autoriteit bestaat over een specifiek punt professionele intelligentie is, geen systeemfalen.
Wij publiceren onze nauwkeurigheidsmetrieken. Wij tonen onze bronnen. Wij signaleren onze onzekerheid. Niet omdat het ons beter doet lijken — dat doet het niet. Maar omdat vertrouwen zonder bewijs marketing is, en wij een onderzoekstool bouwen.
Bekijk onze aanpak van transparantie — schrijf u in op de wachtlijst →
Bronnen: 1. Magesh, V. et al. (2025). “Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools.” Journal of Empirical Legal Studies. 2. Thomson Reuters Institute (2024). “ChatGPT & Generative AI within Law Firms.” 3. Europees Parlement (2024). “Verordening (EU) 2024/1689 — De EU AI Act.”