Waarom we geen chatbot bouwen
Chatinterfaces ogen modern maar produceren vluchtige, onverdedigbare output. Professioneel fiscaal onderzoek vereist gestructureerde antwoorden die u kunt archiveren, reproduceren en verdedigen.
Door Auryth Team
Uw cliënt belt. Hij wil weten hoe u zes weken geleden tot dat advies over roerende voorheffing kwam. U opent uw AI-tool — en scrolt door een chatgeschiedenis die leest als een bewustzijnsstroom. Ergens tussen een btw-vraag en een thread over vennootschapsreorganisatie ligt de relevante uitwisseling begraven. Misschien. Als de sessie niet werd gewist.
Dit is geen randgeval. Dit is de standaardervaring van elke professional die een chatbot gebruikt voor serieus onderzoek.
Het chatbotparadigma heeft een structureel probleem
De hele juridische AI-industrie convergeerde naar chat. ChatGPT trainde honderden miljoenen gebruikers om een tekstvak en een conversatie te verwachten. Elke concurrent volgde. Het resultaat: professioneel fiscaal onderzoek gepropt in een interface ontworpen voor casual conversatie.
Het probleem is niet accuraatheid — hoewel dat ook telt. Het probleem is vluchtigheid. Chatconversaties zijn:
- Ongestructureerd. Het antwoord ligt verspreid over meerdere uitwisselingen, vermengd met uw vervolgvragen en de aarzeling van de AI
- Niet-reproduceerbaar. Stel dezelfde vraag morgen en krijg een ander antwoord — zonder manier om te vergelijken
- Niet-exporteerbaar. Probeer een chattranscript om te zetten in een cliëntnota. U zult alles van nul herschrijven
- Onverdedigbaar. Wanneer een collega, toezichthouder of cliënt vraagt “hoe kwam u tot deze conclusie?” — een chatlog is geen antwoord
Sinds midden 2023 werden wereldwijd honderden gevallen van AI-gegenereerde juridische hallucinaties gedocumenteerd, met meer dan 50 in juli 2025 alleen al met verzonnen citaties. De meesten betroffen professionals die chatoutput als onderzoek behandelden. Dat was het niet.
De verantwoordingstest
Voordat u op een AI-tool vertrouwt voor professioneel werk, stel drie vragen:
| Vraag | Chat AI | Onderzoeksplatform |
|---|---|---|
| Kan ik dit resultaat volgende week reproduceren? | Nee — andere sessie, ander antwoord | Ja — zelfde zoekvraag, zelfde gestructureerde output |
| Kan ik dit exporteren als cliëntproduct? | Een conversatietranscript kopiëren-plakken? | Gestructureerde output met citaten, klaar om te archiveren |
| Kan ik dit verdedigen bij betwisting? | ”De AI vertelde me in een chat” | Gedocumenteerd onderzoek met bronketen en betrouwbaarheidsindicatoren |
Als het antwoord op één van deze vragen nee is, doet u geen onderzoek. U voert een conversatie.
Wat u niet kunt reproduceren, kunt u niet verdedigen.
Waarom chat werkt — en waar het stopt
Om eerlijk te zijn: chatinterfaces zijn niet nutteloos. Ze werken goed voor taken met lage inzet waar verantwoording niet telt. Cliëntintake op een website, brainstormsessienotities, een eerste e-mail opstellen — chat is prima.
Het faalt wanneer de inzet stijgt. Wanneer een Belgische fiscalist vertrouwt op een AI-antwoord voor een rulingaanvraag bij de DVB (Dienst Voorafgaande Beslissingen), moet dat antwoord traceerbaar zijn naar specifieke wetsbronnen. Wanneer een accountant een standpunt voorbereidt voor een ITAA-collegiale toetsing, moet het onderzoek reproduceerbaar zijn. Wanneer een notaris een nalatenschap structureert, moet de analyse exporteerbaar zijn als formele nota.
Chat kan dit allemaal niet. Niet omdat het onderliggende model slecht is, maar omdat de interface structureel ongeschikt is om verdedigbaar werkproduct te produceren.
De Belgische regelgevingsrealiteit
De Orde van Vlaamse Balies (OVB) publiceerde gedetailleerde AI-richtlijnen die professionals verplichten hun AI-toolgebruik te documenteren, brontracering te handhaven en aan te tonen dat hun AI-ondersteund werk juridisch en ethisch deugdelijk is. De Belgische Gegevensbeschermingsautoriteit volgde in september 2024 met uitgebreide richtlijnen over AI-systemen en AVG-conformiteit.
De EU AI Act, volledig van toepassing vanaf augustus 2026, vereist automatische gestructureerde logging voor hoogrisico-AI-systemen onder artikel 12. Een chattranscript kwalificeert niet als gestructureerde logging.
Ondertussen reageren verzekeraars op AI-risico met nagenoeg absolute uitsluitingen. Beroepsaansprakelijkheidsverzekeringen sluiten steeds vaker dekking uit voor claims “op enigerlei wijze gerelateerd aan AI” — wat betekent dat als uw AI-ondersteund advies misgaat en uw documentatie een chatgeschiedenis is, uw verzekeraar de claim volledig kan afwijzen.
De regelgevingsrichting is duidelijk: controleerbaarheid is geen optie. Elke tool gebruikt in professionele praktijk moet output produceren die kan worden herzien, gereproduceerd en verdedigd. Chatarchitecturen werden hier nooit voor ontworpen.
Wat we in plaats daarvan bouwen: dossiervast onderzoek
Dossiervaste AI betekent dat elk antwoord dat het systeem produceert kan worden gearchiveerd, geëxporteerd en verdedigd als professioneel werkproduct. Geen conversatie. Een gestructureerd onderzoeksproduct.
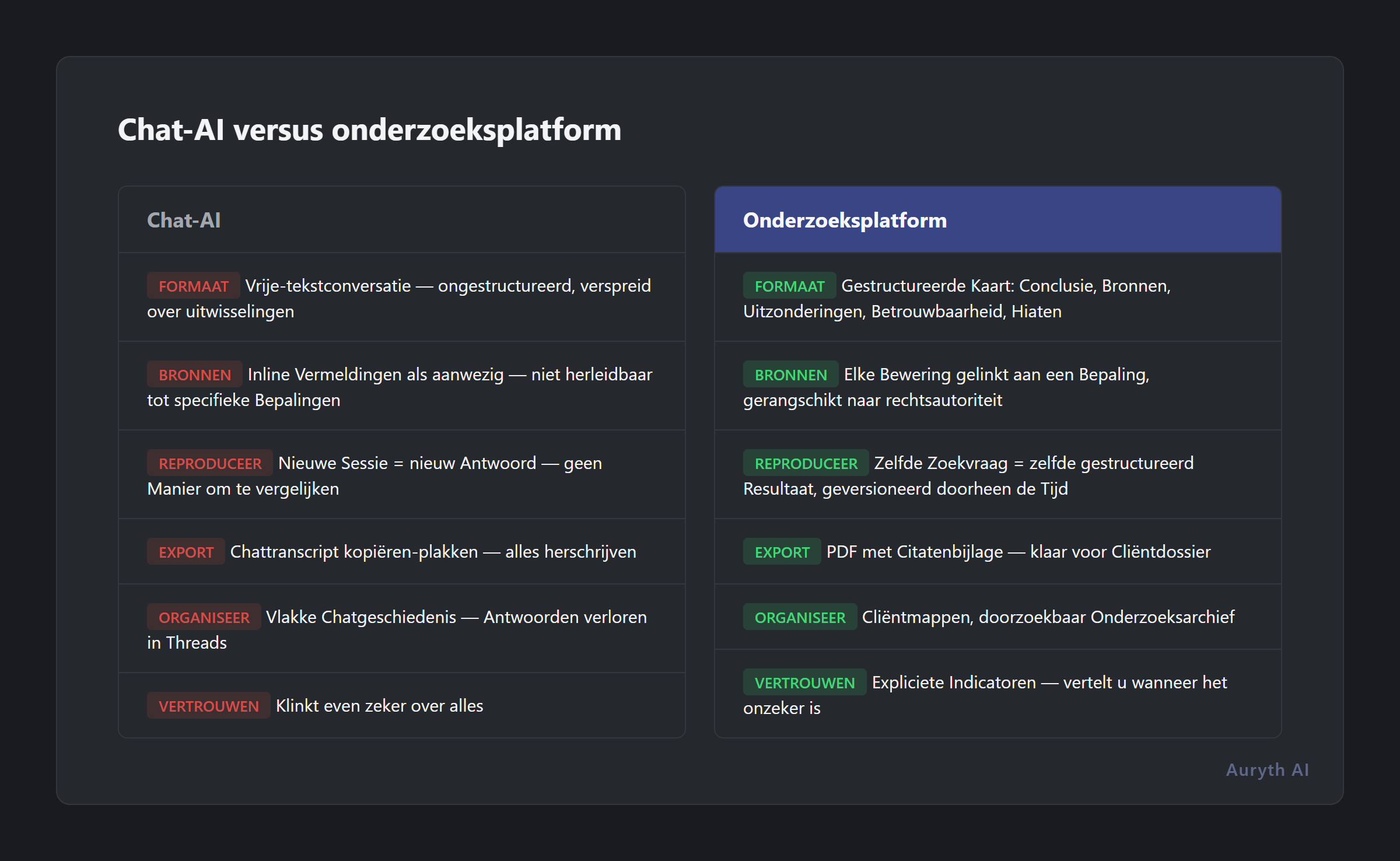
Het verschil is architecturaal, niet cosmetisch:
| Aspect | Chatparadigma | Dossiervast onderzoek |
|---|---|---|
| Outputformaat | Vrije-tekstconversatie | Gestructureerde kaart: conclusie, bronnen, uitzonderingen, betrouwbaarheid, hiaten |
| Bronketen | Inline vermeldingen, als aanwezig | Elke bewering gelinkt aan een specifieke bepaling, gerangschikt naar rechtsautoriteit |
| Reproduceerbaarheid | Nieuwe sessie = nieuw antwoord | Zelfde zoekvraag produceert zelfde gestructureerd resultaat, geversioneerd doorheen de tijd |
| Export | Kopiëren-plakken van chatlog | PDF met citatenbijlage, klaar voor cliëntdossier |
| Organisatie | Vlakke chatgeschiedenis | Cliëntmappen, doorzoekbaar onderzoeksarchief |
| Betrouwbaarheid | De AI klinkt even zeker over alles | Expliciete betrouwbaarheidsindicatoren — het systeem vertelt u wanneer het onzeker is |
Dit is geen functievoorkeur. Dit is het verschil tussen een tool die u helpt brainstormen en een tool die u helpt praktiseren.
De industrie weet al dat chat niet volstaat
De bepalende verschuiving in legal tech in 2025 was de beweging van chatbot-stijl AI naar agentische, ingebedde systemen. Thomson Reuters, LexisNexis en Harvey voegden allemaal agentische en workflow-geïntegreerde functies toe naast hun chatinterfaces op ILTACON 2025. Sectoranalisten voorspellen dat AI-systemen steeds meer gestructureerde interfaces zullen bieden in plaats van lege tekstvakken.
De vraag is niet of de sector voorbij chat gaat. Het is of uw kantoor beweegt vóór een beroepsaansprakelijkheidsincident de kwestie forceert.
Een aanzienlijk deel van de tijd in professionele dienstverlening wordt verspild aan het zoeken naar antwoorden verspreid over ongestructureerde kennissystemen. Chatgeschiedenissen maken dit erger, niet beter. Elke onbeantwoorde vraag over “wat zei de AI over dat dossier drie maanden geleden?” vertegenwoordigt institutionele kennis die werd gegenereerd en onmiddellijk verloren ging.
Gerelateerde artikelen
- Wat is autoriteitrangschikking — en waarom uw juridische AI-tool het waarschijnlijk negeert →
- Wat is betrouwbaarheidscoring — en waarom het eerlijker is dan een zeker antwoord →
- Hoe een juridische AI-tool evalueren: 10 vragen die echt tellen →
Hoe Auryth TX dit toepast
Elk antwoord dat Auryth TX produceert volgt dezelfde structuur: een duidelijke conclusie, een gerangschikte bronketen gewogen naar rechtsautoriteit, een uitzonderingenkaart die cross-domeinrisico’s markeert, betrouwbaarheidsindicatoren die tonen waar het systeem zeker is en waar niet, en expliciete hiaatdetectie die identificeert wat het systeem niet kon vinden.
De output is ontworpen voor uw cliëntdossier, niet uw chatgeschiedenis. Exporteer als PDF met volledige citatenbijlage. Organiseer onderzoek per cliënt, per dossier, per vraag. Keer maanden later terug naar een zoekvraag en krijg hetzelfde gestructureerde resultaat — bijgewerkt als de onderliggende wetgeving is gewijzigd.
We bouwden geen chatbot met betere voetnoten. We bouwden een onderzoeksplatform waar elk antwoord per ontwerp verdedigbaar is.
Nooit meer adviseren op basis van verouderd onderzoek — wij waarschuwen u automatisch wanneer bronnen wijzigen.
Bronnen: 1. Charlotin, D. (2025). “AI Hallucination Cases Database.” HEC Paris. 2. Dahl, M. et al. (2024). “Large Legal Fictions: Profiling Legal Hallucinations in Large Language Models.” Journal of Legal Analysis, 16(1), 64-93. 3. Orde van Vlaamse Balies (2024). “AI-richtlijnen voor advocaten.” 4. Belgische Gegevensbeschermingsautoriteit (2024). “Informatieve brochure: AI-systemen en AVG.” September 2024. 5. EU-verordening 2024/1689 (AI Act), artikel 12: Automatische loggingvereisten voor hoogrisico-AI-systemen.