Wat is RAG — en waarom het alleen niet genoeg is voor juridische AI
Hoe retrieval-augmented generation werkt, waarom basis-RAG nog steeds hallucineert, en wat een zoek-RAG-fusiearchitectuur toevoegt voor fiscalisten.
Door Auryth Team
Elk AI-antwoord zonder bronvermelding is een mening verpakt als onderzoek. Dat klinkt hard — tot u beseft dat de meeste AI-tools die professionals vandaag gebruiken precies dit doen: zelfverzekerde tekst genereren uit het geheugen, zonder mogelijkheid om te controleren waar het antwoord vandaan komt.
De architectuur die dit begon op te lossen heeft een naam: RAG. Maar basis-RAG is slechts het begin. Begrijpen wat het doet — en waar het faalt — is het belangrijkste dat een fiscalist in 2026 over AI kan leren.
Wat is retrieval-augmented generation?
Retrieval-Augmented Generation (RAG) is een AI-architectuur waarbij het systeem eerst een kennisbank doorzoekt op relevante documenten, en die documenten vervolgens — samen met uw vraag — doorstuurt naar een taalmodel dat een antwoord formuleert op basis van wat het gevonden heeft. Anders dan chatbots die uit het geheugen antwoorden, baseert een RAG-systeem elke reactie op opgehaalde bronnen.
Denk aan het verschil tussen twee collega’s. De ene beantwoordt uw fiscale vraag uit het geheugen — zelfverzekerd, soms correct, soms niet. De andere loopt naar de bibliotheek, pakt de relevante bepalingen, leest ze, en geeft u een antwoord met paginanummers. RAG is die tweede collega.
Het concept werd geformaliseerd door Lewis et al. in een paper uit 2020 op NeurIPS, waarbij parametrisch geheugen (de getrainde kennis van het taalmodel) gecombineerd werd met niet-parametrisch geheugen (een doorzoekbare documentenindex). Het inzicht was simpel maar transformatief: in plaats van een model alles te laten onthouden, laat het dingen opzoeken.
Waarom basis-RAG niet genoeg is
Hier is wat de meeste RAG-uitleg u niet vertelt: vanilla RAG — documenten in een vectordatabase dumpen, een taalmodel aansluiten, klaar — hallucineert nog steeds bij 17–33% van de juridische queries. Stanford-onderzoekers bewezen dit door Westlaw AI en Lexis+ AI te testen, beide RAG-gebaseerde systemen gebouwd door de grootste juridische uitgevers ter wereld.
Waarom? Omdat juridische tekst niet is als Wikipedia-artikelen. Het heeft structuur die basis-RAG negeert:
Hiërarchie. Een arrest van het Hof van Cassatie weegt zwaarder dan een Fisconetplus-circulaire. Basis-RAG behandelt ze als gelijkwaardige stukken tekst. Wanneer een circulaire case law tegenspreekt, kiest een systeem zonder autoriteitsbewustzijn welke tekst het best bij uw vraag past — en dat kan de verkeerde zijn.
Temporaliteit. Het Belgische vennootschapsbelastingtarief was 29,58% in 2019 en 25% vandaag. Basis-RAG haalt op welke versie zijn vectorzoekopdracht het eerst vindt. Vraag naar 2019 en u krijgt mogelijk het tarief van 2026 — met volle zekerheid gesteld.
Kruisverwijzingen. Een enkele fiscale vraag kan tegelijkertijd Art. 19bis WIB, het TOB-kader en een bepaling uit de Vlaamse Codex Fiscaliteit omvatten. Basis-RAG haalt fragmenten op. Het begrijpt niet dat deze bepalingen op elkaar inwerken.
De generatiestap verergert het probleem. Zelfs met correcte retrieval kan het taalmodel verkeerd interpreteren, overgeneraliseren of bronnen combineren op manieren die de originele teksten niet ondersteunen. Citatievalidatie — controleren of elke geciteerde bron daadwerkelijk zegt wat het model eraan toeschrijft — is een noodzakelijke extra laag die basis-RAG niet bevat.
Documenten in een vectordatabase dumpen is de minimale RAG-implementatie. Voor juridisch werk is het het maximale aansprakelijkheidsrisico.
Van basis-RAG naar zoek-RAG-fusie
Het inzicht dat professionele juridische AI onderscheidt van een demo is dit: RAG is een generatiestrategie, geen zoekstrategie. De “retrieval” in RAG is slechts zo goed als de zoekinfrastructuur eronder.
Een zoek-RAG-fusiearchitectuur legt professionele zoekmogelijkheden vóór het taalmodel ooit een document ziet:

| Stap | Wat er gebeurt | Waarom basis-RAG dit niet kan |
|---|---|---|
| 1. Parseer | Het systeem identificeert het fiscale domein, de jurisdictie en de tijdsperiode uit uw vraag | Basis-RAG embedt gewoon de ruwe vraag — geen domeinbewustzijn |
| 2. Hybride zoekopdracht | Twee zoekstrategieën lopen parallel: BM25 (exacte juridische termen zoals “Art. 344 WIB”) en vectorembeddings (semantische betekenis). Resultaten worden samengevoegd via Reciprocal Rank Fusion | Basis-RAG gebruikt alleen vectorzoekopdrachten — mist exacte artikelverwijzingen |
| 3. Autoriteitsranking | Resultaten worden hergerangschikt op juridisch gewicht: Grondwet → EU-recht → federale wetten → rechtspraak → circulaires → doctrine | Basis-RAG behandelt alle documenten gelijk |
| 4. Cross-encoder herranking | Een gespecialiseerd model leest elke bron naast uw vraag en scoort de werkelijke relevantie | Basis-RAG vertrouwt op embedding-gelijkenis, die nuance mist |
| 5. Genereer + citeer | Het taalmodel leest de gerangschikte bronnen en produceert een gestructureerd antwoord — elke bewering gekoppeld aan zijn bron | Hetzelfde als basis-RAG, maar met veel betere inputs |
Het verschil tussen stap 2 alleen (basis-RAG) en stappen 1–4 samen (zoek-RAG-fusie) is het verschil tussen een relevante tekst vinden en de juiste wet, van de juiste autoriteit, op het juiste moment in de tijd vinden.
Waarom verifieerbaarheid belangrijker is dan nauwkeurigheid
De meeste RAG-uitleg focust op nauwkeurigheid — RAG vermindert hallucinaties, RAG geeft betere antwoorden. Dat klopt, maar het mist de essentie.
Het echte voordeel is niet nauwkeurigheid. Het is verifieerbaarheid.
Een gefinetuned model is misschien 95% nauwkeurig. Een zoek-RAG-systeem misschien 92%. Maar het zoek-RAG-systeem toont u precies welke bronnen het gebruikte, gerangschikt op juridische autoriteit, zodat u de 8% zelf kunt controleren. Het gefinetuned model biedt geen manier om te weten welke antwoorden bij de 5% horen.
Voor een fiscalist is dit verschil allesbepalend. Uw beroepsaansprakelijkheid hangt niet af van de nauwkeurigheid van de tool. Het hangt af van of u het advies dat u uw cliënt gaf, hebt geverifieerd.
De vraag is niet “is deze AI nauwkeurig?” De vraag is “kan ik het controleren?”
Wij noemen dit het verifieerbaarheidsbeginsel: een tool die 90% nauwkeurig en transparant is, is veiliger dan een die 95% nauwkeurig en ondoorzichtig is. Elk procentpunt nauwkeurigheid dat u niet kunt verifiëren, is een aansprakelijkheidsrisico dat u niet kunt beheersen.
Zoek-RAG-fusie vs. fine-tuning: de bibliotheek vs. het handboek
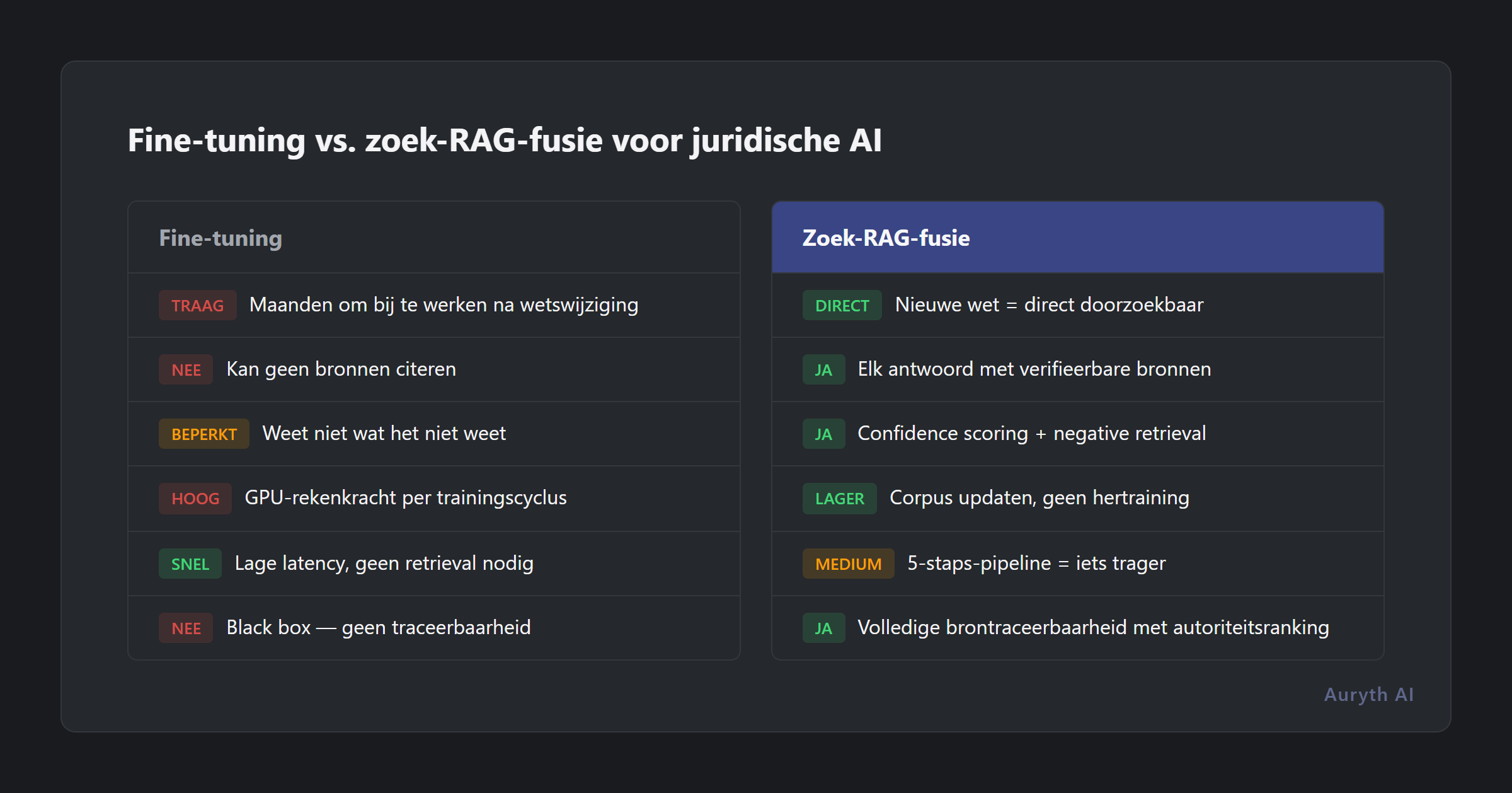
Het voornaamste alternatief voor RAG-gebaseerde benaderingen is fine-tuning — een model trainen op domeinspecifieke data zodat de kennis in de gewichten wordt gebakken. Denk aan een handboek memoriseren versus toegang hebben tot een bibliotheek met een professionele bibliothecaris.
| Aspect | Fine-tuning | Zoek-RAG-fusie |
|---|---|---|
| Kennisbron | Ingebakken in modelgewichten | Opgehaald uit een beheerd, gestructureerd corpus |
| Actualiseerbaarheid | Model opnieuw trainen (weken, duur) | Corpus bijwerken (uren, goedkoop) |
| Transparantie | Black box — antwoorden niet herleidbaar tot bronnen | Volledige citatieketen met autoriteitsranking |
| Geschiktheid Belgisch fiscaal recht | Wetgeving verandert sneller dan modellen hertraind worden | Nieuwe bepaling = direct doorzoekbaar met metadata |
| Kosten | Hoog (GPU-rekenkracht voor training) | Lager (zoekinfrastructuur) |
| Hallucinatierisico | Hallucineert zelfverzekerd, geen manier om te controleren | Kan nog steeds hallucineren, maar elke bron is verifieerbaar |
Harvey, gesteund door meer dan een miljard dollar aan investeringen, koos aanvankelijk fine-tuning voor zijn Amerikaans-gerichte juridische AI. Dat is logisch voor een relatief stabiel rechtssysteem met diepe zakken voor continue hertraining. Belgisch fiscaal recht — met drie gewesten, twee officiële talen, voortdurende wetswijzigingen en een regelgevend landschap dat per kwartaal verschuift — vraagt een andere aanpak.
Wanneer de Vlaamse tarieven voor erfbelasting veranderen, heeft een gefinetuned model hertraining nodig. Een zoek-RAG-systeem heeft een corpus-update nodig.
Hoe dit eruitziet in de Belgische fiscale praktijk
Neem een vraag die elke Belgische fiscalist kan tegenkomen: “Wat zijn de TOB-gevolgen van het overstappen van een distribuerend naar een kapitaliserend ETF?”
Een algemeen taalmodel zal antwoorden op basis van trainingsdata — die maanden of jaren achterhaald kan zijn, Belgische en Nederlandse regels door elkaar kan halen, en niet het specifieke artikel in het WIB 92 of de relevante Fisconetplus-circulaire kan citeren.
Een zoek-RAG-fusiesysteem gebouwd voor Belgisch fiscaal recht doet het volgende:
- Parseert de vraag — identificeert TOB als het fiscale domein, bepaalt de relevante aanslagperiode, signaleert dat fondsclassificatie ertoe doet
- Doorzoekt het Belgische juridische corpus met hybride zoekopdrachten — BM25 vindt “TOB” en specifieke artikelnummers exact, vectorzoekopdrachten vinden semantisch gerelateerde bepalingen over fondsbelasting
- Rangschikt op autoriteit — een wettelijke bepaling weegt zwaarder dan een circulaire; een arrest van het Hof van Cassatie weegt zwaarder dan doctrine
- Herrangschikt op relevantie — een cross-encoder model scoort elke kandidaat tegen uw werkelijke vraag, en filtert valse positieven
- Genereert een gestructureerd antwoord met citering van elke bron, met een betrouwbaarheidsscore per bewering
- Signaleert lacunes — als er geen specifieke ruling bestaat over een nuance van uw vraag, vertelt het u dat
Dat laatste punt is minstens zo belangrijk als het antwoord zelf. In de professionele fiscale praktijk is de wetenschap dat er geen autoriteit bestaat over een specifiek punt waardevolle informatie — het betekent dat u in interpretatiegebied zit en dienovereenkomstig moet handelen.
De eerlijke beperkingen
Zelfs een goed ontworpen zoek-RAG-fusiesysteem heeft reële beperkingen:
Retrievalkwaliteit is het plafond. Als het juiste document niet in het corpus zit, of als de zoekpipeline het niet bovendrijft, kan het model het niet gebruiken. Het systeem is slechts zo goed als zijn kennisbasis en zijn zoekalgoritmen.
De generatiestap kan nog steeds fabriceren. Zelfs met perfecte retrieval en ranking kan het taalmodel bronnen verkeerd interpreteren of combineren op manieren die de originele teksten niet ondersteunen. Daarom is citatievalidatie — onafhankelijk controleren of elke geciteerde bron zegt wat het model beweert — een noodzakelijke post-generatielaag.
Complexiteit heeft een prijs. Een vijf-staps-pipeline is trager dan een enkele vectoropzoeking. De afweging is het waard voor professioneel werk waar correctheid meer telt dan snelheid — maar het is een afweging.
De eerlijke beoordeling: zoek-RAG-fusie reduceert het probleem van catastrofaal (58–88% hallucinatie bij algemene taalmodellen) naar beheersbaar (aanzienlijk lager dan de 17–33% van basis juridische RAG, met extra verificatielagen). Maar “beheersbaar” betekent nog steeds dat professioneel oordeelsvermogen essentieel blijft. Het systeem versnelt uw onderzoek — het vervangt uw expertise niet.
Gerelateerde artikelen
- AI-hallucinaties: waarom ChatGPT bronnen verzint (en hoe u dat herkent)
- Ik vroeg ChatGPT en Auryth dezelfde Belgische fiscale vragen — dit is wat er gebeurde
- Fine-tuning vs. RAG: twee manieren om AI slim te maken
Hoe Auryth TX dit toepast
Auryth TX gebruikt geen basis-RAG. Het fuseert professionele zoekinfrastructuur met retrieval-augmented generation — omdat de kwaliteit van de retrieval de kwaliteit van het antwoord bepaalt.
Elke vraag doorloopt een vijf-staps-pipeline: hybride zoekopdracht (BM25 + vectorembeddings samengevoegd via Reciprocal Rank Fusion), autoriteitsranking over een 13-laags Belgisch juridisch hiërarchie, cross-encoder herranking voor precisie, gestructureerde antwoordgeneratie met per-bewering citaten, en post-generatie citatievalidatie met betrouwbaarheidsscore.
Het Belgische juridische corpus is onze kennisbasis: WIB 92, Fisconetplus, DVB-voorafgaande beslissingen, VCF, rechterlijke uitspraken en doctrinaire publicaties — allemaal gestructureerd met temporele metadata, jurisdictietags en autoriteitsniveaus. Wanneer bronnen elkaar tegenspreken, worden beide kanten getoond. Wanneer het bewijs dun is, vertelt de betrouwbaarheidsscore u dat expliciet. Wanneer de wet verandert, wordt het corpus binnen uren bijgewerkt.
Wij vragen u niet om de AI te vertrouwen. Wij vragen u om de bronnen te controleren die het u toont. Dat is het verifieerbaarheidsbeginsel in de praktijk.
Ontdek hoe onze zoek-RAG-pipeline werkt — schrijf u in op de wachtlijst →
Bronnen: 1. Lewis, P. et al. (2020). “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.” NeurIPS. 2. Magesh, V. et al. (2025). “Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools.” Journal of Empirical Legal Studies. 3. Schwarcz, D. et al. (2025). “AI-Powered Lawyering: AI Reasoning Models, Retrieval Augmented Generation, and the Future of Legal Practice.” SSRN.