5 belgische Steuerfragen, bei denen generische KI garantiert versagt
Das sind keine Fangfragen. Es sind Routineanfragen, die jeder Steuerberater stellt. Aber sie legen fünf architektonische blinde Flecken offen, die kein generisches KI-Modell mit einem besseren Prompt beheben kann.
Von Auryth Team
Wir haben ChatGPT, Copilot und Gemini mit fünf belgischen Steuerfragen getestet, die jeder Steuerberater während eines gewöhnlichen Arbeitstages stellen könnte. Keine Grenzfälle. Keine Fangfragen. Die Art von Anfragen, die Sie stellen würden, während Sie eine Kundenakte durchsehen.
Alle fünf produzierten zuversichtliche, gut strukturierte Antworten. Alle fünf waren falsch — oder gefährlich unvollständig. Und die Fehler waren nicht zufällig. Jeder einzelne legt eine andere architektonische Einschränkung offen, die kein Prompt Engineering beheben kann.
Wenn Sie generische KI für Steuerrecherchen verwenden, müssen Sie diese Fragen verstehen. Nicht weil sie die einzigen Fehler sind — sondern weil sie die fünf strukturellen Fehlerkategorien repräsentieren, die sich bei jeder Anfrage wiederholen.
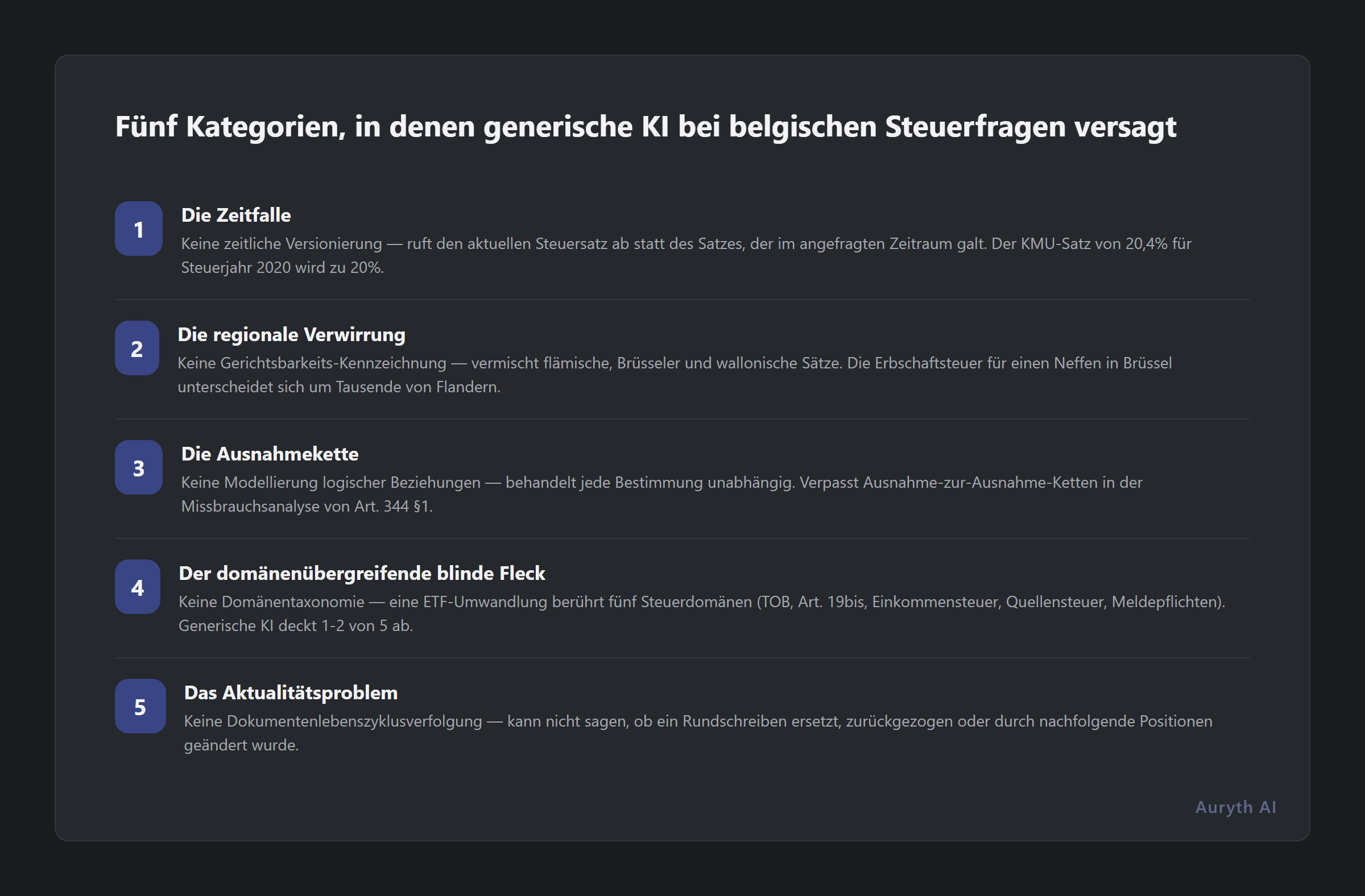
1. Die Zeitfalle
Die Frage: “Was war der belgische Körperschaftsteuersatz für KMU mit einem steuerpflichtigen Einkommen bis zu 100.000 € im Steuerjahr 2020?”
Was generische KI sagt: “Der KMU-Satz beträgt 20 % auf die ersten 100.000 € des steuerpflichtigen Einkommens gemäß Art. 215, Absatz 2 EStGB 92.” Zuversichtlich. Klar. Falsch für den erfragten Zeitraum.
Was tatsächlich geschah: Der reduzierte KMU-Satz betrug 20,4 % für das Steuerjahr 2020 (Einkommensjahr 2019), Teil der Übergangssätze während der Körperschaftsteuerreform. Der 20 %-Satz gilt erst ab Steuerjahr 2021. Die KI ruft den aktuellen Satz ab und projiziert ihn rückwärts — weil sie kein Konzept zeitlicher Versionierung hat.
Warum das architektonisch versagt: Generische KI-Modelle haben einen einzigen Wissensschnappschuss. Sie führen keine zeitlichen Versionen von Rechtsvorschriften. Wenn Sie nach einem historischen Zeitraum fragen, hat das Modell keinen Mechanismus, das Gesetz so abzurufen, wie es zu diesem Zeitpunkt war. Es gibt Ihnen, woran es sich “erinnert” — was normalerweise die neueste Version ist, mit der es trainiert wurde.
Was es Sie kostet: Ein falscher Satz in einer Steuererklärung löst bestenfalls eine administrative Korrektur aus, schlimmstenfalls eine Strafe. Für einen Steuerberater ist es auch ein Reputationsrisiko — die Art von Fehler, die Kunden an Ihrer Sorgfalt zweifeln lässt.
2. Die regionale Verwirrung
Die Frage: “Wie hoch ist der Erbschaftsteuersatz in Brüssel für eine Erbschaft von 300.000 €, die ein Neffe erhält?”
Was generische KI sagt: Sie produziert typischerweise eine Satztabelle — vermischt aber flämische und Brüsseler Sätze oder gibt nur die Sätze einer Region an, ohne zu spezifizieren, welche. Mehrere von uns getestete Modelle gaben den flämischen Satztarif (der unterschiedliche Stufen und Schwellenwerte verwendet) an, während sie behaupteten, über Brüssel zu antworten.
Was tatsächlich geschah: Brüssel wendet seinen eigenen Satztarif für die Kategorie “zwischen Geschwistern” und “zwischen Onkeln/Tanten und Neffen/Nichten” mit anderen Stufen als Flandern oder Wallonien an. Der Satz für einen Neffen auf 300.000 € in Brüssel unterscheidet sich von Flandern um mehrere tausend Euro.
Warum das architektonisch versagt: Belgien hat drei Steuerregionen mit unterschiedlichen Erbschaftsteuerregimen. Generische KI behandelt Belgien als eine einzige Gerichtsbarkeit — oder schlimmer noch, wählt willkürlich Bestimmungen aus, welche Quelle ihre Vektorsuche zuerst findet. Sie hat keine Gerichtsbarkeits-Kennzeichnung für ihre Trainingsdaten und keinen Mechanismus, um flämische, Brüsseler und wallonische Regeln zu unterscheiden, wenn sie ähnliche Terminologie verwenden.
Was es Sie kostet: Einen Brüsseler Kunden auf Basis flämischer Sätze zu beraten, ist nicht nur ungenau — es bedeutet eine Beratung unter einem völlig falschen Rechtsrahmen. Der Kunde verlässt sich auf Ihre Zahl. Wenn sie falsch ist, liegt die Haftung bei Ihnen.
3. Die Ausnahmekette
Die Frage: “Gibt es eine Ausnahme von der allgemeinen Missbrauchsbestimmung des Art. 344 §1 EStGB 92 für Vorgänge, die speziell durch einen Vorabbescheid genehmigt wurden?”
Was generische KI sagt: Die meisten Modelle erkennen Art. 344 an und beschreiben die allgemeine Missbrauchsregel, verpassen aber die kritische Nuance: die Beziehung zwischen Art. 344 §1 (allgemeiner Missbrauch), spezifischen Missbrauchsbestimmungen (wie Art. 344 §2) und die Rolle von Vorabbescheiden (DVB) bei der Bereitstellung von Rechtssicherheit für spezifische Vorgänge.
Was tatsächlich geschah: Die Wechselwirkung zwischen Art. 344 §1 EStGB 92, den spezifischen Missbrauchsbestimmungen und dem Vorabentscheidungsdienst (DVB) umfasst eine Ausnahme-zur-Ausnahme-Kette. Ein DVB-Vorabbescheid zu einem spezifischen Vorgang immunisiert ihn nicht automatisch gegen Art. 344 §1 — aber die Analyse hängt davon ab, ob der Bescheid speziell die Missbrauchsfrage behandelt hat und von den vorgelegten materiellen Fakten.
Warum das architektonisch versagt: Juristische Argumentation beinhaltet oft Ausnahmeketten, bei denen Bestimmung A Ausnahme B hat, die selbst Ausnahme C hat. Generische KI behandelt jede Bestimmung als unabhängigen Textblock. Sie modelliert nicht die logischen Beziehungen zwischen ihnen — die “außer wenn”- und “ungeachtet”- und “unbeschadet”-Ketten, die definieren, wie Bestimmungen tatsächlich interagieren.
Was es Sie kostet: Die Missbrauchsanalyse gehört zur risikoreichsten Steuerarbeit. Eine unvollständige Analyse, die eine Ausnahme verpasst — oder eine Ausnahme zur Ausnahme — kann den Unterschied zwischen einer Struktur, die eine Prüfung übersteht, und einer, die es nicht tut, bedeuten.
4. Der domänenübergreifende blinde Fleck
Die Frage: “Was sind alle steuerlichen Auswirkungen, wenn ein belgischer Resident einen ausschüttenden ETF in einen thesaurierenden ETF umwandelt?”
Was generische KI sagt: Sie deckt typischerweise die TOB-Auswirkungen (Steuer auf Börsentransaktionen) ab — manchmal korrekt — verpasst aber die meisten anderen Domänen. Die Antworten, die wir erhielten, deckten 1-2 von 5 relevanten Steuerdomänen ab.
Was tatsächlich geschah: Dieser Vorgang berührt mindestens fünf verschiedene Steuerdomänen:
- TOB — Transaktionssteuer auf den Verkauf des ausschüttenden Fonds und Kauf des thesaurierenden Fonds
- Art. 19bis EStGB 92 — Besteuerung der “Zinskomponente” beim Ausstieg aus einem Schuldenfonds, wenn >10 % in Schuldinstrumenten
- Einkommensteuer — Behandlung eines realisierten Kapitalgewinns (ordentlich vs. Spekulation vs. beruflich)
- Quellensteuer — Behandlung aufgelaufener Dividenden zum Zeitpunkt der Umwandlung
- Meldepflichten — Meldung ausländischer Konten, wenn der thesaurierende Fonds im Ausland gehalten wird
Warum das architektonisch versagt: Generische KI verarbeitet Ihre Frage als einzelne Anfrage gegen einen flachen Textindex. Sie hat kein Konzept von Steuerdomänengrenzen. Sie kann nicht systematisch von TOB zur Einkommensteuer zur Quellensteuer zu Meldepflichten traversieren — weil ihr Abrufmechanismus nicht weiß, dass diese Domänen als separate, miteinander verbundene Bereiche existieren. Speziell entwickelte Systeme mit Domänentaxonomie können domänenübergreifenden Abruf auslösen und kennzeichnen, welche Domänen abgedeckt wurden und welche nicht.
Was es Sie kostet: Einen Kunden zu einer Fondsumwandlung zu beraten, während drei von fünf steuerlichen Auswirkungen fehlen, ist keine Teilberatung — es ist eine Beratung, die ein falsches Gefühl von Vollständigkeit erzeugt. Der Kunde nimmt an, Sie hätten alles abgedeckt. Sie nahmen an, die KI hätte alles abgedeckt. Niemand hat überprüft.
5. Das Aktualitätsproblem
Die Frage: “Ist das Fisconetplus-Rundschreiben vom 15. März 2023 zur steuerlichen Behandlung von Kryptowährungs-Staking-Belohnungen noch in Kraft?”
Was generische KI sagt: Modelle, die vor einem bestimmten Datum trainiert wurden, werden entweder bestätigen, dass das Rundschreiben existiert, oder eines erfinden. Keines kann Ihnen sagen, ob es durch nachfolgende administrative Positionen ersetzt, zurückgezogen oder geändert wurde.
Was tatsächlich geschah: Administrative Rundschreiben und Leitlinien entwickeln sich. Sie werden durch neue Rundschreiben ersetzt, durch Gerichtsentscheidungen geändert oder durch Gesetzesänderungen teilweise obsolet gemacht. Ein Rundschreiben von 2023 spiegelt möglicherweise die aktuelle administrative Position im Jahr 2026 wider oder nicht — und der einzige Weg, das zu wissen, ist zu prüfen, ob nachfolgende Positionen herausgegeben wurden.
Warum das architektonisch versagt: Generische KI hat kein Konzept des Dokumentenlebenszyklus. Sie verfolgt nicht, welche Rundschreiben ersetzt wurden, welche Entscheidungen aufgehoben wurden oder welche Bestimmungen geändert wurden. Ihr Wissen ist ein Schnappschuss — und sie kann Ihnen nicht sagen, wo dieser Schnappschuss veraltet ist. Speziell entwickelte Systeme mit zeitlichen Metadaten und Ersetzungsverfolgung können kennzeichnen, wann eine Quelle möglicherweise nicht mehr das aktuelle Recht widerspiegelt.
Was es Sie kostet: Auf Basis eines ersetzten Rundschreibens zu beraten bedeutet, auf Basis eines Gesetzes zu beraten, das nicht mehr existiert. Die berufshaftungsrechtlichen Implikationen sind eindeutig.
Das Muster
Diese fünf Fehler sind keine Bugs, die in GPT-6 oder der nächsten Modellversion behoben werden. Sie sind strukturelle Konsequenzen davon, wie generische KI Text verarbeitet:
- Keine zeitliche Versionierung → falsche historische Antworten
- Keine Gerichtsbarkeits-Kennzeichnung → regionale Verwirrung
- Keine Modellierung logischer Beziehungen → gebrochene Ausnahmeketten
- Keine Domänentaxonomie → unvollständige domänenübergreifende Abdeckung
- Keine Dokumentenlebenszyklusverfolgung → Abhängigkeit von veralteten Quellen
Jeder Fehler entspricht einer architektonischen Fähigkeit, die allgemeine Modelle nicht haben — und nicht allein durch besseres Training entwickeln können. Diese erfordern speziell entwickelte Suchinfrastruktur, strukturierte juristische Corpora und domänenspezifische Abruf-Pipelines.
Die Frage ist nicht, ob generische KI “besser wird”. Das tut sie. Die Frage ist, ob die Architektur professionelle Steuerarbeit unterstützen kann. Diese fünf Tests sagen nein.
Verwandte Artikel
- Ich habe ChatGPT und Auryth dieselben belgischen Steuerfragen gestellt — hier ist, was passierte
- KI-Halluzinationen: warum ChatGPT Quellen erfindet (und wie man es erkennt)
- Was ist RAG — und warum es allein nicht ausreicht für juristische KI
Wie Auryth TX diese fünf Fragen behandelt
Diese fünf Fehlerkategorien sind genau das, wofür Auryths TX Search-RAG-Fusion-Architektur entwickelt wurde:
-
Zeitlich — Jede Bestimmung in unserem Corpus trägt zeitliche Metadaten. Wenn Sie nach dem Steuerjahr 2020 fragen, ruft das System die Version des Gesetzes ab, die in diesem Zeitraum galt — nicht die heutige Version.
-
Regional — Gerichtsbarkeits-Tags auf jedem Dokument. Eine Brüsseler Erbschaftsfrage ruft Brüsseler Sätze aus dem Brüsseler Steuergesetzbuch ab. Flämische Bestimmungen werden ausgeschlossen, es sei denn, Sie fragen ausdrücklich nach einem Vergleich.
-
Ausnahmeketten — Querverweismapping zwischen Bestimmungen. Wenn Art. 344 §1 abgerufen wird, ruft das System auch die Bestimmungen ab, die ihn modifizieren, begrenzen oder erweitern — und präsentiert die Beziehungsstruktur.
-
Domänenübergreifend — Domänentaxonomie löst domänenübergreifenden Abruf aus. Eine ETF-Umwandlungsfrage durchläuft systematisch TOB, Einkommensteuer, Quellensteuer, Art. 19bis und Meldepflichten — und kennzeichnet, welche Domänen abgedeckt wurden.
-
Aktualität — Ersetzungsverfolgung und zeitliche Validierung. Wenn Sie nach einem 2023er Rundschreiben fragen, prüft das System, ob nachfolgende administrative Positionen herausgegeben wurden.
Das sind keine Funktionen, die wir auf einen Chatbot aufgesetzt haben. Sie sind das architektonische Fundament des Systems.
Testen Sie diese fünf Fragen selbst — treten Sie der Warteliste bei →
Quellen: 1. Belgisches Einkommensteuergesetzbuch (EStGB 92), Art. 215, Art. 344, Art. 19bis. 2. Erbschaftsteuergesetzbuch der Region Brüssel-Hauptstadt, Art. 48-54. 3. Magesh, V. et al. (2025). „Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools.” Journal of Empirical Legal Studies.