Ich stellte ChatGPT und Auryth dieselben belgischen Steuerfragen — das ist passiert
Drei Steuerfragen, zwei KI-Tools, eine klare Lektion: Für professionelle Recherche schlägt Verifizierbarkeit Selbstsicherheit.
Von Auryth Team
Sie haben es getan. Ihr Kollege hat es getan. Irgendwann in den letzten zwei Jahren hat jeder Steuerberater in Belgien eine steuerliche Frage in ChatGPT eingegeben.
Die Antwort klang wahrscheinlich vernünftig. Vielleicht sogar beeindruckend. Aber hier ist die Frage, die niemand danach stellt: Wie würden Sie das überprüfen?
Wir haben ein einfaches Experiment durchgeführt. Drei belgische Steuerfragen mit steigender Komplexität — die Art von Fragen, die ein Steuerexperte wöchentlich bearbeitet. Wir haben ChatGPT (GPT-4o) und Auryth TX, unsere speziell entwickelte belgische Steuerrecherche-Plattform, befragt. Dieselben Fragen, am selben Tag, ohne Prompt-Engineering-Tricks.
Die Ergebnisse offenbaren etwas Interessanteres als „richtig versus falsch”.
Frage 1: „Wie hoch ist der aktuelle belgische Körperschaftsteuersatz?”
ChatGPT antwortete korrekt: 25 %, mit dem reduzierten Satz von 20 % für KMU auf die ersten 100.000 € steuerpflichtigen Gewinns. Klar. Präzise.
Auryth lieferte dieselben Zahlen — zitierte aber direkt Art. 215 WIB 92 (Wetboek van de Inkomstenbelastingen 1992), verlinkte auf die spezifische Bestimmung und wies auf die Bedingungen von Art. 215 Absatz 3 hin: die Vergütungsanforderung und die Beteiligungsschwelle.
Beide Tools nannten die richtige Zahl. Aber nur eines zeigte warum sie richtig war und welche Bedingungen gelten. Wenn Ihr Mandant fragt „qualifizieren wir uns für den reduzierten Satz?” — ist die selbstsichere Zahl ein Ausgangspunkt. Die quellenbasierte Antwort ist ein Fundament für Beratung.
Die Lücke zwischen einer korrekten Zahl und einer verifizierbaren Antwort ist der Bereich, in dem berufliche Haftung angesiedelt ist.
Frage 2: „Wie hoch ist der TOB-Satz auf einen thesaurierenden ETF?”
Hier wird es interessant.
ChatGPT antwortete: 1,32 %. Mit Selbstsicherheit vorgetragen. Keine Einschränkungen.
Diese Antwort ist unvollständig. TOB-Sätze für ETFs betragen 0,12 %, 0,35 % oder 1,32 % — abhängig von den Merkmalen des Fonds. Ein thesaurierender ETF, der in Belgien registriert ist, zahlt 1,32 %, aber derselbe thesaurierende ETF, anderswo im EWR registriert, zahlt nur 0,12 % — ein elffacher Unterschied. Ob ein Fonds als „in Belgien registriert” gilt, hängt davon ab, ob eines seiner Compartments bei der FSMA registriert ist. Ausschüttende ETFs zahlen 0,12 %. Nicht-EWR-Instrumente: 0,35 %. Ein Berater, der zum ETF-Kauf rät, muss den spezifischen Registrierungs- und Ausschüttungsstatus des Fonds kennen — nicht nur einen einzigen Satz.
Auryth identifizierte alle drei anwendbaren TOB-Sätze, erklärte die Klassifizierungskriterien — Registrierungsort, Thesaurierung vs. Ausschüttung, EWR-Status — und kennzeichnete, welcher Satz für den spezifischen Fonds in der Frage galt.
Das ist Klassifizierungsblindheit — ein Fehlermodus allgemeiner KI-Systeme. ChatGPT wählt die häufigste Antwort und präsentiert sie als die einzige. Das belgische Steuerrecht ist voller Klassifizierungsabhängigkeiten: Sätze, die sich je nach Produktstruktur, Registrierung, Domizil und Haltedauer ändern. Eine KI, die diese Unterscheidungen zu einer einzigen selbstsicheren Zahl zusammenfaltet, ist nicht nur unvollständig — sie ist gefährlich für professionelle Beratung.
; Magesh et al. (2025), Stanford HAI")
Frage 3: „Was sind alle steuerlichen Auswirkungen eines TAK-23-Versicherungsprodukts für einen belgischen Steuerinländer?”
Jetzt befinden wir uns im professionellen Terrain.
ChatGPT identifizierte Einkommensteuer (mit Erwähnung von Art. 19bis WIB für die Reynders-Steuer auf Kapitalgewinne) und Versicherungsprämiensteuer. Zwei Bereiche. Präsentiert mit derselben unerschütterlichen Sicherheit wie bei Frage 1.
Es übersah drei:
- Schenkungs- und Erbschaftssteuer — entscheidend für die Nachfolgeplanung, geregelt durch den Vlaamse Codex Fiscaliteit (VCF) in Flandern, Code des droits de succession in Wallonien und Brüssel
- TOB-Befreiung — Fondswechsel innerhalb eines TAK-23-Mantels unterliegen keiner Börsensteuer, im Gegensatz zu direkten ETF-Transaktionen. ChatGPT hat diesen entscheidenden Strukturvorteil nicht erkannt
- Wertpapierkontosteuer (effectentaks) — die jährliche Steuer von 0,15 % auf Wertpapierkonten über 1 Million Euro, die über das Durchschauungsprinzip auch auf TAK-23-Produkte anwendbar sein kann
Ein TAK-23-Produkt berührt mindestens fünf Steuerbereiche. ChatGPT behandelte zwei. Die drei übersehenen sind genau diejenigen, bei denen Mandanten Geld verlieren und Berater Haftungsansprüchen gegenüberstehen.
Auryth strukturierte seine Antwort als domänenübergreifende Analyse: ein Domänen-Radar, das alle fünf Bereiche identifiziert, Schlussfolgerungen je Domäne mit nach Autorität gewichteten Quellen, Konfidenzbewertungen (hoch für Einkommensteuer, moderat für regionale Variationen angesichts sich entwickelnder Rechtsprechung) und einen Abschnitt „identifizierte Lücken”, der vermerkt, was nicht gefunden wurde.
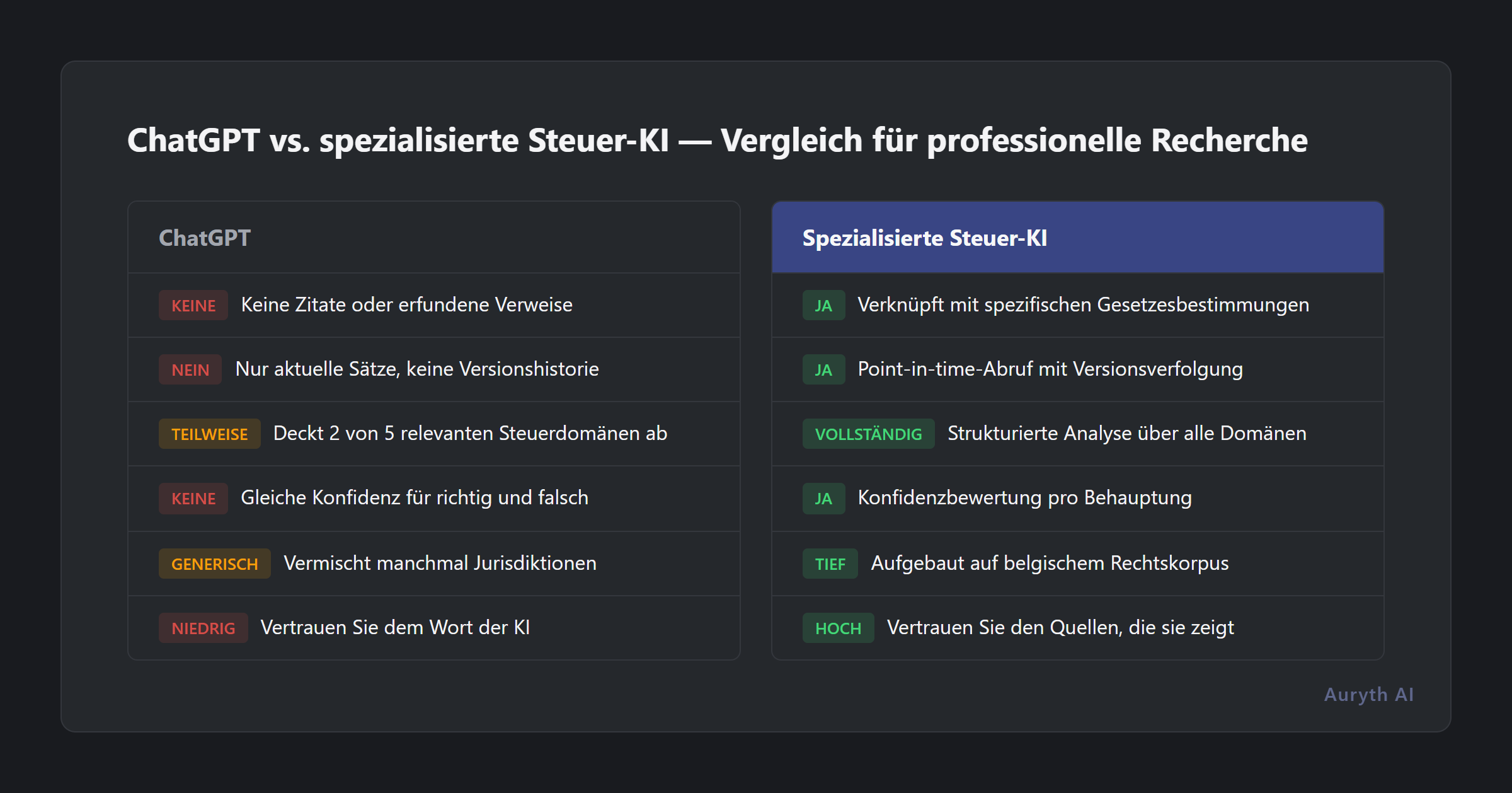
| Dimension | ChatGPT | Spezialisierte Steuer-KI |
|---|---|---|
| Quellenangaben | Keine oder erfunden | Verlinkt auf spezifische Rechtsvorschriften |
| Temporales Bewusstsein | Nur aktuelle Sätze | Zeitpunktgenaue Abfrage mit Versionsverlauf |
| Domänenübergreifende Abdeckung | Teilweise (2 von 5 Domänen) | Strukturierte Multi-Domänen-Analyse |
| Konfidenzsignale | Gleiche Sicherheit für alles | Konfidenzbewertung je Aussage |
| Belgien-Spezifität | Generisch, vermischt manchmal Rechtsordnungen | Aufgebaut auf belgischem Rechtskorpus |
| Verifizierbarkeit | Vertrauen Sie der KI | Vertrauen Sie den Quellen, die sie Ihnen zeigt |
Die Verifikationslücke
Das Muster über alle drei Fragen hinweg dreht sich nicht um Genauigkeit. Es geht um Verifizierbarkeit.
ChatGPT kann die einfache Antwort richtig liefern. Aber es sagt Ihnen nie:
- Woher die Antwort kommt (keine Quellenangabe)
- Wann die Antwort gilt (kein temporaler Kontext)
- Was fehlt in der Antwort (keine Abdeckungsbeurteilung)
- Wie sicher Sie sein sollten (kein Unsicherheitssignal)
Wir nennen dies die Verifikationslücke: die Distanz zwischen der bekundeten Sicherheit einer KI und Ihrer Fähigkeit, ihre Aussagen unabhängig zu überprüfen. Je größer die Lücke, desto größer das berufliche Risiko.
Für eine schnelle Google-Suche spielt die Verifikationslücke keine Rolle. Für professionelle Steuerberatung — wo falsche Antworten finanzielle und rechtliche Konsequenzen haben — ist sie alles.
Ein Tool, das zu 90 % genau ist und ehrlich darüber, ist sicherer als eines, das zu 95 % genau ist und Ihnen nie sagt, wann es falsch liegt.
Aber seien wir ehrlich — spezialisierte KI ist auch nicht perfekt
Stanford-Forscher fanden heraus, dass selbst speziell entwickelte juristische KI-Tools wie Westlaw AI und LexisNexis+ AI in 17–33 % der Fälle halluzinieren. RAG — Retrieval-Augmented Generation, die Architektur hinter den meisten spezialisierten juristischen KI-Systemen — reduziert Halluzinationen dramatisch im Vergleich zu der Rate von 58–88 % bei allgemeinen LLMs. Aber es eliminiert sie nicht.
Der Unterschied ist nicht Perfektion. Es ist Transparenz. Wenn ein spezialisiertes Tool unsicher ist, sagt es Ihnen das. Wenn es eine Quelle zitiert, können Sie sie überprüfen. Wenn es etwas übersieht, kennzeichnet ein gut konzipiertes System die Lücke, anstatt eine partielle Antwort als vollständig zu präsentieren.
Das belgische Steuerrecht enthält echte Mehrdeutigkeiten: Entscheidungen, die Rundschreiben widersprechen, regionale Variationen, die divergieren, Bestimmungen mit mehreren gültigen Auslegungen. Keine KI sollte etwas anderes vorgeben.
Der Drei-Ebenen-Test
Bevor Sie sich auf eine KI-generierte Steuerantwort verlassen — auch auf unsere — wenden Sie drei Prüfungen an:
| Ebene | Frage | Wie Versagen aussieht |
|---|---|---|
| Quelle | Können Sie die Antwort auf eine spezifische Rechtsvorschrift zurückführen? | „Der Satz beträgt 25 %” ohne Artikelreferenz |
| Präzision | Berücksichtigt die Antwort alle relevanten Bedingungen? | Ein Satz angegeben, wenn drei je nach Fondsmerkmalen gelten |
| Vollständigkeit | Hat das Tool alle relevanten Steuerbereiche geprüft? | Zwei Domänen behandelt, wenn fünf zutreffen |
Wenn eine Ebene versagt, betreiben Sie keine Recherche — Sie spielen mit dem Geld Ihres Mandanten und Ihrer beruflichen Reputation.
Verwandte Artikel
- Was ist RAG — und warum es für Steuerberater wichtig ist
- KI-Halluzinationen: Warum ChatGPT Quellen erfindet
- Was ist Confidence Scoring — und warum ist es ehrlicher als eine selbstsichere Antwort?
Wie Auryth TX das umsetzt
Auryth TX wurde speziell für belgische Steuerexperten entwickelt, die verifizierbare Antworten brauchen, keine selbstsicheren Vermutungen. Jede Antwort enthält:
- Quellenangaben nach Autoritätsrang — verlinkt auf spezifische Bestimmungen aus WIB 92, VCF, WBTW und dem breiteren belgischen Rechtskorpus — gewichtet nach juristischer Hierarchie
- Temporale Versionierung — fragen Sie nach einem beliebigen Datum und erhalten Sie die Version des Gesetzes, die damals galt, nicht nur die heutige
- Domänenübergreifende Erkennung — automatische Identifikation aller Steuerbereiche, die eine Frage berührt, mit strukturierter Analyse je Domäne
- Konfidenzbewertung — explizite Angabe, wie gut jede Aussage belegt ist, einschließlich dessen, was das System gesucht aber nicht gefunden hat
Das Ziel ist nicht, Ihr Urteil zu ersetzen. Es ist, Ihnen das vollständige Bild zu geben — mit Quellen — damit Ihr Urteil die bestmögliche Grundlage hat.
Testen Sie es selbst — stellen Sie Auryth und ChatGPT dieselbe Frage und vergleichen Sie.
Quellen: 1. Dahl, M. et al. (2024). “Large Legal Fictions: Profiling Legal Hallucinations in Large Language Models.” Journal of Legal Analysis, 16(1), 64–93. 2. Magesh, V. et al. (2025). “Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools.” Journal of Empirical Legal Studies. 3. Lewis, P. et al. (2020). “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.” NeurIPS. 4. EY Nederland (2023). “Is ChatGPT uw nieuwe belastingadviseur?”