Fine-Tuning vs. RAG: zwei Wege, KI schlau zu machen — und warum es zählt, welchen Ihr Steuer-Tool wählte
Fine-Tuning memoriert das Gesetz von gestern. RAG schlägt das von heute nach. Für belgische Steuerberater bestimmt diese Architekturentscheidung, ob Ihr KI-Tool aktuell ist oder selbstsicher veraltet.
Von Auryth Team
Harvey, das bestfinanzierte juristische KI-Unternehmen der Welt, hat über eine Milliarde Dollar eingesammelt und sein System auf Fine-Tuning aufgebaut — ein Modell so lange auf juristischen Daten trainieren, bis das Wissen in die Gewichte eingebacken ist. Wenn Sie KI-Tools für die Steuerrecherche evaluieren, werden Sie diesen Ansatz kennenlernen. Sie werden auch RAG kennenlernen, Retrieval-Augmented Generation, bei der das Modell Informationen in einer kuratierten Wissensbasis nachschlägt, statt sie aus dem Gedächtnis aufzusagen.
Das sind keine technischen Details. Es sind Architekturentscheidungen, die bestimmen, ob Ihr KI-Tool seine Quellen zeigen kann, aktuell bleibt wenn sich das Gesetz ändert, und Ihnen sagen kann wenn es etwas nicht weiß. Für einen belgischen Steuerberater zählt dieser Unterschied mehr als jeder Genauigkeits-Benchmark.
Was Fine-Tuning wirklich macht
Fine-Tuning nimmt ein vortrainiertes Sprachmodell und trainiert es auf domänenspezifischen Daten neu — Urteile, Steuergesetze, juristische Kommentare — bis das Modell dieses Wissen in seinen Parametern „absorbiert” hat. Stellen Sie es sich vor wie das Auswendiglernen eines sehr dicken, sehr teuren Lehrbuchs.
Das Ergebnis: Das Modell spricht die Sprache des Rechts flüssiger. Es erkennt juristische Fachbegriffe, versteht Argumentationsmuster und produziert Ergebnisse, die Juristen bevorzugen. Harveys Partnerschaft mit OpenAI brachte ein maßgeschneidertes Rechtsprechungsmodell hervor, bei dem Anwälte in 97% der Fälle dessen Ergebnis bevorzugten.
Aber das Wissen ist zum Zeitpunkt des Trainings eingefroren. Es zu aktualisieren bedeutet Neutraining — ein Prozess, der Zehntausende pro Iteration kostet und Wochen bis Monate dauert. Als das belgische Programmgesetz vom Juli 2025 das Investitionsabzugsregime änderte, wusste ein im März 2025 trainiertes Modell davon nichts.
Was RAG wirklich macht
Retrieval-Augmented Generation ändert das Modell nicht. Stattdessen gibt es dem Modell Zugang zu einer durchsuchbaren Wissensbasis. Wenn Sie eine Frage stellen, durchsucht das System zuerst den Corpus, ruft relevante Dokumente ab und sendet diese Dokumente — zusammen mit Ihrer Frage — an das Modell zur Antwortgenerierung.
Stellen Sie sich den Unterschied vor zwischen einem Kollegen, der aus dem Gedächtnis antwortet, und einem, der zuerst in die Bibliothek geht. Die technischen Details — hybride Suche, Autoritätsranking, Cross-Encoder-Reranking — haben wir in unserem Artikel über Such-RAG-Fusion behandelt.
Der entscheidende Vorteil: Wenn sich das Gesetz ändert, aktualisieren Sie den Corpus. Das Modell muss nicht neu trainiert werden. Und weil jede Antwort aus abgerufenen Dokumenten generiert wird, kann jede Behauptung auf eine bestimmte Quelle zurückgeführt werden.
Der Vergleich, der zählt
Das Internet ist voll von Fine-Tuning vs. RAG Vergleichen. Die meisten konzentrieren sich auf Genauigkeit und Kosten. Diese sind wichtig, aber für Rechtsexperten sind sie nicht die entscheidenden Faktoren. Das hier bestimmt wirklich, welche Architektur professionelle Steuerarbeit unterstützt:
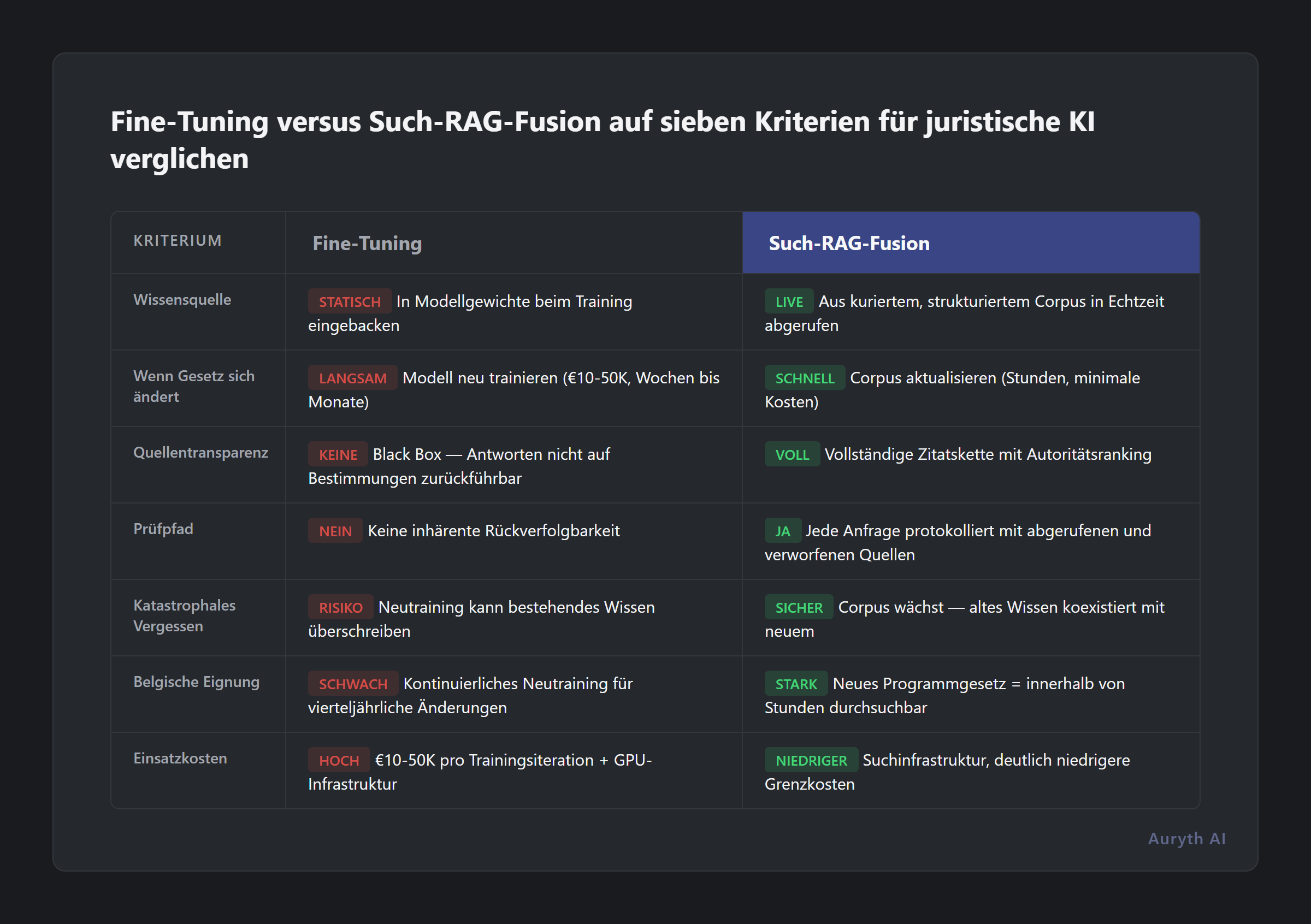
| Kriterium | Fine-Tuning | Such-RAG-Fusion |
|---|---|---|
| Wissensquelle | In Modellgewichte beim Training eingebacken | Aus kuratiertem, strukturiertem Corpus in Echtzeit abgerufen |
| Wenn sich das Gesetz ändert | Modell neu trainieren (10–50k€, Wochen bis Monate) | Corpus aktualisieren (Stunden, minimale Kosten) |
| Quellentransparenz | Black Box — Antworten nicht auf spezifische Bestimmungen zurückführbar | Vollständige Zitatkette mit Autoritätsranking |
| Prüfpfad | Keine inhärente Rückverfolgbarkeit | Jede Anfrage protokolliert mit abgerufenen und verworfenen Quellen |
| Katastrophales Vergessen | Neutraining kann bestehendes Wissen überschreiben | Corpus wächst — altes Wissen koexistiert mit neuem |
| Belgische Eignung | Erfordert kontinuierliches Neutraining für ein vierteljährlich wechselndes Rechtssystem | Neues Programmgesetz = innerhalb von Stunden durchsuchbar |
| Einsatzkosten | 10–50k€ pro Trainingsiteration + GPU-Infrastruktur | Suchinfrastruktur, deutlich niedrigere Grenzkosten |
Die Transparenzzeile sollte Sie innehalten lassen. Ein fine-getuntes Modell, das die richtige Antwort gibt, aber nicht zeigen kann warum — welcher spezifische Artikel, welches Urteil, welches Rundschreiben — versetzt Sie in dieselbe Position wie ein Kollege, der sagt „vertrauen Sie mir, ich erinnere mich.” Berufshaftung verlangt mehr als Gedächtnis.
Warum Harvey Fine-Tuning wählte (und warum das hier nicht gilt)
Harveys Wahl ist logisch für ihren Markt. US- und UK-Recht — insbesondere Rechtsprechung und Vertragsgestaltung — ist relativ stabil. Neutrainingszyklen von Monaten sind akzeptabel, wenn sich das Recht nicht vierteljährlich ändert. Ihr Kundenstamm (Großkanzleien mit Stundensätzen von 500$+) kann die Enterprise-Preise tragen. Und ihr Anwendungsfall (Vertragsüberprüfung, Dokumenterstellung, juristische Memos) profitiert von den Flüssigkeitsvorteilen des Fine-Tuning.
Belgisches Steuerrecht ist ein anderes Tier. Zwei große Programmgesetze pro Jahr. Drei Regionen mit auseinanderlaufenden Regeln. Zwei Amtssprachen mit unterschiedlichen Rechtsterminologien. Ein Reformzyklus, der allein 2025 eine neue Kapitalertragssteuer brachte, das Expatriat-Regime umgestaltete, den Investitionsabzug umstrukturierte und die Veranlagungszeiträume neu schrieb.
Ein im Januar 2025 trainiertes Modell ist im Juli 2025 bereits veraltet. Das ist kein theoretisches Problem. Es ist die Realität der belgischen Steuerpraxis.
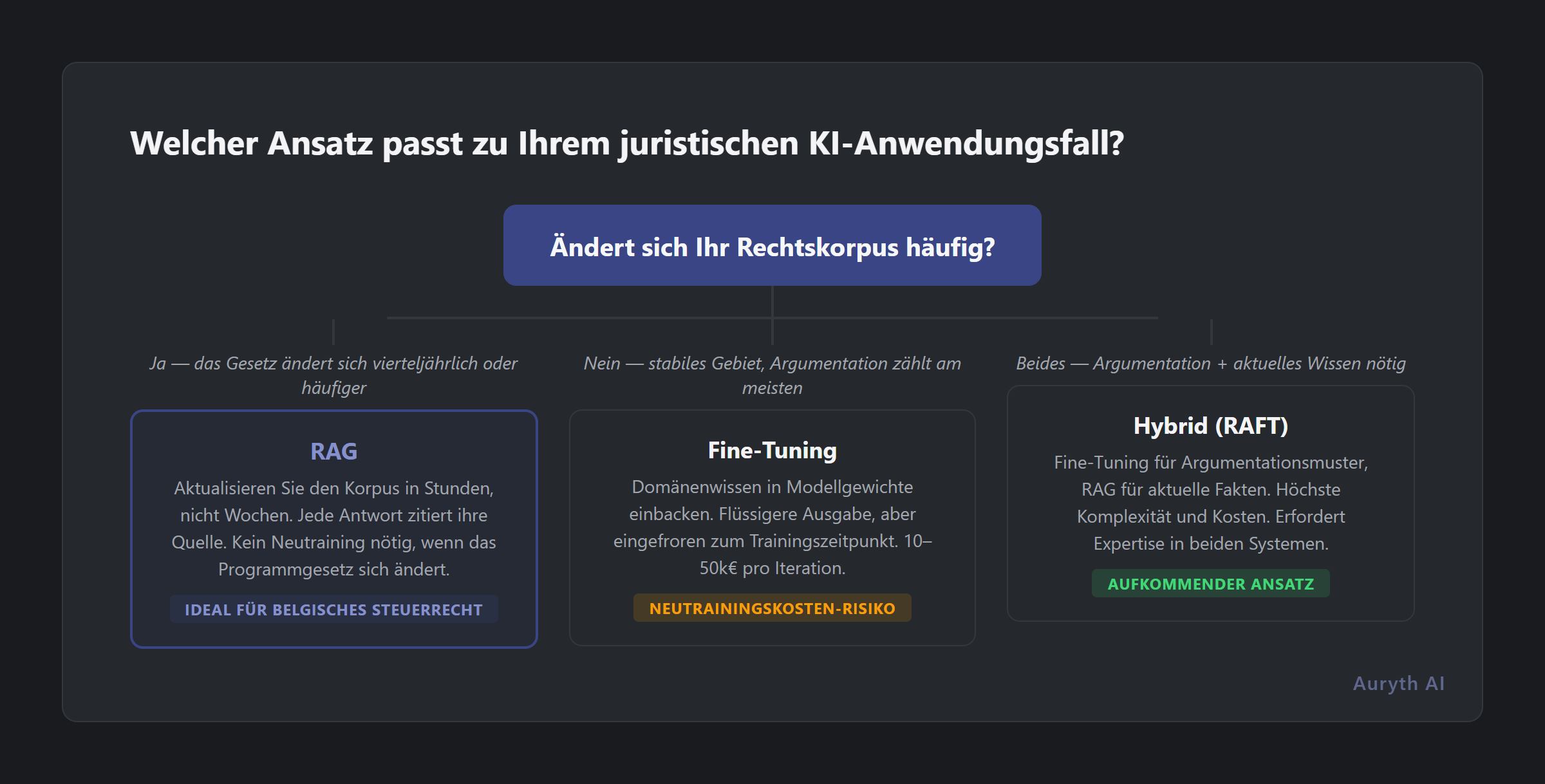
Der Frischetest: Wenn sich Ihr Recht schneller ändert als Ihr Modell neu trainiert, ist Fine-Tuning die falsche Architektur.
Das Hybrid-Argument (und seine Grenzen)
Die ehrliche Antwort ist, dass die Branche sich in Richtung hybrider Ansätze bewegt — Fine-Tuning für Argumentationsmuster, RAG für aktuelles Wissen. Die Forschung nennt dies RAFT (Retrieval-Augmented Fine-Tuning). Die Idee ist solide: Dem Modell durch Fine-Tuning beibringen, wie ein Jurist zu argumentieren, und ihm dann aktuelle Fakten über RAG geben.
Aber hybride Ansätze erben die Komplexität beider Systeme. Sie brauchen Expertise in Modelltraining und Suchinfrastruktur. Sie müssen das Wissen des fine-getunten Modells mit dem Abrufcorpus synchron halten. Und die Kostengleichung verdoppelt sich.
Für belgische Steuer-KI ist die pragmatische Wahl klar: Beginnen Sie mit exzellenter Retrieval-Qualität. Wenn Fine-Tuning für spezifische Argumentationsaufgaben Mehrwert bietet, fügen Sie es selektiv hinzu. Aber Retrieval-Qualität ist das Fundament — ohne sie kann selbst das beste fine-getunte Modell den spezifischen Artikel nicht zitieren, der Ihre Frage beantwortet.
Wo RAG an seine Grenzen stößt
Intellektuelle Ehrlichkeit verlangt, die echten Einschränkungen von RAG anzuerkennen:
Retrieval-Qualität ist die Obergrenze. Wenn der Corpus das richtige Dokument nicht enthält oder die Suchpipeline es nicht nach oben bringt, kann das Modell es nicht nutzen. Fine-getunte Modelle können manchmal per Analogie schlussfolgern, was reine RAG-Systeme schwierig finden.
Weniger flüssig bei spezialisierten Aufgaben. Fine-getunte Modelle produzieren oft poliertere, domänennative Ausgaben. RAG-Systeme generieren Antworten aus abgerufenem Kontext, was im Ton weniger „juristisch” wirken kann.
Pipeline-Komplexität. Eine fünfstufige Such-RAG-Fusionspipeline hat mehr bewegliche Teile als ein einzelner Aufruf eines fine-getunten Modells. Mehr Komponenten bedeutet mehr potenzielle Fehlerpunkte.
Der Kompromiss ist real. Aber für professionelle Steuerrecherche — wo Verifizierbarkeit mehr zählt als Flüssigkeit, und Aktualität mehr als Politur — fällt der Kompromiss zugunsten der Retrieval aus.
Verwandte Artikel
- Was ist RAG — und warum es allein nicht für juristische KI ausreicht
- Warum Transparenz wichtiger ist als Genauigkeit bei juristischer KI
- KI-Halluzinationen: warum ChatGPT Quellen erfindet (und wie Sie das erkennen)
Wie Auryth TX das umsetzt
Auryth TX hat Such-RAG-Fusion gewählt — nicht weil Fine-Tuning schlecht ist, sondern weil belgisches Steuerrecht eine Architektur verlangt, die Schritt halten kann.
Jede Frage durchläuft eine fünfstufige Pipeline: hybride Suche (BM25 + Vektor-Embeddings), Autoritätsranking über die belgische Rechtshierarchie, Cross-Encoder-Reranking, strukturierte Antwortgenerierung mit Quellenangaben pro Behauptung und Zitatvalidierung nach der Generierung. Die Wissensbasis ist der belgische Rechtscorpus — EStGB 92, VCF, Fisconetplus, Vorabentscheidungen, Urteile — alles strukturiert mit zeitlichen Metadaten und Zuständigkeits-Tags.
Als das Programmgesetz vom Juli 2025 das Investitionsabzugsregime umstrukturierte, spiegelte unser Corpus die Änderung innerhalb von Stunden wider. Ein fine-getuntes Modell hätte Neutraining gebraucht. Unseres brauchte ein Corpus-Update.
Wir bitten Sie nicht, dem Gedächtnis des Modells zu vertrauen. Wir bitten Sie, die Quellen zu prüfen, die es abruft. Das ist die Architekturentscheidung, die dies ermöglicht.
Sehen Sie, wie unsere Pipeline echte belgische Steuerfragen bearbeitet — Warteliste beitreten →
Quellen: 1. Harvey AI (2025). „Harvey Raises Series E.” Blog-Ankündigung. 2. Soudani, H., Kanoulas, E. & Hasibi, F. (2024). „Fine Tuning vs. Retrieval Augmented Generation for Less Popular Knowledge.” arXiv:2403.01432. 3. Magesh, V. et al. (2025). „Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools.” Journal of Empirical Legal Studies.