Was ist ein Wissensgraph — und warum er die Art verändert, wie KI sich durch das belgische Steuerrecht navigiert
Eine Suchmaschine findet Text. Ein Wissensgraph navigiert Beziehungen: welcher Artikel welchen ändert, welches Ruling was interpretiert, welche Ausnahme die Regel überschreibt. Das belgische Steuerrecht ist ein Netz von Querverweisen — und ein Wissensgraph ist die Karte.
Von Auryth Team
Stellen Sie eine Frage zum belgischen Steuerrecht und Sie erhalten selten einen einzelnen Artikel als Antwort. Sie erhalten eine Kette.
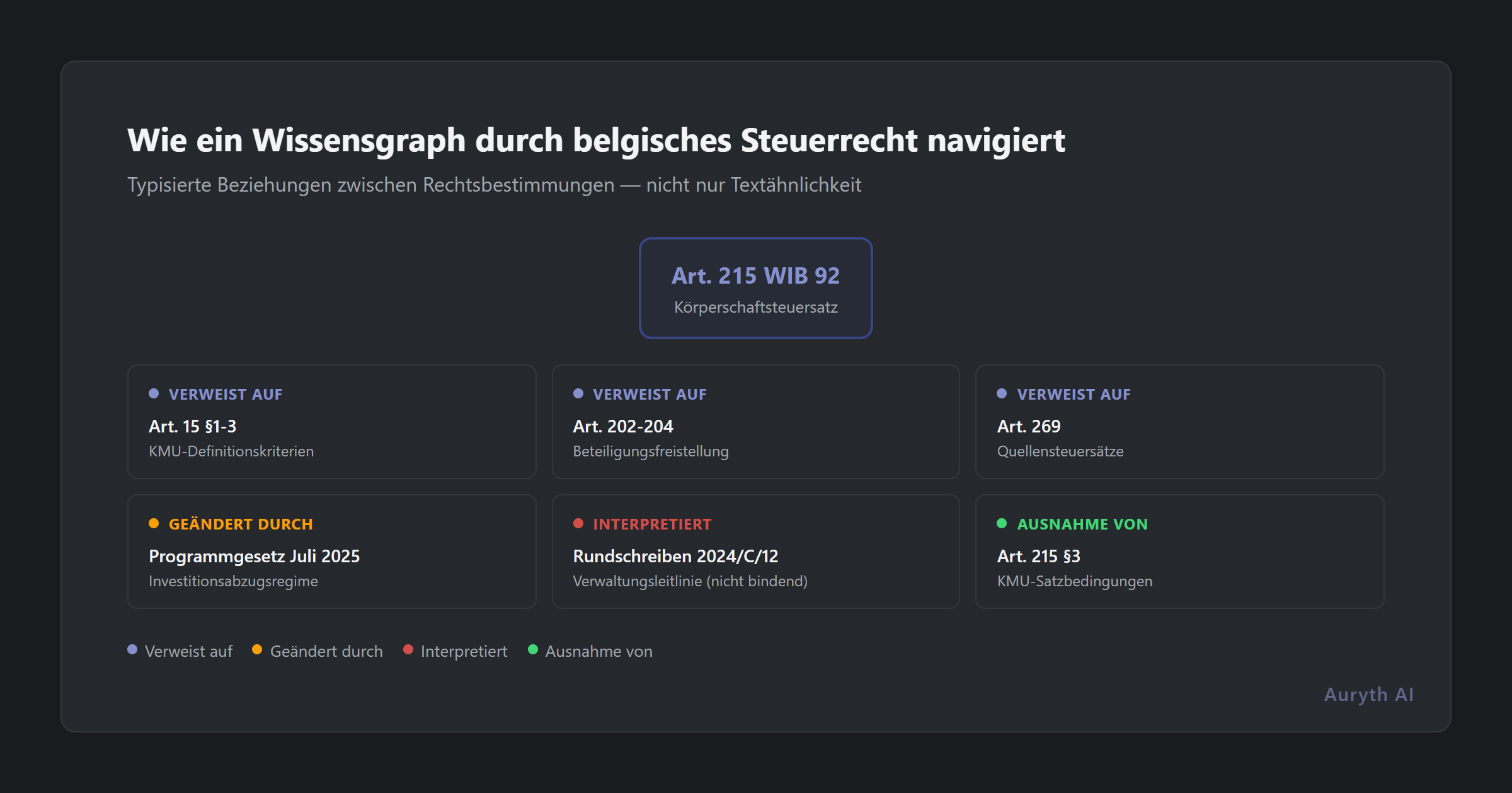
Artikel 215 WIB 92 setzt den Körperschaftsteuersatz auf 25% — verweist aber auf Artikel 185 für das Fremdvergleichsprinzip bei Verrechnungspreisen. Artikel 185 wurde durch das Programmgesetz vom Dezember 2023 geändert, das von einem transaktionalen zu einem kategorischen Ansatz überging. Der ermäßigte KMU-Satz in Artikel 215 selbst erfordert das Erfüllen von Bedingungen, die über die Artikel 15 und 215 §2 verstreut sind. Die in Artikel 269 genannten Quellensteuersätze wurden durch das Programmgesetz vom Juli 2025 geändert. Und jede dieser Bestimmungen wurde durch Verwaltungsrundschreiben interpretiert, die ihren Anwendungsbereich einengen oder erweitern können.
Dies ist keine Ausnahme. So funktioniert das belgische Steuerrecht. Jede Bestimmung existiert in einem Netz von Verweisen, Änderungen, Interpretationen und Ausnahmen. Ein System, das einen Artikel findet, aber seine Verbindungen verpasst, gibt Ihnen ein Fragment, keine Antwort.
Ein Wissensgraph ist die Datenstruktur, die diese Verbindungen erfasst — und er verändert grundlegend, was ein rechtliches KI-System leisten kann.
Was ein Wissensgraph ist
Ein Wissensgraph stellt Informationen als Entitäten dar, die durch typisierte Beziehungen verbunden sind. Das Konzept existiert in der Informatikliteratur seit den 1970er Jahren, wurde aber 2012 zum Mainstream, als Google seinen Knowledge Graph startete, um die Suche von “Schlüsselwörter abgleichen” zu “Dinge verstehen” zu bewegen.
In einem Wissensgraph:
- Entitäten sind die Dinge: Artikel, Gesetze, Rulings, Konzepte, Jurisdiktionen, Zeiträume
- Beziehungen sind die Verbindungen: “ändert”, “interpretiert”, “zitiert”, “Ausnahme_von”, “gilt_für”
- Eigenschaften sind die Attribute: Inkrafttreten, Jurisdiktion, Autoritätsebene, Sprachversion
Der Unterschied zu einer einfachen Datenbank ist strukturell. Eine relationale Datenbank speichert Datensätze in Tabellen mit festen Schemata. Ein Wissensgraph speichert Beziehungen direkt — und kann sie durchlaufen. Fragen Sie “welche Bestimmungen betreffen die Besteuerung von Dividenden einer Tochtergesellschaft?” und der Graph kann der Kette folgen: Artikel 171 (separate Besteuerung) → zitiert Artikel 269 (Quellensteuersätze) → verweist auf die Beteiligungsfreistellung (Artikel 202-204) → die durch das Programmgesetz vom Juli 2025 geändert wurde → das ab dem Steuerjahr 2026 eine Anforderung für finanzielle Anlagevermögen hinzufügte.
Keine Schlüsselwortsuche findet diese Kette. Kein Vektor-Embedding erfasst sie. Die Beziehungen müssen explizit modelliert werden.
Warum das belgische Steuerrecht ein Wissensgraph-Problem ist
Das belgische Steuerrecht hat Eigenschaften, die graphbasierte Navigation nicht nur nützlich, sondern notwendig machen.
Querverweise sind die Norm, nicht die Ausnahme
Ein einzelner belgischer Steuerartikel verweist routinemäßig auf 5-15 andere Bestimmungen. Artikel 215 WIB 92 — ein Artikel über Körperschaftsteuersätze — verweist auf:
- Artikel 15 §1-3 (KMU-Definitionskriterien)
- Artikel 185 §2 (Fremdvergleichsprinzip)
- Artikel 202-204 (Beteiligungsfreistellung)
- Artikel 269 (Quellensteuersätze)
- Artikel 289ter (Steuergutschrift für Geringverdiener)
- Mehrere Bestimmungen der Programmgesetze, die ihn geändert haben
Jeder referenzierte Artikel hat sein eigenes Netz von Verweisen. Der gesamte von Artikel 215 aus erreichbare Graph umspannt Dutzende von Bestimmungen über mehrere Gesetzbücher, legislative Ebenen und Zeiträume hinweg.
Eine Schlüsselwortsuche nach “Körperschaftsteuersatz Belgien” könnte Artikel 215 selbst zurückgeben. Aber die Antwort auf eine echte Beratungsfrage — “qualifiziert die Tochtergesellschaft meines Mandanten für den ermäßigten KMU-Satz?” — erfordert das Durchlaufen des Graphen durch die Artikel 15, 185, 202 und die relevanten Programmgesetzänderungen.
Das Problem der Ausnahmenkette
Die belgische Gesetzgebungstechnik folgt einem charakteristischen Muster:
Allgemeine Regel → vorbehaltlich (behoudens) → es sei denn (tenzij) → sofern (mits)
Diese Ausnahmen leben oft in verschiedenen Artikeln. Die allgemeine Regel für die separate Besteuerung von Dividenden (Artikel 171) hat Ausnahmen in Artikel 171 §2 (globale Einbeziehungsoption). Aber sie interagiert auch mit der Beteiligungsfreistellung (Artikel 202-204), die ihre eigenen Bedingungen, Ausnahmen und zeitlichen Änderungen hat.
In einem flachen Suchindex sind diese Ausnahmen separate Dokumente. In einem Wissensgraph sind sie durch explizite “Ausnahme_von”- und “modifiziert”-Beziehungen verbunden — was es möglich macht, die vollständige Regel mit allen ihren Qualifikationen in einem Durchlauf abzurufen.
Zeitliche Schichtung
Das belgische Steuerrecht wird mindestens zweimal pro Jahr durch Programmgesetze geändert — Omnibus-Gesetzgebung, die Dutzende von Bestimmungen gleichzeitig modifiziert. Das Programmgesetz vom Dezember 2023 allein änderte die Artikel 54, 185/2, 289ter/1, 321quinquies, 321sexies, 321septies und 344 §2 des WIB.
Ein Wissensgraph modelliert dies durch temporale Versionsknoten: jede Bestimmung hat eine Versionsgeschichte, und jede Version zeichnet auf, welches Programmgesetz sie geschaffen hat, wann sie in Kraft trat und was sie ersetzte. Das System speichert nicht nur “Artikel 215 sagt 25%”. Es speichert:
- Artikel 215 (vor 2018): Satz 33,99%
- Artikel 215 (2018-2019): Satz 29,58%, geändert durch Programmgesetz 25. Dezember 2017
- Artikel 215 (2020-heute): Satz 25%, geändert durch Programmgesetz 2. Mai 2019
- Artikel 215 (2026+): Beteiligungsfreistellung geändert, geändert durch Programmgesetz 18. Juli 2025
Jede Version ist ein eigener Knoten, verbunden mit ihrem Vorgänger und Nachfolger, mit der ändernden Gesetzgebung als verbindender Kante.
Mehrstufige Governance
Belgische Steuerbestimmungen existieren auf mehreren Autoritätsebenen, jede mit unterschiedlichem rechtlichen Gewicht:
- EU-Verordnungen und -Richtlinien — direkte Wirkung, überschreiben nationales Recht
- Bundesgesetz (WIB, BTW Code) — primäre Gesetzgebung
- Regionalgesetz (VCF, Code wallon, Brussels tax code) — gleichrangig mit Bundesgesetz für regionalisierte Steuern
- Königliche Erlasse — Durchführungsverordnungen
- Ministerielle Rundschreiben — Verwaltungsinterpretation, nicht bindend für Gerichte
- Vorabentscheidungen — bindend für die Verwaltung im konkreten Fall
- Rechtsprechung — Judikatur von Steuergerichten, Berufungsgerichten, Kassationshof
Ein Wissensgraph erfasst nicht nur den Text auf jeder Ebene, sondern die hierarchischen Beziehungen zwischen ihnen. Wenn ein Rundschreiben Artikel 215 interpretiert, zeichnet der Graph diese Interpretation mit einer “interpretiert”-Kante auf — und kennzeichnet, dass Rundschreiben eine niedrigere Autorität haben als der Artikel selbst. Wenn ein Gerichtsurteil ein Rundschreiben überschreibt, aktualisiert der Graph mit einer “überstimmt”-Kante.
Wie sich dies von der Suche unterscheidet
Die meisten KI-Systeme, einschließlich der meisten rechtlichen KI-Tools, verwenden irgendeine Form der Suche: Schlüsselwortabgleich, semantische Ähnlichkeit oder eine Kombination. Diese Ansätze finden Text, der relevant aussieht. Ein Wissensgraph navigiert Struktur, die relevant ist.
Schlüsselwortsuche findet Dokumente, die die Wörter Ihrer Anfrage enthalten. Sie kann Querverweise nicht durchlaufen — wenn Artikel 215 “Artikel 185” nach Nummer erwähnt, folgt eine Schlüsselwortsuche nach “Verrechnungspreise” diesem Verweis nicht.
Vektor-/semantische Suche findet Dokumente, deren Bedeutung Ihrer Anfrage ähnlich ist. Dies ist leistungsfähig für natürlichsprachliche Fragen, aber begrenzt durch die Grenzen einzelner Chunks. Forschung zu Multi-Hop-Reasoning-Benchmarks zeigt, dass traditionelles RAG oft unter 70% Genauigkeit erreicht, wenn die Antwort das Verbinden von Informationen über mehrere Dokumente erfordert.
Wissensgraph-Traversierung folgt expliziten Beziehungen. Wenn gefragt wird “was sind die Bedingungen für den ermäßigten KMU-Satz?”, beginnt sie bei Artikel 215, folgt der “verweist_auf”-Kante zu Artikel 15 (KMU-Kriterien), folgt der “geändert_durch”-Kante zum relevanten Programmgesetz und gibt die vollständige Kette zurück — nicht weil der Text ähnlich ist, sondern weil die rechtliche Struktur sie verbindet.
Die besten Systeme kombinieren beides: Vektorsuche für die initiale Abfrage, Wissensgraph für strukturiertes Reasoning. Akademische Benchmarks zeigen, dass grapherweiterte Ansätze über 85% Genauigkeit bei Multi-Hop-Aufgaben erreichen können, wo reine Vektoransätze typischerweise deutlich unter dieser Schwelle verbleiben.
Was der Graph möglich macht
Ein Wissensgraph ermöglicht Fähigkeiten, die mit Suche allein strukturell unmöglich sind:
Auswirkungsanalyse. Wenn ein neues Programmgesetz Artikel 215 ändert, kann das System alle Bestimmungen zurückverfolgen, die auf Artikel 215 verweisen, und sie zur Überprüfung kennzeichnen. Dies ist kein Pattern Matching — es ist das Folgen expliziter Kanten im Graphen. Die Änderung des Programmgesetzes vom Juli 2025 an der Beteiligungsfreistellung betrifft jede Bestimmung, die auf die Artikel 202-204 verweist. Der Graph identifiziert sie alle.
Vollständigkeit der Ausnahmen. Beim Abrufen einer Bestimmung kann das System allen “Ausnahme_von”-Kanten folgen, um sicherzustellen, dass die vollständige Regel-plus-Ausnahmen-Kette zurückgegeben wird. Die Antwort auf “wie werden Dividenden besteuert?” ist niemals nur Artikel 171 §1 — sie umfasst §2 (globale Einbeziehungsoption), Artikel 202-204 (Beteiligungsfreistellung) und die 2025er Änderungen der Qualifikationsbedingungen.
Zeitliche Präzision. Eine Anfrage zur Körperschaftsteuer 2019 folgt dem Graph zum Versionsknoten 2018-2019 (29,58%), nicht zur aktuellen Version (25%). Der Graph speichert nicht nur aktuelles Recht — er speichert die vollständige Versionsgeschichte und kann zu jedem Zeitpunkt navigieren.
Autoritätsranking. Wenn mehrere Quellen dieselbe Frage behandeln, ermöglicht die Hierarchie des Graphen prinzipienbasiertes Ranking. Ein Artikel des WIB wiegt schwerer als ein ministerielles Rundschreiben. Ein Kassationshofurteil wiegt schwerer als eine erstinstanzliche Entscheidung. Diese Rankings sind im Graphen als Autoritätsebenen-Eigenschaften auf jedem Knoten kodiert.
Lückenerfassung. Wenn eine Frage eine Bestimmung berührt, die kürzlich geändert wurde, die Interpretationsrundschreiben aber noch nicht aktualisiert wurden, kann der Graph diese Lücke kennzeichnen — die “interpretiert”-Kante vom alten Rundschreiben zeigt auf eine überholte Version des Artikels.
Warum die meisten rechtlichen KI-Tools dies nicht haben
Das Erstellen eines Wissensgraphen für ein Rechtskorpus unterscheidet sich grundlegend vom Indizieren von Dokumenten für die Suche. Die Suche erfordert das Aufteilen von Text in Chunks und deren Einbettung. Ein Wissensgraph erfordert:
- Strukturelles Parsing — Verstehen der hierarchischen Struktur jedes Gesetzbuches (WIB-Artikel, hierarchische Nummerierung des VCF, BTW-Artikel und königliche Erlasse)
- Querverweis-Extraktion — Identifizieren jedes Verweises auf einen anderen Artikel, ein Gesetz oder ein Ruling und Erstellen einer expliziten Kante
- Zeitliche Versionierung — Verfolgen der Änderungsgeschichte und Erstellen von Versionsknoten für jede Änderung
- Autoritätsklassifizierung — Kennzeichnen jeder Quelle mit ihrer Ebene in der rechtlichen Hierarchie
- Beziehungstypisierung — Unterscheiden zwischen “ändert”, “interpretiert”, “zitiert”, “Ausnahme_von” und anderen Beziehungstypen
Dies ist strukturierte Aufnahme, kein Dokumentendumping. Es erfordert domänenspezifisches Parsing für jedes Gesetzbuch und jeden Dokumenttyp. Die charakteristische Nummerierung des VCF (Artikel 2.10.4.0.1) erfordert ein anderes Parsing als die traditionelle Artikel-und-Paragraph-Struktur des WIB. Programmgesetze erfordern Änderungsverfolgungs-Logik, die den ändernden Artikel mit jeder von ihm modifizierten Bestimmung verbindet.
Universelle KI-Tools — ChatGPT, Copilot, Gemini — haben diese Struktur nicht. Sie verarbeiten rechtlichen Text als undifferenzierten Text. Sie können Passagen finden, die relevant aussehen, aber sie können nicht die Kette von Querverweisen, Änderungen und Ausnahmen zurückverfolgen, die eine Bestimmung mit Dutzenden anderen verbindet.
Selbst die meisten rechtlichen KI-Tools verwenden Dokumentensuche statt Graph-Navigation. Thomson Reuters und LexisNexis haben massiv in Wissensgraph-Technologie für ihre Plattformen investiert, aber dies sind Enterprise-Systeme, die für große internationale Kanzleien bepreist sind. Der belgische Markt — kleineres Korpus, drei Regionen, zwei Amtssprachen — hat traditionell nicht diese Höhe struktureller Investition gerechtfertigt.
Wonach Sie suchen sollten
Bei der Evaluierung eines rechtlichen KI-Tools offenbart sich die An- oder Abwesenheit eines Wissensgraphen in spezifischen Fähigkeiten:
-
Kann das Tool Querverweise zurückverfolgen? Stellen Sie eine Frage, die das Folgen einer Kette erfordert: “Welche Bedingungen muss mein Unternehmen für den ermäßigten Körperschaftsteuersatz erfüllen?” Wenn die Antwort Artikel 215, aber nicht Artikel 15 (KMU-Definition) zitiert, sucht das Tool, navigiert aber nicht.
-
Kennzeichnet das Tool Änderungen? Wenn Sie nach einer Bestimmung fragen, die kürzlich durch ein Programmgesetz geändert wurde, weiß das Tool von der Änderung? Wenn es veralteten Text ohne Kennzeichnung der Änderung zurückgibt, ist die Änderungskette nicht modelliert.
-
Kann das Tool Autoritätsebenen unterscheiden? Stellen Sie eine Frage, bei der ein ministerielles Rundschreiben einem Gerichtsurteil widerspricht. Wenn das Tool beide als gleich autoritativ präsentiert, hat es kein Hierarchiemodell — was bedeutet: keinen Graphen.
-
Kann Ihnen das Tool die Verbindungen zeigen? Ein Tool, das auf einem Wissensgraph aufbaut, kann Ihnen zeigen, welche Bestimmungen sich mit Ihrer Antwort verbinden und wie. Ein Tool, das auf Suche aufbaut, kann Ihnen nur den Text zeigen, den es gefunden hat.
Der Graph ist das, was eine Sammlung von Rechtsdokumenten in eine navigierbare Karte des Rechts verwandelt.
Verwandte Artikel
- Was ist Chunking — und warum es das unsichtbare Fundament der Qualität rechtlicher KI ist →
- Was ist Authority Ranking — und warum Ihr rechtliches KI-Tool es wahrscheinlich ignoriert →
- Was ist temporale Versionierung — und warum Ihr rechtliches KI-Tool Ihnen wahrscheinlich gestriges Recht serviert →
Wie Auryth TX dies anwendet
Auryth TX durchsucht keine Dokumente — es navigiert einen Wissensgraph des belgischen Steuerrechts.
Jeder Artikel im WIB, BTW Code, VCF und den regionalen Codes ist ein Knoten im Graph. Jeder Querverweis ist eine Kante. Jede Programmgesetzänderung erstellt einen temporalen Versionsknoten, der mit den von ihr geänderten Bestimmungen verbunden ist. Jedes Rundschreiben, Ruling und Gerichtsurteil ist mit den Bestimmungen verbunden, die es interpretiert, mit seiner Autoritätsebene explizit modelliert.
Wenn Sie fragen “wie werden Dividenden einer Tochtergesellschaft besteuert?”, findet das System nicht nur Artikel 171. Es durchläuft: Artikel 171 (separate Besteuerung) → Artikel 202-204 (Beteiligungsfreistellung) → Programmgesetz Juli 2025 (Anforderung für finanzielle Anlagevermögen) → Artikel 269 (Quellensteuersätze) — und gibt die vollständige Kette mit zeitlichem Kontext, Autoritätsranking und Vollständigkeit der Ausnahmen zurück.
Der Domain-Radar in jedem Rechercheergebnis ist eine direkte Visualisierung dieses Graphen: er zeigt, welche Steuerdomänen sich mit Ihrer Frage verbinden, welche Bestimmungen gelten und wie sie zueinander in Beziehung stehen. Die Verbindungen sind nicht aus Textähnlichkeit abgeleitet. Sie sind strukturell — weil sie aus dem Gesetz selbst geparst, extrahiert und modelliert wurden.
Keine Suche. Navigation. Jeder Querverweis zurückverfolgt. Jede Änderung verlinkt. Jede Ausnahme verbunden.
Quellen: 1. Google (2012). “Introducing the Knowledge Graph: things, not strings.” Official Google Blog. 2. Hogan, A. et al. (2021). “Knowledge Graphs.” ACM Computing Surveys, 54(4), Article 71. 3. LexisNexis (2025). “Legal AI Software Company Evaluation Report.” GlobeNewswire. 4. de Martim, H. (2025). “An Ontology-Driven Graph RAG for Legal Norms.” arXiv:2505.00039. 5. Barron, A. et al. (2025). “Bridging Legal Knowledge and AI: RAG with Vector Stores, Knowledge Graphs.” ICAIL 2025. 6. EUR-Lex (2023). “European Legislation Identifier (ELI).” eur-lex.europa.eu.