Ce que l'étude Stanford sur les hallucinations a vraiment révélé — et pourquoi la réaction de l'industrie a raté l'essentiel
Stanford a découvert que les outils d'IA juridique premium hallucinent 17-33% du temps. Mais la découverte la plus dangereuse était le misgrounding.
Par Auryth Team
L’erreur d’IA la plus dangereuse n’est pas celle qui est manifestement fausse. C’est celle qui semble parfaitement correcte.
En mai 2024, des chercheurs du Stanford RegLab ont publié la première évaluation empirique préenregistrée d’outils d’IA juridique commerciaux (Magesh et al., 2024). Ils ont testé Lexis+ AI, Ask Practical Law AI et plus tard Westlaw AI-Assisted Research sur 202 requêtes juridiques, évaluées manuellement par des experts juridiques. Le constat principal — des taux d’hallucination de 17 à 33 % — a choqué le secteur. Mais la découverte qui aurait dû inquiéter le plus les professionnels a reçu bien moins d’attention.
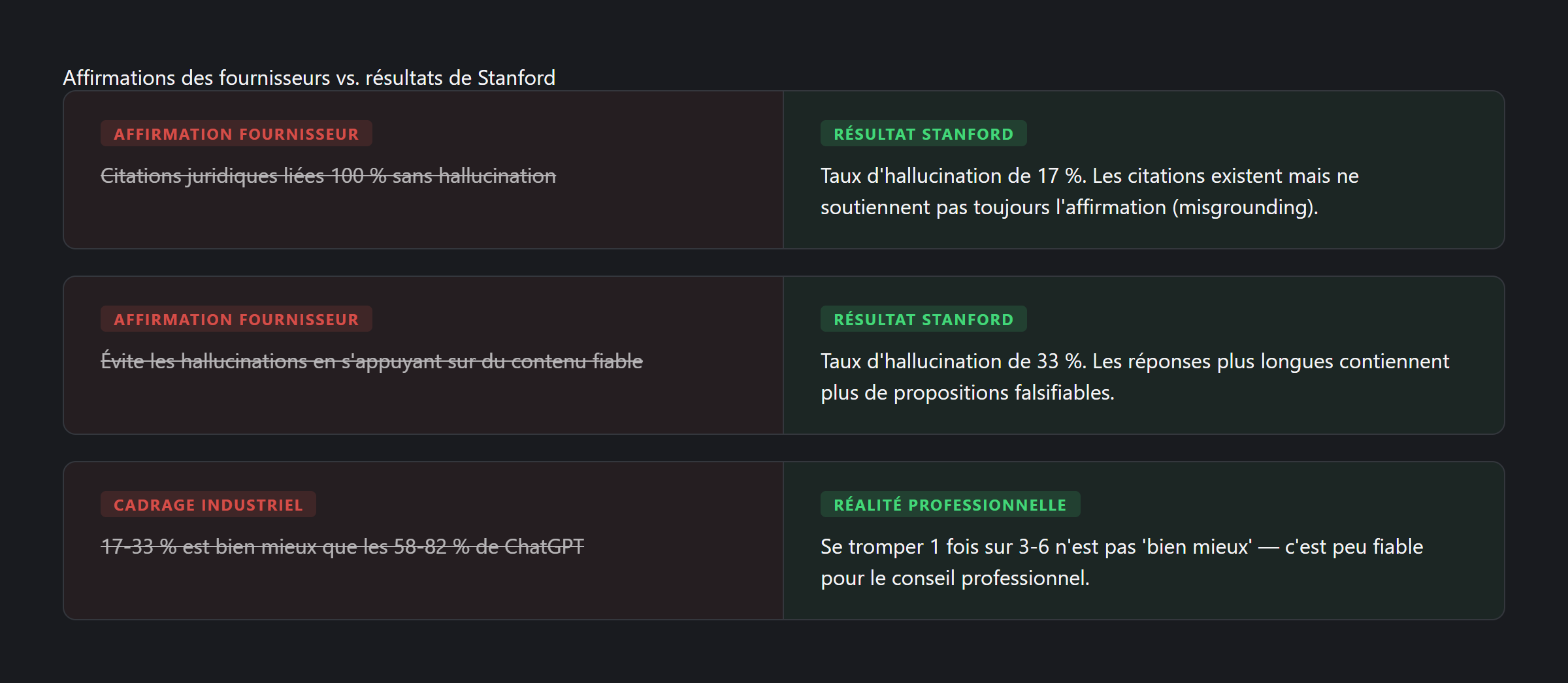
Ce que Stanford a réellement trouvé
Les chiffres sont édifiants :
| Outil | Précis | Incomplet | Halluciné |
|---|---|---|---|
| Lexis+ AI | 65 % | 18 % | 17 % |
| Ask Practical Law AI | 19 % | 62 % | 17 % |
| Westlaw AI-Assisted Research | 42 % | 25 % | 33 % |
| GPT-4 (référence, étude antérieure) | — | — | 58–82 % |
Ce sont des outils commercialisés à des milliers d’euros par mois à des professionnels qui s’y fient pour des conseils aux clients. La conclusion des chercheurs de Stanford était sans équivoque : « Les affirmations des fournisseurs sont exagérées. »
Le misgrounding : la découverte que tout le monde a manquée
La fabrication est ce que la plupart des gens imaginent quand ils entendent « hallucination de l’IA ». L’IA invente un cas qui n’existe pas. Ce type d’erreur est gênant mais détectable.
Le misgrounding est plus subtil et plus dangereux. L’IA décrit le droit correctement, cite un cas réel qui existe véritablement, mais le cas cité ne soutient pas l’affirmation faite. La citation est valide. L’énoncé juridique semble correct. Mais la source ne dit pas ce que l’IA prétend qu’elle dit.
Cela survit au contrôle superficiel. La citation est vérifiable — le cas est réel. La proposition juridique semble juste. Un professionnel pressé qui clique vers la source pourrait parcourir le sommaire et passer à la suite.
La citation la plus dangereuse est celle qui existe mais ne dit pas ce que vous pensez qu’elle dit.
Le sophisme du « mieux que ChatGPT »
La réponse dominante de l’industrie : « 17-33 % est dramatiquement mieux que les 58-82 % de ChatGPT. Le RAG fonctionne. »
Ce cadrage est erroné. Comparer un outil professionnel premium à un chatbot grand public gratuit est comme comparer le bilan sécurité d’une compagnie aérienne à celui d’un vélo. La question pertinente n’est pas « est-ce mieux que ChatGPT ? » mais « est-ce suffisamment fiable pour la pratique professionnelle ? »
Retiendriez-vous un collaborateur junior qui se trompe 1 fois sur 3 à 6 ? En médecine, un outil diagnostique avec 17-33 % d’erreurs ne serait jamais commercialisé comme « sans hallucination ».
Ce que cela signifie pour les fiscalistes belges
Le droit fiscal belge est précisément le domaine où ces modes de défaillance sont les plus dangereux — multi-juridictionnel (fédéral/régional), fréquemment amendé, hiérarchies d’autorité complexes.
Confusion juridictionnelle. Un outil qui confond les dispositions fédérales du CIR 92 avec les dispositions flamandes du VCF produit exactement le type de sortie misgrounded identifié par Stanford.
Violations de la hiérarchie d’autorité. Une circulaire du SPF Finances n’a pas le même poids juridique qu’un article de loi ou un arrêt de la Cour de cassation.
Application temporelle erronée. Le droit fiscal belge change fréquemment. Un outil qui retrouve un principe juridique correct mais d’une version dépassée de la loi produit un conseil qui était juste l’année dernière mais faux aujourd’hui.
Le paradoxe de la vérification
Si chaque citation générée par l’IA doit être vérifiée manuellement contre la source primaire, quel est exactement le gain de temps ? La valeur n’est pas « moins de vérification ». C’est « chercher plus largement, vérifier ce que l’outil remonte, et capter des connexions qu’on aurait manquées manuellement ».
Questions fréquentes
L’étude Stanford signifie-t-elle que les outils d’IA juridique sont inutiles ?
Non. Elle signifie que leur précision est inférieure à ce que les fournisseurs affirmaient, et que la vérification professionnelle reste essentielle.
Pourquoi Westlaw a-t-il un taux d’hallucination plus élevé que Lexis ?
Les chercheurs attribuent cela en partie à la longueur des réponses. Westlaw génère des réponses plus longues et détaillées — contenant plus de propositions falsifiables.
Articles connexes
- Hallucinations de l’IA : pourquoi ChatGPT fabrique des sources → /fr/blog/hallucinations-ia-fiscal/
- Pourquoi la transparence compte plus que la précision → /fr/blog/transparence-vs-precision/
- Qu’est-ce que le scoring de confiance → /fr/blog/scoring-confiance-explique/
Comment Auryth TX applique ceci
Auryth TX adresse les trois modes de défaillance identifiés par l’étude Stanford. Chaque réponse inclut des citations de sources liées aux dispositions, décisions ou commentaires spécifiques qui soutiennent la réponse. Les scores de confiance indiquent dans quelle mesure les sources retrouvées soutiennent la réponse générée.
Nous ne prétendons pas être sans hallucination. Nous prétendons être transparents sur ce que nous savons, ce dont nous sommes incertains et où le jugement professionnel de l’utilisateur est essentiel.
Sources : 1. Magesh, V. et al. (2024). « Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools ». Journal of Empirical Legal Studies, 2025. 2. Dahl, M. et al. (2024). « Large Legal Fictions: Profiling Legal Hallucinations in Large Language Models ». Journal of Legal Analysis, 16(1), 64-93. 3. Farquhar, S. et al. (2024). « Detecting hallucinations in large language models using semantic entropy ». Nature, 630, 625-630.