Wat is confidence scoring — en waarom is het eerlijker dan een zelfzeker antwoord
LLM's overschatten hun eigen correctheid met 20-60%. Confidence scoring lost dat probleem niet op — het maakt het zichtbaar. Voor fiscalisten is die zichtbaarheid het verschil tussen een onderzoekstool en een gokmachine.
Door Auryth Team
Stel ChatGPT een Belgische fiscale vraag en u krijgt een helder, goed gestructureerd, gezaghebbend klinkend antwoord. Stel het een vraag waarop het onmogelijk het antwoord kan weten, en u krijgt exact dezelfde toon. Dezelfde structuur. Dezelfde zekerheid. Geen enkel signaal dat het tweede antwoord is verzonnen.
Dit is geen bug. Het is hoe taalmodellen werken. Ze zijn getraind om vloeiende, zelfverzekerde tekst te produceren — niet om u te vertellen wanneer ze gissen. Onderzoek naar vijf grote LLM’s toont aan dat ze de waarschijnlijkheid dat hun antwoorden correct zijn met 20 tot 60 procent overschatten. Hoe moeilijker de vraag, hoe slechter de kalibratie wordt.
Voor een fiscalist is deze uniforme zekerheid de gevaarlijkste eigenschap van AI-tools. Het betekent dat het systeem een goed onderbouwd antwoord — ondersteund door drie arresten van het Hof van Cassatie en een duidelijke wettelijke bepaling — identiek behandelt aan een antwoord dat het heeft verzonnen uit patronen in zijn trainingsdata. U krijgt geen signaal. U kunt het verschil niet zien zonder elk antwoord zelf te controleren.
Confidence scoring is het architecturale antwoord op dit probleem. Geen oplossing — een signaal.
Wat confidence scoring eigenlijk meet
Een confidence score is een numerieke indicator die u vertelt hoe goed een antwoord is onderbouwd — niet door de interne zekerheid van het model (die onbetrouwbaar is), maar door het bewijs dat het systeem heeft gevonden.
In een goed ontworpen systeem heeft confidence twee dimensies:
Source coverage — hoeveel relevante bronnen heeft het systeem gevonden? Heeft het wettelijke bepalingen, rechtspraak en administratieve omzendbrieven opgehaald? Of heeft het één marginaal gerelateerd document gevonden?
Reasoning certainty — hoe duidelijk ondersteunen de opgehaalde bronnen de conclusie? Zijn ze het eens? Spreken ze elkaar tegen? Behandelen ze de exacte vraag, of alleen een gerelateerde?
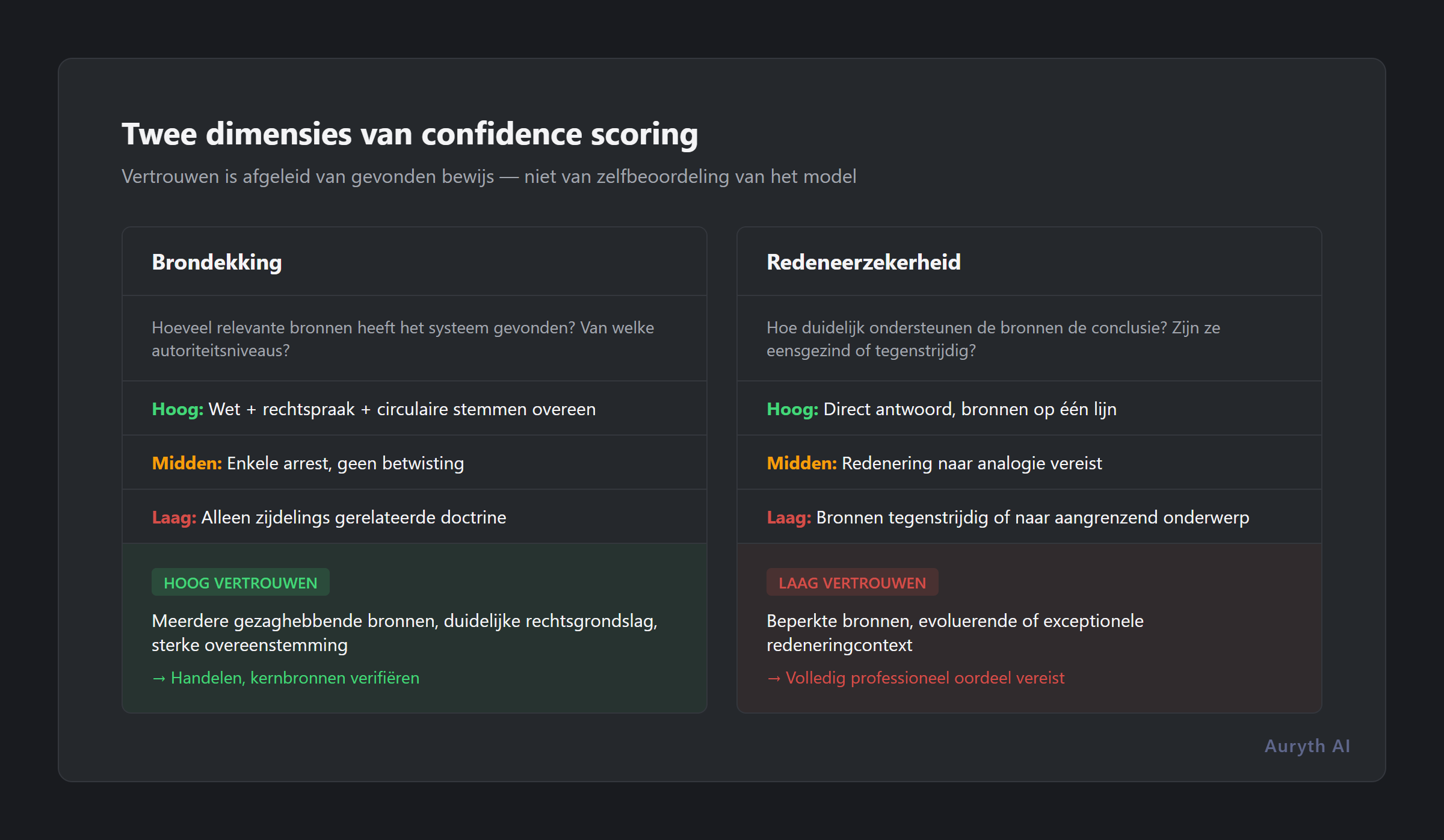
Een antwoord met hoge confidence ziet er zo uit: “Op basis van art. 21 WIB 92, bevestigd door het arrest van het Hof van Cassatie van 12 maart 2024 en consistent met Fisconetplus-omzendbrief 2025/C/71, bedraagt de roerende voorheffing op dividenden 30%.” Meerdere gezaghebbende bronnen. Duidelijke juridische basis. Sterke consensus.
Een antwoord met lage confidence ziet er zo uit: “Op basis van één DVB-voorafgaande beslissing uit 2022 komt deze structuur mogelijk in aanmerking voor de deelnemingsvrijstelling, hoewel geen rechtspraak werd gevonden die deze specifieke configuratie behandelt.” Enkele bron. Geen bevestiging. Analogische redenering.
Beide antwoorden kunnen correct zijn. Maar ze vereisen zeer verschillende niveaus van professionele controle. Zonder een confidence-signaal zien ze er identiek uit.
Waarom LLM’s systematisch te zelfverzekerd zijn
Het probleem van overconfidence is geen beperking die in de volgende modelversie zal worden opgelost. Het is structureel.
Taalmodellen worden getraind via reinforcement learning from human feedback (RLHF), waarbij menselijke beoordelaars de kwaliteit van antwoorden beoordelen. Zelfverzekerde, goed gestructureerde antwoorden krijgen consequent hogere beoordelingen dan voorzichtige, onzekere antwoorden — zelfs wanneer beide even nauwkeurig zijn. Het trainingsproces leert modellen letterlijk dat zekerheid wordt beloond.
Onderzoek toont aan dat reward models die worden gebruikt in RLHF inherente vooroordelen vertonen naar hoge confidence scores, ongeacht de werkelijke kwaliteit van het antwoord. Het model leert: zelfverzekerd klinken levert betere scores op. Dus klinkt het zelfverzekerd — of dat nu zou moeten of niet.
De kalibratiecijfers bevestigen dit. Expected Calibration Errors bij geteste LLM’s variëren van 0,108 tot 0,427 — wat betekent dat de kloof tussen aangegeven zekerheid en werkelijke nauwkeurigheid aanzienlijk is. Grotere modellen kalibreren iets beter, maar zelfs de beste modellen blijven significant te zelfverzekerd bij taken die domeinexpertise vereisen.
Wanneer een AI-systeem zegt “Ik ben zeker,” zegt die uitspraak niets over nauwkeurigheid. Het zegt iets over trainingsincentives.
Wat uniforme zekerheid kost in de praktijk
Neem een Belgische fiscalist die twee vragen stelt:
Vraag A: “Wat is het standaard vennootschapsbelastingtarief voor kmo’s in België?”
Vraag B: “Kan een Belgische inwoner die cryptocurrency overmaakt naar een buitenlandse exchange en vervolgens omzet in stablecoins de vrijstelling voor ‘normaal beheer van privévermogen’ claimen onder art. 90 WIB 92?”
Een algemene LLM beantwoordt beide met dezelfde gezaghebbende toon. Dezelfde opmaak. Dezelfde zekerheid. Maar vraag A heeft een eenvoudig, goed gedocumenteerd antwoord (20% op de eerste €100.000 voor kwalificerende kmo’s onder art. 215 WIB 92). Vraag B bevindt zich op het kruispunt van snel evoluerend fiscaal beleid, beperkte rechtspraak en administratieve standpunten die variëren per aanslagjaar.
Zonder confidence scoring moet de fiscalist hetzelfde verificatieniveau toepassen op beide antwoorden. Met confidence scoring markeert het systeem vraag A als hoge confidence (meerdere duidelijke autoriteiten) en vraag B als lage confidence (beperkte autoriteiten, evoluerend beleidsgebied, analogische redenering vereist). De fiscalist kan controle toewijzen waar het ertoe doet.
Die toewijzing is geen luiheid — het is de definitie van efficiënte professionele praktijk.
Het verschil tussen model confidence en evidence confidence
Hier is een onderscheid dat de meeste AI-uitleggers missen: er zijn twee volledig verschillende soorten “confidence” in AI-systemen, en slechts één ervan is nuttig.
Model confidence is de waarschijnlijkheid die het taalmodel toekent aan zijn eigen output tokens. Dit is wat intern beschikbaar is in elke LLM. Onderzoek toont aan dat het slecht gekalibreerd is en systematisch te zelfverzekerd. Het vertelt u hoe “verwacht” de woordkeuzes van het model zijn — niet of het antwoord correct is.
Evidence confidence is afgeleid van de retrieval pipeline — hoeveel bronnen werden gevonden, hoe gezaghebbend ze zijn, hoe direct ze de vraag behandelen, en of ze het eens zijn. Dit is extern aan het model. Het is gebaseerd op verifieerbare feiten over wat het systeem heeft gevonden, niet op de zelfevaluatie van het model.
Een nuttig confidence scoring-systeem gebruikt evidence confidence, niet model confidence. De score moet u vertellen: “We hebben drie wettelijke bepalingen, twee arresten en een omzendbrief gevonden die uw vraag direct behandelen, en ze zijn het eens” — niet “het model is voor 87% zeker over zijn woordkeuzes.”
Wat confidence scoring niet kan doen
Intellectuele eerlijkheid vereist erkenning van de grenzen:
Het kan onbekende onbekenden niet vangen. Als de relevante bepaling niet in het corpus zit, kan het systeem een plausibel antwoord teruggeven uit aangrenzende bronnen — met gematigde confidence. De confidence score weerspiegelt wat werd gevonden, niet wat bestaat.
Sommige onzekerheid weerstaat kwantificering. Een recent paper in het tijdschrift van de Royal Statistical Society stelt dit direct: “Veel consequente vormen van onzekerheid in professionele contexten weerstaan kwantificering.” Of een fiscale structuur kwalificeert als “normaal beheer van privévermogen” is geen confidence score-probleem — het is een professioneel oordeel-probleem. Het systeem kan u de bronnen tonen. De interpretatie is van u.
Confidence scores kunnen valse precisie creëren. Een score van 0,73 versus 0,71 is betekenisloze ruis. Wat ertoe doet is het categorische signaal: hoge confidence (sterk bewijs, handel ernaar), gematigde confidence (enig bewijs, verifieer de belangrijkste bronnen), lage confidence (dun bewijs, dit vereist uw volledige professionele oordeel).
Het juiste ontwerp vermijdt valse precisie door te communiceren in banden, niet in decimalen.
Gerelateerde artikels
- Waarom transparantie belangrijker is dan nauwkeurigheid in juridische AI
- AI-hallucinaties: waarom ChatGPT bronnen verzint (en hoe u het herkent)
- Hoe een juridische AI-tool evalueren: 10 vragen die er echt toe doen
Hoe Auryth TX dit toepast
Elk antwoord in Auryth TX draagt een confidence score — niet afgeleid van model-zelfevaluatie, maar van de retrieval pipeline.
De score weerspiegelt drie bewijsdimensies: bron aantal en autoriteit (hoeveel relevante bronnen, en wat is hun juridisch gewicht), directheid (behandelen de bronnen uw exacte vraag of alleen een gerelateerde), en consensus (zijn de bronnen het eens, of is er een conflict dat professionele interpretatie vereist).
Wanneer de confidence hoog is, ziet u het antwoord met zijn ondersteunende bronnen en kunt u efficiënt verder gaan. Wanneer de confidence laag is, vertelt het systeem u dat expliciet — en toont het u wat het wel vond, waar het naar zocht en niet vond (negatieve retrieval), en waar de hiaten in autoriteit liggen.
We doen niet alsof elk antwoord even betrouwbaar is. We geven u het signaal dat u nodig hebt om uw professioneel oordeel toe te wijzen waar het het meest ertoe doet.
Bronnen: 1. Cash, T.N. et al. (2025). “Quantifying uncert-AI-nty: Testing the accuracy of LLMs’ confidence judgments.” Memory & Cognition. 2. Leng, J. et al. (2025). “Taming Overconfidence in LLMs: Reward Calibration in RLHF.” ICLR 2025. 3. Steyvers, M. et al. (2025). “What Large Language Models Know and What People Think They Know.” Nature Machine Intelligence. 4. Delacroix, S. et al. (2025). “Beyond Quantification: Navigating Uncertainty in Professional AI Systems.” RSS: Data Science and Artificial Intelligence.