Wat de Stanford hallucinatiestudie echt onthulde — en waarom de reactie van de sector het punt miste
Stanford vond dat premium juridische AI-tools in 17-33% van de gevallen hallucineren. Maar de gevaarlijkste bevinding was niet het percentage — het was misgrounding.
Door Auryth Team
De gevaarlijkste AI-fout is niet degene die overduidelijk verkeerd is. Het is degene die er precies goed uitziet.
In mei 2024 publiceerden onderzoekers van Stanford RegLab de eerste gepreregistreerde empirische evaluatie van commerciële juridische AI-tools (Magesh et al., 2024). Ze testten Lexis+ AI, Ask Practical Law AI en later Westlaw AI-Assisted Research op 202 juridische vragen, handmatig beoordeeld door juridische experts. De kopbevinding — hallucinatiepercentages van 17–33% — schokte de sector. Maar de bevinding die professionals het meest had moeten verontrusten, kreeg veel minder aandacht.
Wat Stanford werkelijk vond
De cijfers zijn ontnuchterend:
| Tool | Accuraat | Onvolledig | Gehallucineerd |
|---|---|---|---|
| Lexis+ AI | 65% | 18% | 17% |
| Ask Practical Law AI | 19% | 62% | 17% |
| Westlaw AI-Assisted Research | 42% | 25% | 33% |
| GPT-4 (referentie, eerdere studie) | — | — | 58–82% |
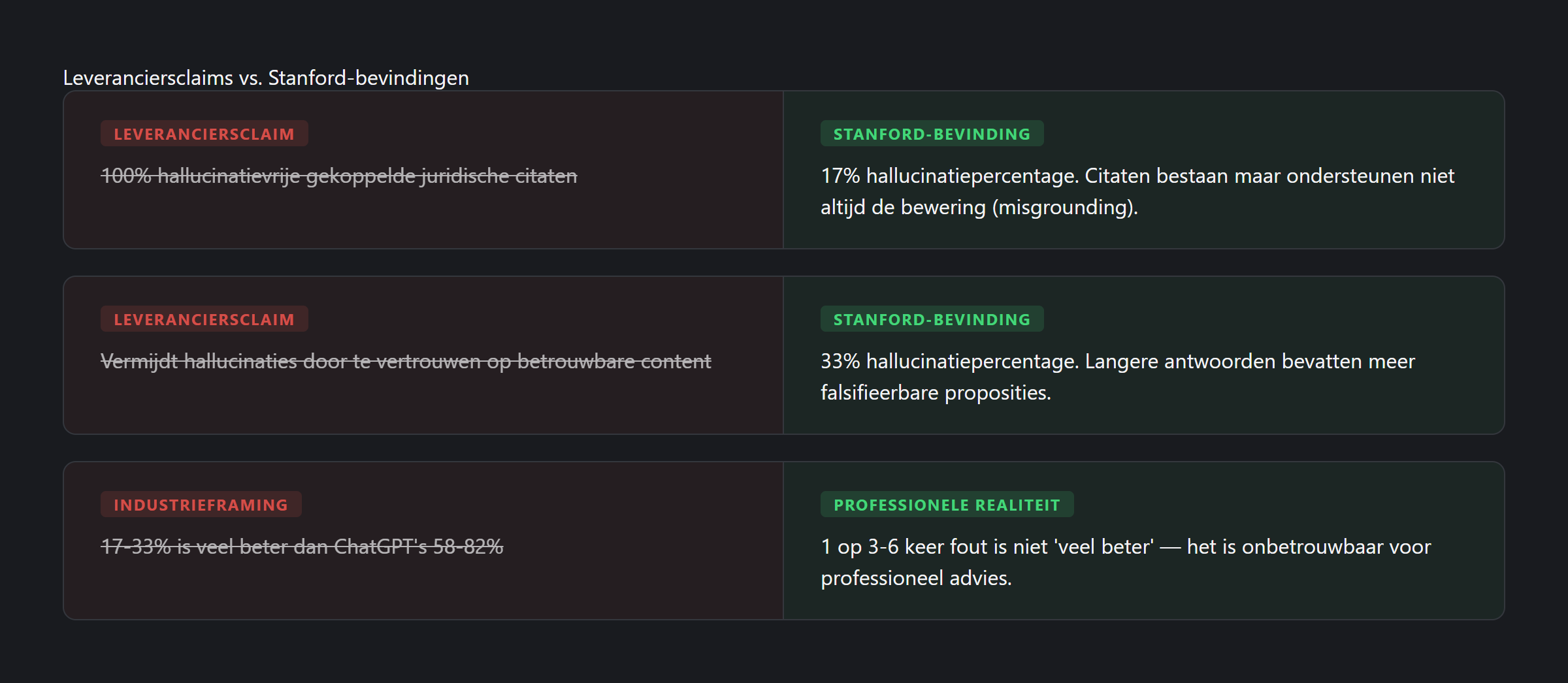
Dit zijn tools die voor duizenden euro’s per maand worden verkocht aan professionals die erop vertrouwen voor cliëntadvies. LexisNexis had “100% hallucinatievrije gekoppelde juridische citaten” beloofd. Thomson Reuters beweerde dat hun tools “hallucinaties vermijden door te steunen op betrouwbare content.”
De conclusie van de Stanford-onderzoekers was onomwonden: “De claims van leveranciers zijn overdreven.”
Misgrounding: de bevinding die iedereen miste
De studie introduceerde een taxonomie die hallucinaties opsplitst in afzonderlijke faalmodi. Het belangrijkste onderscheid: het verschil tussen fabricatie en misgrounding.
Fabricatie is wat de meeste mensen denken bij “AI-hallucinatie.” De AI verzint een zaak die niet bestaat — zoals in het Mata v. Avianca-incident, waar advocaten een conclusie indienden met volledig fictieve zaakreferenties gegenereerd door ChatGPT. Dit soort fouten is gênant maar vindbaar. Een snelle zoekopdracht onthult dat de zaak niet bestaat.
Misgrounding is subtieler en gevaarlijker. De AI beschrijft het recht correct, citeert een echte zaak die daadwerkelijk bestaat, maar de geciteerde zaak ondersteunt de gedane bewering niet. De citatie is geldig. De juridische stelling klinkt correct. Maar de bron zegt niet wat de AI beweert dat het zegt.
Dit overleeft oppervlakkige controle. De citatie klopt — de zaak is echt. De juridische propositie klinkt juist. Een professional onder tijdsdruk die naar de bron doorklikt, de samenvatting leest, het juiste rechtsgebied ziet en verder gaat. De misgrounding overleeft omdat het eruitziet als goed onderzoek.
De gevaarlijkste citatie is degene die bestaat maar niet zegt wat u denkt dat het zegt.
De “beter dan ChatGPT”-denkfout
De dominante reactie van de sector was voorspelbaar: “17–33% is dramatisch beter dan ChatGPT’s 58–82%. RAG werkt.”
Deze framing is om drie redenen fout.
De referentie is betekenisloos. Een premium professionele tool vergelijken met een gratis consumentenchatbot is als de veiligheid van een commerciële vliegmaatschappij vergelijken met die van een fiets. De relevante vraag is niet “is het beter dan ChatGPT?” maar “is het betrouwbaar genoeg voor professionele praktijk?”
De lat ligt te laag. Zou u een junior medewerker behouden die 1 op 3-6 antwoorden fout heeft? Zou u een fiscalist vertrouwen wiens citaten een derde van de tijd niet kloppen? In de geneeskunde zou een diagnostisch instrument met 17–33% foutpercentages nooit worden verkocht als “hallucinatievrij.”
Het lange-antwoord versterkingseffect. Stanford vond dat Westlaws hogere hallucinatiepercentage correleerde met langere antwoorden — gemiddeld 350 woorden versus 219 voor Lexis. Meer woorden betekent meer falsifieerbare proposities, wat meer kansen op fouten betekent.
Wat dit betekent voor Belgische fiscalisten
Belgisch fiscaal recht is precies het domein waar deze faalmodi het gevaarlijkst zijn. De Stanford-studie identificeerde vier categorieën fouten — jurisdictieverwarring, schendingen van de autoriteitshiërarchie, temporele mistoepassing en entiteitssubstitutie. Elke categorie sluit rechtstreeks aan bij Belgische fiscale praktijk.
Jurisdictieverwarring. Belgisch fiscaal recht opereert over federale, Vlaamse, Waalse en Brusselse lagen. Een AI-tool die federale WIB 92-bepalingen verwart met Vlaamse VCF-bepalingen — die beide vergelijkbare concepten bespreken met overlappende terminologie — produceert exact het type misgrounded output dat Stanford identificeerde.
Schendingen van de autoriteitshiërarchie. Een circulaire van FOD Financiën heeft niet dezelfde juridische kracht als een wetsartikel of een arrest van het Hof van Cassatie. Een AI-tool die administratieve richtsnoeren citeert alsof het wettelijke autoriteit betreft, maakt een fout die de meeste professionals bij snelle controle missen.
Temporele mistoepassing. Belgisch fiscaal recht verandert frequent — programmawetten wijzigen tientallen bepalingen twee keer per jaar. Een AI-tool die een correct juridisch principe ophaalt maar uit een achterhaalde versie van de wet, produceert advies dat vorig jaar juist was maar vandaag fout.
De OVB heeft deze risico’s erkend. Hun AI-richtlijnen stellen expliciet dat advocaten “de uiteindelijke verantwoordelijkheid behouden voor elk advies, elk processtuk en elk proceduredocument” en bij voorkeur moeten werken met tools die “duidelijke bronverwijzingen” bieden.
De verificatieparadox
Hier ligt de ongemakkelijke waarheid. Als elke door AI gegenereerde citatie handmatig moet worden geverifieerd tegen de primaire bron — wat de Stanford-studie suggereert dat nodig is — wat is dan precies de tijdsbesparing?
De tool genereert citaties sneller dan handmatig onderzoek. Maar verificatie kost evenveel tijd ongeacht wie de citatie vond. De netto efficiëntiewinst kan kleiner zijn dan leveranciers beweren — of zelfs negatief wanneer u de tijd meetelt die nodig is om langere AI-gegenereerde antwoorden te verwerken.
Dit betekent niet dat juridische AI-tools nutteloos zijn. Het betekent dat de waardepropositie anders is dan wat wordt verkocht. De waarde is niet “minder verifiëren.” Het is “breder zoeken, verifiëren wat de tool ophaalt, en verbanden vangen die u handmatig zou hebben gemist.”
Wat goed eruitziet: transparantie boven perfectie
De Stanford-studie bewijst niet dat juridische AI onmogelijk is. Ze bewijst dat nauwkeurigheidsclaims zonder gepubliceerde evaluatiemetrieken betekenisloos zijn.
Wat professionals in plaats daarvan moeten eisen:
Gepubliceerde nauwkeurigheidsmetrieken. Als een leverancier betrouwbaarheid claimt, moet die evaluatieresultaten publiceren — niet op geselecteerde queries, maar op systematische benchmarks.
Betrouwbaarheidsindicatoren. Een tool die zegt “ik ben 85% zeker van dit antwoord” is nuttiger dan een die elk antwoord met gelijke autoriteit presenteert. Onzekerheidskwantificatie vertelt de professional waar verificatie het meest nodig is.
Citaatvalidatie. Post-generatie verificatie die controleert of geciteerde bronnen daadwerkelijk de beweringen ondersteunen. Dit is de directe tegenmaatregel voor misgrounding — en de meeste tools doen het niet.
Veelgestelde vragen
Betekent de Stanford-studie dat juridische AI-tools nutteloos zijn?
Nee. Het betekent dat hun nauwkeurigheid lager is dan leveranciers beweerden, en dat professionele verificatie essentieel blijft. De tools zijn waardevol voor breed zoeken en initieel onderzoek — maar ze zijn geen vervanging voor professioneel oordeel.
Waarom had Westlaw een hoger hallucinatiepercentage dan Lexis?
De onderzoekers schreven dit deels toe aan antwoordlengte. Westlaw genereert langere, gedetailleerdere antwoorden — die meer falsifieerbare proposities bevatten en daardoor meer kansen op fouten.
Heeft de Belgische balie of het ITAA officieel standpunt ingenomen over AI-hallucinatierisico?
De OVB-richtlijnen behandelen expliciet AI-gebruik in de juridische praktijk en vereisen dat advocaten volledige verantwoordelijkheid behouden voor AI-ondersteunde output. De ITAA-deontologische code houdt fiscalisten eveneens verantwoordelijk voor de nauwkeurigheid van hun professioneel advies, ongeacht de gebruikte tools.
Gerelateerde artikelen
- AI-hallucinaties: waarom ChatGPT bronnen fabriceert (en hoe u ze herkent) → /nl/blog/ai-hallucinaties-fiscaal/
- Waarom transparantie belangrijker is dan nauwkeurigheid in juridische AI → /nl/blog/transparantie-vs-nauwkeurigheid/
- Wat is confidence scoring — en waarom het eerlijker is dan een zelfverzekerd antwoord → /nl/blog/confidence-scoring-uitgelegd/
Hoe Auryth TX dit toepast
Auryth TX pakt de drie faalmodi aan die de Stanford-studie identificeerde. Elk antwoord bevat bronvermeldingen gekoppeld aan de specifieke bepalingen, rulings of commentaar die het antwoord ondersteunen — niet alleen “dit document bestaat” maar “deze passage ondersteunt deze bewering.” Betrouwbaarheidsscores geven aan hoe goed de opgehaalde bronnen het gegenereerde antwoord ondersteunen, zodat professionals weten waar verificatie het meest nodig is.
Wij claimen niet hallucinatievrij te zijn. Wij claimen transparant te zijn over wat we weten, waarover we onzeker zijn, en waar het professionele oordeel van de gebruiker essentieel is. Dat onderscheid is belangrijker dan welk nauwkeurigheidspercentage dan ook.
Bronnen: 1. Magesh, V. et al. (2024). “Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools.” Journal of Empirical Legal Studies, 2025. 2. Dahl, M. et al. (2024). “Large Legal Fictions: Profiling Legal Hallucinations in Large Language Models.” Journal of Legal Analysis, 16(1), 64-93. 3. Farquhar, S. et al. (2024). “Detecting hallucinations in large language models using semantic entropy.” Nature, 630, 625-630.