Was ist Chunking — und warum es das unsichtbare Fundament der Qualität juristischer KI ist
Bevor Ihr juristisches KI-Tool eine Frage beantworten kann, muss es das Gesetz in Stücke schneiden. Die Art des Schneidens bestimmt, ob die Antwort die Ausnahme enthält, die alles ändert — oder ob sie sie völlig übersieht.
Von Auryth Team
Jedes Gespräch über die Qualität juristischer KI landet schließlich am selben Punkt: Retrieval. Findet das System die richtigen Quellen? Liefert es die relevanten Bestimmungen? Erfasst es die Ausnahme, die im dritten Absatz vergraben ist?
Aber bevor Retrieval überhaupt stattfinden kann, muss etwas Fundamentaleres geschehen. Das System muss entscheiden, wie es den Gesetzeskorpus in Stücke schneidet — Stücke, die klein genug sind zum Durchsuchen, aber groß genug, um bedeutungsvoll zu bleiben. Dieser Prozess heißt Chunking, und er ist der am meisten unterschätzte Faktor für die Qualität juristischer KI.
Wenn Sie es falsch machen, wird selbst das beste Retrieval-Modell der Welt unvollständige Antworten liefern. Wenn Sie es richtig machen, kann selbst ein bescheidenes System vertretbare Ergebnisse produzieren.
Warum KI überhaupt Chunks braucht
Moderne Sprachmodelle haben zunehmend große Kontextfenster — sowohl Claude als auch GPT-4.1 unterstützen mittlerweile bis zu eine Million Token. Man könnte denken, das eliminiert den Bedarf an Chunking völlig: Einfach der KI das komplette Gesetzbuch füttern und die Frage stellen.
Das funktioniert aus drei Gründen nicht.
Aufmerksamkeitsverdünnung. Forschung zeigt konsistent, dass LLMs mit Informationen kämpfen, die in der Mitte sehr langer Eingaben platziert sind — ein Phänomen, das als „lost in the middle”-Effekt bekannt ist. Das Modell richtet seine Aufmerksamkeit stark auf den Anfang und das Ende des Textes, schwächelt aber dazwischen. Für einen Gesetzeskorpus, bei dem die kritische Ausnahme in Absatz 47 eines 200-Absätze-Inputs sitzen könnte, ist das keine theoretische Sorge.
Retrieval-Präzision. Ein Retrieval-Augmented Generation (RAG) System füttert nicht den gesamten Korpus ins Modell. Es durchsucht den Korpus nach den relevantesten Stücken, ruft die Top-Ergebnisse ab und füttert nur diese ins Modell. Das erfordert, dass der Korpus in durchsuchbare Einheiten aufgeteilt wird — Chunks. Die Qualität dieser Chunks bestimmt die Qualität dessen, was das Modell sieht.
Kosten und Latenz. Die Verarbeitung einer Million Token kostet €2–15 pro Anfrage, je nach Modell. Für ein Steuerrecherchetool, das Dutzende Anfragen pro Tag bearbeitet, ist das Vollstopfen des Kontexts mit dem gesamten Korpus wirtschaftlich nicht tragbar.
Chunking ist kein Workaround für begrenzte Kontextfenster. Es ist eine architektonische Anforderung für Retrieval-basierte Systeme — und jedes seriöse juristische KI-System ist Retrieval-basiert.
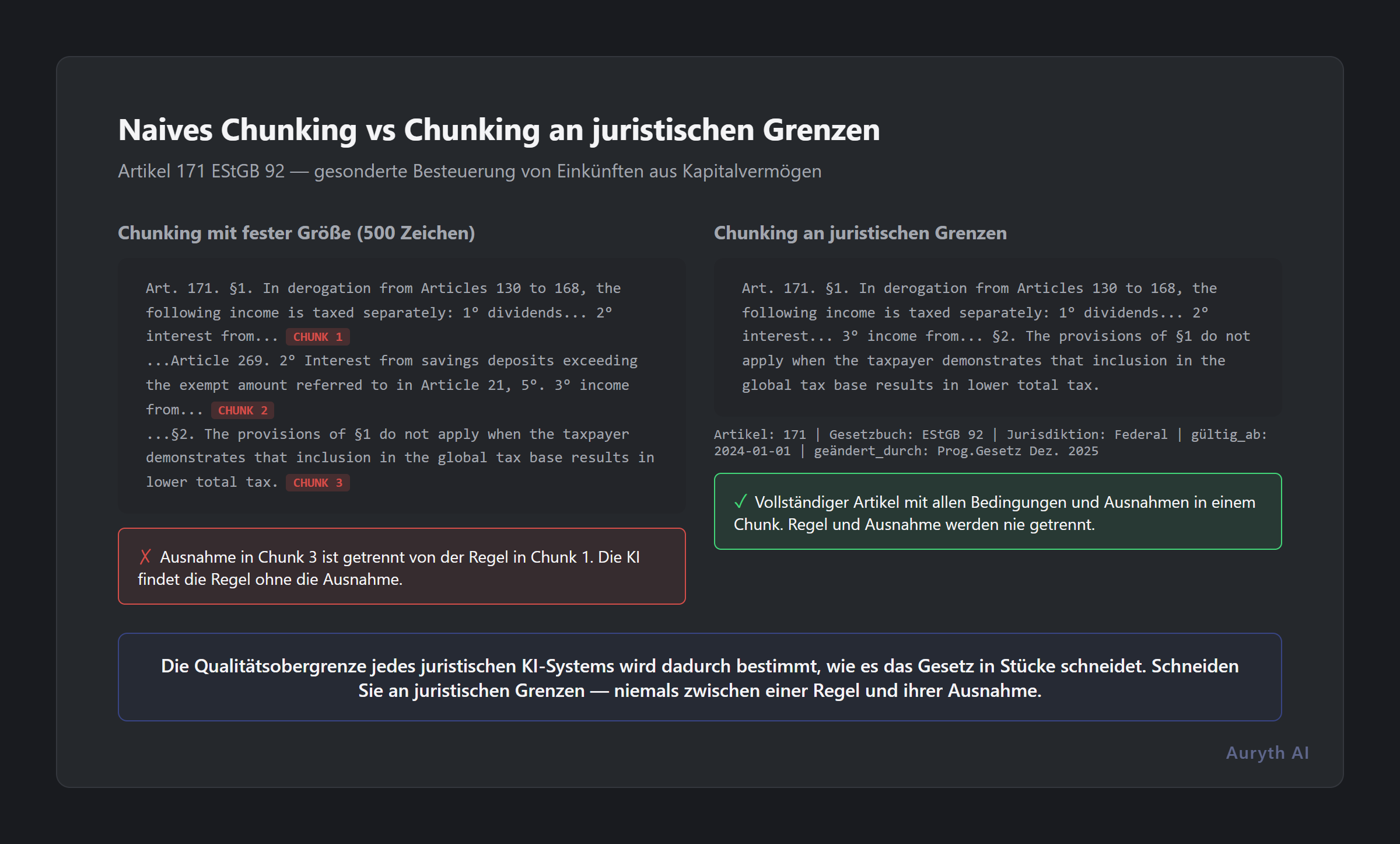
Naives Chunking: der falsche Weg zu schneiden
Der einfachste Ansatz ist Fixed-Size-Chunking: Den Text alle 500 Zeichen oder 200 Token aufteilen, unabhängig vom Inhalt.
So handhaben viele allgemeine KI-Tools Dokumente. Es funktioniert gut genug für Blogposts, Kunden-E-Mails und Produkthandbücher — Text, bei dem die Bedeutung eines Absatzes nicht kritisch vom nächsten abhängt.
Für juristischen Text ist es katastrophal.
Betrachten Sie Artikel 171 des belgischen Einkommensteuergesetzbuchs (WIB 92), der die getrennte Besteuerung beweglicher Einkünfte regelt. Eine vereinfachte Struktur:
Artikel 171. §1. Abweichend von den Artikeln 130 bis 168 werden folgende Einkünfte getrennt besteuert:
1° Dividenden [Bedingungen]…
2° Zinsen [Bedingungen]…
[mehrere nummerierte Kategorien mit spezifischen Sätzen]
§2. Die Bestimmungen des §1 gelten nicht, wenn der Steuerpflichtige nachweist, dass die Einbeziehung in die globale Steuerbemessungsgrundlage zu einer niedrigeren Gesamtsteuerbelastung führt.
Ein naiver Chunker, der bei 500 Zeichen teilt, könnte produzieren:
Chunk 1: “Artikel 171. §1. Abweichend von den Artikeln 130 bis 168 werden folgende Einkünfte getrennt besteuert: 1° Dividenden, die einer…” (schneidet mitten in der Bestimmung)
Chunk 2: ”…Quellensteuer zum Satz gemäß Artikel 269 unterliegen. 2° Zinsen aus…” (setzt aus dem Nichts fort)
Chunk 3: ”…§2. Die Bestimmungen des §1 gelten nicht, wenn der Steuerpflichtige nachweist, dass die Einbeziehung in die globale Steuerbemessungsgrundlage…” (die Ausnahme, jetzt von ihrem Kontext verwaist)
Eine KI, die nur Chunk 1 abruft, wird feststellen, dass Dividenden getrennt besteuert werden — Punkt. Sie wird übersehen, dass der Steuerpflichtige sich dafür entscheiden kann, sie in das globale Einkommen einzubeziehen, wenn das zu niedrigerer Steuer führt. Das ist keine Nuance. Für einen Mandanten mit niedrigem sonstigen Einkommen ändert diese Ausnahme das gesamte Beratungsergebnis.
Das „vorbehaltlich”-Problem
Belgischer Gesetzestext hat eine charakteristische Struktur, die naives Chunking besonders gefährlich macht. Bestimmungen folgen regelmäßig einem Muster:
Allgemeine Regel → vorbehaltlich (behoudens) → es sei denn (tenzij) → sofern (mits)
Jeder Qualifier schränkt die allgemeine Regel ein oder kehrt sie um. Die juristische Bedeutung jeder Bestimmung hängt von der vollständigen Kette ab — Regel plus all ihre Qualifikationen.
Wenn ein Fixed-Size-Chunker diese Kette teilt, erscheint die allgemeine Regel absolut. Die KI sieht „Dividenden werden getrennt mit 30% besteuert”, ohne „es sei denn, die globale Steuerbemessungsgrundlage würde zu niedrigerer Besteuerung führen” oder „sofern die Beteiligungsfreistellung nicht greift” zu sehen.
Das ist keine Halluzination im technischen Sinne. Die KI reproduziert genau, was ihr gegeben wurde. Der Fehler geschah vorgelagert, beim Chunking, wo die vollständige Bestimmung in Fragmente zerlegt wurde, die ihre juristische Bedeutung zerstörten.
Legal-Boundary-Chunking: an den Gelenken schneiden
Die Alternative ist, an juristischen Grenzen zu chunken — den strukturellen Unterteilungen, die der Gesetzgeber tatsächlich beabsichtigte.
Belgisches Steuerrecht folgt einer hierarchischen Struktur:
Gesetzbuch (WIB 92, BTW Code, VCF)
└─ Titel (Titel I: Einkommensteuern)
└─ Kapitel (Kapitel III: Körperschaftsteuer)
└─ Abschnitt (Abschnitt II: Steuerbemessungsgrundlage)
└─ Artikel (Artikel 215)
└─ Paragraph (§1, §2, §3)
└─ Absatz (lid 1, lid 2)
└─ Nummerierter Punkt (1°, 2°, 3°)Legal-Boundary-Chunking respektiert diese Hierarchie. Die Standardeinheit ist der Artikel — der fundamentale Baustein kodifizierten Rechts. Jeder Artikel adressiert ein distinktives juristisches Konzept und ist darauf ausgelegt, in sich abgeschlossen zu sein (obwohl er andere Artikel referenzieren kann).
Kurze Artikel wie Artikel 1 WIB 92 („Es wird eine Steuer auf das Gesamteinkommen erhoben…”) passen problemlos in einen einzelnen Chunk mit Platz übrig.
Mittellange Artikel wie Artikel 215 WIB 92 (Körperschaftsteuersätze, KMU-Ermäßigung, qualifizierende Bedingungen) füllen einen Chunk mit allen Bedingungen intakt.
Lange Artikel mit Dutzenden Paragraphen und nummerierten Punkten können praktische Chunk-Grenzen überschreiten. Für diese teilt das System an Paragraph-(§)-Grenzen und bewahrt vollständige semantische Einheiten. Wenn Paragraphen immer noch zu lang sind, teilt es an Absatzgrenzen — aber niemals mitten im Satz, niemals mitten in einer Klausel, niemals zwischen einer Regel und ihrer Ausnahme.
Das flämische Steuergesetzbuch (VCF) fügt eine zusätzliche Ebene struktureller Präzision mit seiner charakteristischen hierarchischen Nummerierung hinzu: Artikel 2.10.4.0.1 kodiert Titel 2, Kapitel 10, Abschnitt 4 direkt in der Artikelnummer. Diese eingebaute Strukturkarte macht Legal-Boundary-Chunking besonders sauber.
Was jeder Chunk mit sich trägt
Ein Textfragment ohne Metadaten ist ein Fragment ohne Kontext. In juristischer KI ist Kontext alles.
Jeder Chunk in einem ordnungsgemäß designten System trägt Identifikations-Metadaten:
- Artikelnummer und Gesetzesreferenz — „Artikel 215 WIB 92” oder „Artikel 2.7.1.0.3 VCF”
- Jurisdiktion — Föderal oder regional (Flandern, Wallonien, Brüssel)
- Gültigkeitsdaten — Wann diese Version der Bestimmung in Kraft trat und, falls zutreffend, wann sie ersetzt wurde
- Änderungshistorie — Welches Programmgesetz diese Bestimmung zuletzt änderte und was sich änderte
- Querverweise — Welche anderen Artikel diese Bestimmung zitiert und welche Artikel sie zitieren
- Autoritätsebene — Primärgesetzgebung, Königlicher Erlass, Rundschreiben oder Verwaltungsentscheidung
Diese Metadaten transformieren Retrieval von „finde Text, der der Frage ähnlich aussieht” zu „finde die aktuelle, autoritative Bestimmung aus der korrekten Jurisdiktion, die auf den spezifischen Zeitraum des Mandanten anwendbar ist.”
Ohne sie könnte das System eine 2019er-Version von Artikel 215 abrufen, die einen Körperschaftsteuersatz von 29,58% zeigt — technisch korrekter Text, aber falsch für jede Frage zum aktuellen Regime.
Wie Chunk-Qualität durch das System kaskadiert
Die Retrieval-Pipeline operiert als Kette:
Chunking → Embedding → Retrieval → Reranking → Antwortgenerierung
Jede Stufe hängt vom Output der vorherigen ab. Schlechtes Chunking propagiert Fehler durch jede nachfolgende Stufe.
Embedding konvertiert jeden Chunk in einen mathematischen Vektor. Wenn der Chunk ein Satzfragment ist, das mitten in einer Klausel endet, erfasst das Embedding einen unvollständigen Gedanken — und wird gegen die falschen Anfragen matchen.
Retrieval sucht nach Chunks, deren Embeddings der Frage am ähnlichsten sind. Wenn die kritische Ausnahme getrennt von der Regel gechunkt wurde, könnte das Retrieval die Regel ohne die Ausnahme zurückgeben — oder die Ausnahme ohne die Regel.
Reranking evaluiert die Top-Ergebnisse erneut mit einem sophistizierteren Modell. Es kann einige Chunking-Fehler erfassen, indem es erkennt, dass ein Ergebnis unvollständig ist. Aber es kann Informationen nicht rekonstruieren, die über Chunks verteilt wurden, die es nie sieht.
Antwortgenerierung synthetisiert die abgerufenen Chunks zu einer Antwort. Wenn sie fünf gut gechunkte, vollständige Bestimmungen mit Metadaten erhält, kann sie eine vertretbare Antwort mit ordnungsgemäßen Zitaten produzieren. Wenn sie fünf Textfragmente ohne Artikelnummern und ohne Gültigkeitsdaten erhält, wird selbst das fähigste Modell eine Antwort produzieren, die selbstsicher aussieht, aber nicht verifiziert werden kann.
Das ist die fundamentale Einsicht: Die Qualitätsobergrenze jedes RAG-basierten juristischen KI-Systems wird durch seine Chunking-Strategie gesetzt. Keine noch so große Modell-Sophistikation nachgelagert kann strukturelle Zerstörung vorgelagert kompensieren.
Was das für Praktiker bedeutet
Wenn Sie ein juristisches KI-Tool evaluieren, ist die Chunking-Strategie kein technisches Detail, das man überspringen kann. Sie ist die architektonische Entscheidung, die bestimmt, ob das Tool verlässlich vollständige Rechtsbestimmungen mit ihren Ausnahmen, Bedingungen und zeitlichem Kontext zurückgeben kann.
Drei Fragen, die es wert sind, gestellt zu werden:
-
Bewahrt das Tool vollständige Artikel mit allen Bedingungen und Ausnahmen? Wenn die Antwort beinhaltet, wie das Tool Bestimmungen „zusammenfasst” oder „Kernpunkte extrahiert”, könnte das Chunking die juristische Struktur zerstören statt sie zu bewahren.
-
Trägt jedes Ergebnis Metadaten — Artikelnummer, Jurisdiktion, Gültigkeitsdatum? Wenn Ergebnisse Text ohne klare Herkunft zeigen, chunkt das System wahrscheinlich ohne Metadaten. Das macht Verifikation und Zitation unmöglich.
-
Kann das Tool zwischen aktuellen und historischen Bestimmungen unterscheiden? Wenn das System veraltete Versionen zurückgibt, ohne sie zu kennzeichnen, fehlen die zeitlichen Metadaten — ein Chunking- und Indexierungsfehler.
Die Ironie des Chunking ist, dass es unsichtbar ist, wenn es gut funktioniert. Der Nutzer sieht einfach korrekte, vollständige, gut zitierte Antworten. Die Architektur, die diese Antworten möglich machte — das sorgfältige Schneiden, die Metadaten-Bewahrung, die Grenzenerkennung — operiert vollständig hinter den Kulissen.
Wenn es schlecht funktioniert, sind die Fehler auch unsichtbar — bis ein Mandant sich auf Beratung verlässt, die die Ausnahme im dritten Absatz übersehen hat.
Verwandte Artikel
- Was ist RAG — und warum es die einzige Architektur ist, die juristische KI vertretbar macht →
- Was ist Authority Ranking — und warum Ihr juristisches KI-Tool es wahrscheinlich ignoriert →
- Was ist Confidence Scoring — und warum es ehrlicher ist als eine selbstsichere Antwort →
Wie Auryth TX das anwendet
Auryth TX chunkt an juristischen Grenzen — Artikel, Paragraphen und Absätze — niemals an willkürlichen Zeichen- oder Token-Limits. Das WIB 92, der BTW Code, das VCF und die regionalen Gesetzbücher werden jeweils nach ihren spezifischen strukturellen Konventionen geparst. Die hierarchische Nummerierung des VCF, die Paragraph-und-Absatz-Struktur des WIB, die Artikel-und-Königlicher-Erlass-Organisation des BTW Code — jede erfordert einen anderen Parsing-Ansatz, und jede bekommt einen.
Jeder Chunk trägt seine vollständige Herkunft: Artikelnummer, Gesetzesreferenz, Jurisdiktion, Gültigkeitszeitspanne, Änderungskette und Querverweise zu verwandten Bestimmungen. Wenn das System Artikel 215 WIB 92 abruft, ruft es die aktuelle Version ab — mit Metadaten, die kennzeichnen, wann es zuletzt durch das Programmgesetz vom Juli 2025 geändert wurde und was sich änderte.
Das Ergebnis: Wenn das System sagt „Dividenden werden getrennt unter Artikel 171 WIB 92 besteuert”, steht die vollständige Bestimmung hinter dieser Antwort — einschließlich der Ausnahme in §2 für Steuerpflichtige, die von globaler Einbeziehung profitieren. Die Ausnahme ist nicht in einem anderen Chunk. Sie ist genau dort, weil das System niemals die Regel von ihren Qualifikationen trennte.
Chunking an juristischen Grenzen. Jede Bestimmung vollständig. Jede Ausnahme bewahrt.
Quellen: 1. Liu, N.F. et al. (2024). “Lost in the Middle: How Language Models Use Long Contexts.” Transactions of the ACL, 12, 157-173. 2. ResearchGate (2024). “Legal Chunking: Evaluating Methods for Effective Legal Text Retrieval.” 3. Milvus (2025). “Best practices for chunking lengthy legal documents for vectorization.” 4. Weaviate (2024). “Chunking Strategies for RAG.” 5. Elvex (2026). “Context Length Comparison: Leading AI Models in 2026.”