Was ist Reranking — und warum es den Unterschied macht zwischen Dokumente finden und Antworten finden
Erste-Phase-Retrieval findet 100 Treffer. Reranking identifiziert die 5, die Ihre Frage tatsächlich beantworten. Warum diese Unterscheidung für juristische KI entscheidend ist.
Von Auryth Team
Ihr KI-Tool hat 100 Dokumente gefunden, die zu Ihrer Abfrage passen. Es hat Ihnen 5 gezeigt. Wie hat es entschieden, welche 5?
Diese Frage ist wichtiger, als die meisten Fachleute ahnen. Der Unterschied zwischen dem Dokument, das die richtigen Suchbegriffe enthält, und dem Dokument, das Ihre Frage tatsächlich beantwortet, ist der Unterschied zwischen Retrieval und Reranking — und hier sparen die meisten juristischen KI-Tools.
Benchmarks aus der Elastic-Studie zeigen die Lücke deutlich: Auf der BEIR-Benchmark-Suite verbessert Reranking von BM25-Ergebnissen die Relevanz um durchschnittlich 39 %. Bei Natural Questions erreicht die Verbesserung 90 %. Die Technologie zwischen „ich habe passende Dokumente gefunden” und „hier sind die relevanten” ist kein Luxus — sie ist die Qualitätsschicht, die KI-Output vertrauenswürdig macht.
Das Richtige-Wörter-falsche-Antwort-Problem
Stellen Sie sich vor: Ein belgischer Steuerberater sucht nach den aktuellen Regeln zur Erbschaftsteuer in der Flämischen Region. Erste-Phase-Retrieval wirft ein breites Netz. Es liefert jedes Dokument über flämische Erbschaftsteuer: die aktuellen VCF-Bestimmungen, einen Reformvorschlag von 2018, ein überholtes Rundschreiben von 2015, akademischen Kommentar von 2020.
Alle diese Dokumente enthalten die richtigen Wörter. Nur manche enthalten die richtige Antwort.
Das ist das Richtige-Wörter-falsche-Antwort-Problem. Ein Dokument über die Reform der flämischen Erbschaftsteuersätze von 2018 und ein Dokument über die aktuellen Sätze von 2024 matchen dieselbe Abfrage. Aber nur eines beantwortet die Frage „was sind die aktuellen Sätze?”
Wie Reranking funktioniert: Abfrage und Dokument gemeinsam lesen
Die Kerneinsicht hinter Reranking ist architektonisch. Erste-Phase-Retriever encodieren Abfragen und Dokumente unabhängig voneinander. Ein Cross-Encoder-Reranker macht das Gegenteil: Er nimmt die Abfrage und ein Kandidatendokument, verkettet sie und schickt beide durch ein Transformer-Modell, das gleichzeitig auf jedes Token in beiden Texten achten kann.
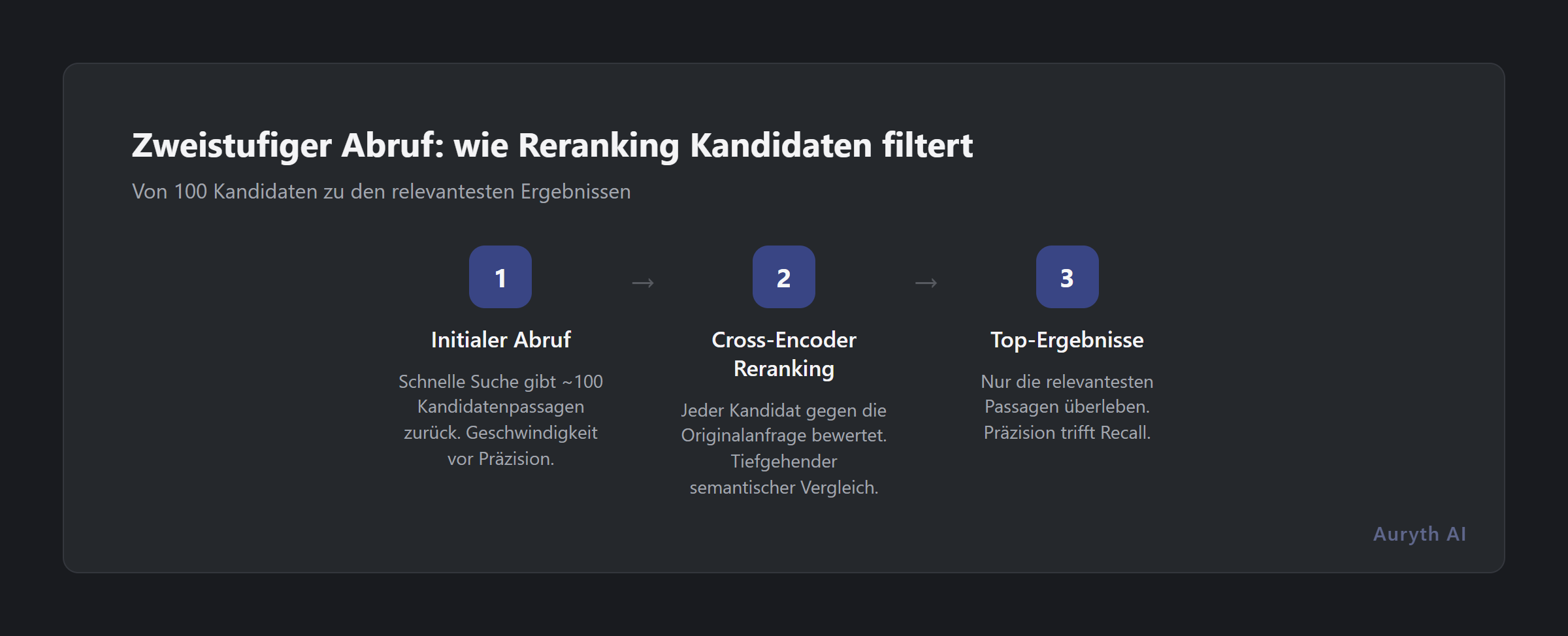
Der Kompromiss ist Geschwindigkeit gegen Präzision. Bi-Encoder verarbeiten Millionen von Dokumenten in Millisekunden. Cross-Encoder benötigen einen vollständigen Durchlauf für jedes Abfrage-Dokument-Paar — unpraktisch für ganze Korpora, aber ideal für die Neubewertung einer Shortlist von 50–100 Kandidaten.
Eine Suchmaschine, die Dokumente mit den richtigen Wörtern findet, ist eine Datenbank. Eine Suchmaschine, die Dokumente findet, die die richtige Frage beantworten, ist ein Recherche-Tool.
Was die Benchmarks zeigen
| Phase | nDCG@10 (BEIR-Durchschnitt) | Was es bedeutet |
|---|---|---|
| Nur BM25 | 0,426 | Keyword-Treffer — relevante Begriffe, unpräzises Ranking |
| Nur Bi-Encoder | ~0,45 | Semantische Treffer — bessere Konzepte, noch unpräzise |
| BM25 + Reranker | 0,565 | +39 % — Dokumente, die die Frage beantworten, steigen nach oben |
Das Muster ist klar: je komplexer die Abfrage, desto mehr hilft Reranking. Einfache Faktenabfragen profitieren mäßig. Domainübergreifende Fragen profitieren dramatisch.
Warum juristische Suche mehr verlangt als generisches Reranking
Generische Reranker behandeln alle Dokumente gleich. Ein Blogpost und ein Urteil des Kassationshofs bekommen dieselbe Behandlung. Für juristische Recherche ist das eine kritische Lücke.
Autoritätshierarchie. Ein Urteil des Hof van Cassatie sollte eine Entscheidung eines untergeordneten Gerichts zum selben Rechtspunkt überragen. Eine gesetzliche Bestimmung sollte Kommentar dazu überragen.
Zeitliche Gültigkeit. Ein Urteil von 2024 über flämische Erbschaftsteuersätze ersetzt eines von 2019 zur selben Frage. Generische Reranker sehen beide als gleich relevante Treffer.
Jurisdiktionelle Relevanz. Für eine Frage über flämische Erbschaftsteuer sind flämische VCF-Bestimmungen bindende Autorität. Föderale und wallonische Bestimmungen sind Kontext.
Die ehrliche Einschränkung: begrenzter Recall
Reranking kann nur Dokumente umordnen, die die erste Phase bereits abgerufen hat. Wenn ein relevantes Dokument nicht in der initialen Kandidatenmenge war, wird kein Reranking es ans Licht bringen. Deshalb ist hybride Suche als erste Phase so wichtig.
Häufige Fragen
Was ist der Unterschied zwischen einem Bi-Encoder und einem Cross-Encoder?
Ein Bi-Encoder encodiert Abfrage und Dokument separat in Vektoren fester Größe. Schnell aber unpräzise. Ein Cross-Encoder liest Abfrage und Dokument gemeinsam durch einen geteilten Transformer. Langsamer aber weitaus präziser — er versteht die Beziehung zwischen der spezifischen Abfrage und dem spezifischen Dokument.
Fügt Reranking spürbare Verzögerung hinzu?
Für eine Shortlist von 50–100 Kandidaten fügt Cross-Encoder-Reranking etwa 100–150 Millisekunden hinzu. Die Gesamtantwortzeit bleibt deutlich unter einer Sekunde.
Kann Reranking Halluzinationen in juristischer KI eliminieren?
Nicht direkt, aber es reduziert sie erheblich. Halluzinationen entstehen oft, wenn das Sprachmodell marginal relevante Dokumente erhält. Wenn Reranking sicherstellt, dass die relevantesten, autoritativsten Dokumente die Generierungsschicht erreichen, hat das Modell weniger Grund zu fabrizieren.
Verwandte Artikel
- Wie hybride Suchtechnologie funktioniert → /de/blog/hybride-suchtechnologie/
- Was ist Authority Ranking → /de/blog/autoritaets-ranking-rechts-ki/
- Was ist RAG → /de/blog/was-ist-rag/
Wie Auryth TX das umsetzt
Auryth TX verwendet eine Zwei-Phasen-Retrieval-Pipeline mit domainspezifischem Reranking. Die erste Phase kombiniert BM25-Keyword-Matching mit dichtem Vektor-Retrieval, um den Recall zu maximieren. Die Reranking-Phase bewertet jeden Kandidaten gegen die tatsächliche Abfrage, wobei Autoritätshierarchie einbezogen wird — gesetzliche Bestimmungen rangieren über Kommentar, höhere Gerichte über niedrigere — und zeitliche Gültigkeit, sodass überholte Quellen automatisch deprioritisiert werden.
Die Ergebnisse, die ein Fachmann sieht, sind nicht nur relevant durch Keyword-Match. Sie sind relevant nach Bedeutung, gerankt nach Autorität und aktuell nach geltendem Recht.
Quellen: 1. Nogueira, R. & Cho, K. (2019). „Passage Re-ranking with BERT.” arXiv preprint. 2. Thakur, N. et al. (2021). „BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models.” NeurIPS 2021. 3. Khattab, O. & Zaharia, M. (2020). „ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT.” SIGIR ‘20. 4. Pipitone, N. & Houir Alami, G. (2024). „LegalBench-RAG: A Benchmark for Retrieval-Augmented Generation in the Legal Domain.” arXiv preprint.