Was ist Confidence Scoring — und warum es ehrlicher ist als eine selbstsichere Antwort
LLMs überschätzen ihre eigene Korrektheit um 20-60%. Confidence Scoring löst dieses Problem nicht — es macht es sichtbar. Für Steuerberater ist diese Sichtbarkeit der Unterschied zwischen einem Recherchetool und einer Ratemaschine.
Von Auryth Team
Stellen Sie ChatGPT eine belgische Steuerfrage und Sie erhalten eine klare, gut strukturierte, autoritär klingende Antwort. Stellen Sie eine Frage, auf die das System unmöglich die Antwort kennen kann, und Sie erhalten exakt denselben Tonfall. Dieselbe Struktur. Dieselbe Zuversicht. Keinerlei Signal, dass die zweite Antwort erfunden wurde.
Das ist kein Bug. So funktionieren Sprachmodelle. Sie sind darauf trainiert, flüssigen, selbstsicheren Text zu produzieren — nicht darauf, Ihnen zu sagen, wann sie raten. Forschung über fünf große LLMs zeigt, dass sie die Wahrscheinlichkeit, dass ihre Antworten korrekt sind, um 20 bis 60 Prozent überschätzen. Je schwieriger die Frage, desto schlechter wird die Kalibrierung.
Für einen Steuerberater ist diese gleichförmige Zuversicht die gefährlichste Eigenschaft von KI-Tools. Sie bedeutet, dass das System eine gut fundierte Antwort — gestützt durch drei Urteile des Kassationshofs und eine klare gesetzliche Bestimmung — identisch behandelt wie eine Antwort, die es aus Mustern in seinen Trainingsdaten erfunden hat. Sie erhalten kein Signal. Sie können den Unterschied nicht erkennen, ohne jede Antwort selbst zu überprüfen.
Confidence Scoring ist die architektonische Antwort auf dieses Problem. Keine Lösung — ein Signal.
Was Confidence Scoring tatsächlich misst
Ein Confidence Score ist ein numerischer Indikator, der Ihnen sagt, wie gut eine Antwort fundiert ist — nicht durch die interne Gewissheit des Modells (die unzuverlässig ist), sondern durch die Beweise, die das System gefunden hat.
In einem gut gestalteten System hat Confidence zwei Dimensionen:
Quellenabdeckung — wie viele relevante Quellen hat das System gefunden? Hat es gesetzliche Bestimmungen, Rechtsprechung und Verwaltungserlasse abgerufen? Oder hat es ein einziges tangential verwandtes Dokument gefunden?
Argumentationssicherheit — wie klar unterstützen die abgerufenen Quellen die Schlussfolgerung? Stimmen sie überein? Widersprechen sie sich? Behandeln sie die exakte Frage oder nur eine verwandte?
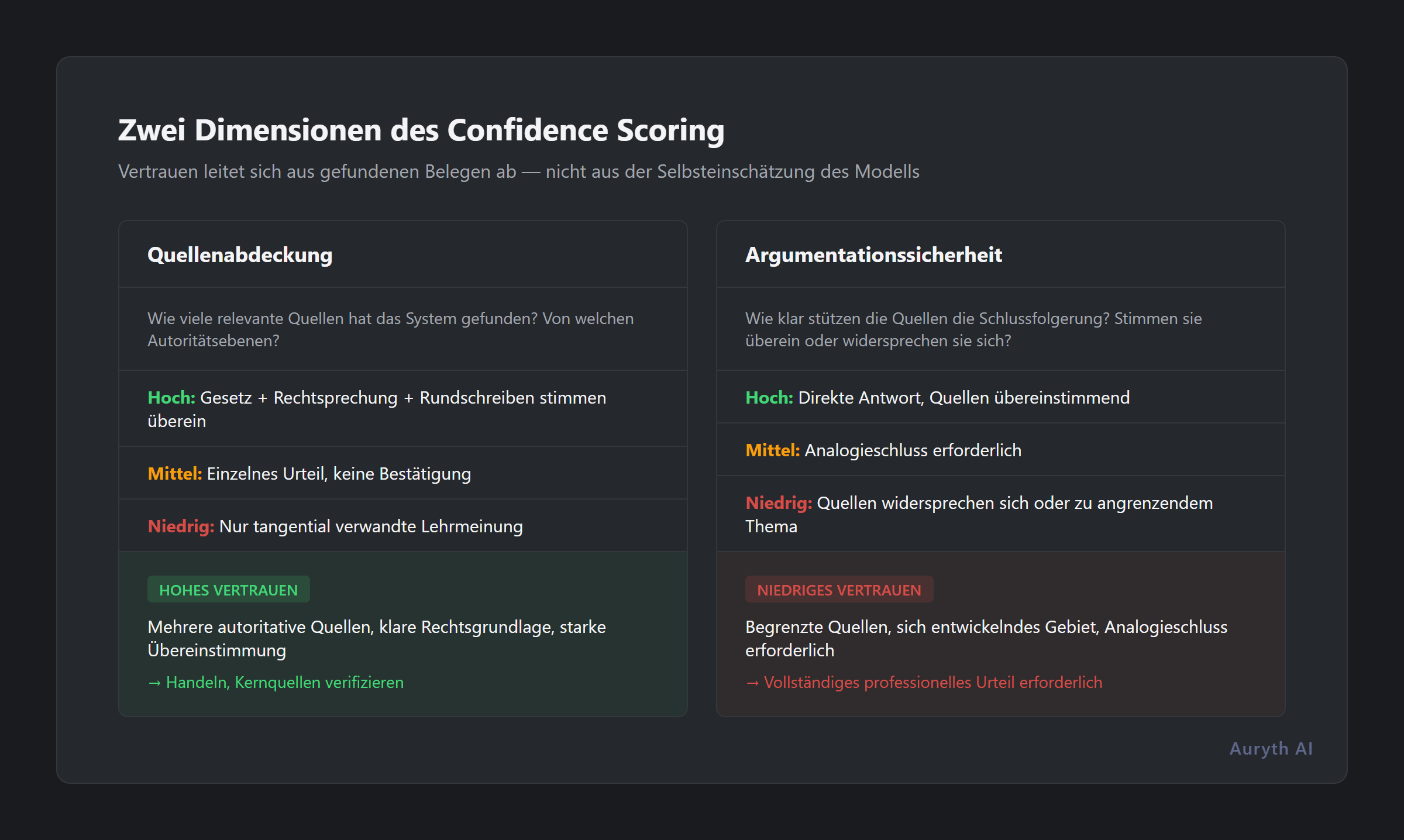
Eine Antwort mit hoher Confidence sieht so aus: „Basierend auf Art. 21 EStGB 92, bestätigt durch ein Urteil des Kassationshofs vom 12. März 2024 und konsistent mit Fisconetplus-Rundschreiben 2025/C/71, beträgt der Quellensteuer-Satz für Dividenden 30%.” Mehrere autoritative Quellen. Klare Rechtsgrundlage. Starke Übereinstimmung.
Eine Antwort mit niedriger Confidence sieht so aus: „Basierend auf einer Vorabentscheidung der Steueraufsichtsbehörde von 2022 könnte diese Struktur für die Beteiligungsfreistellung qualifizieren, obwohl keine Rechtsprechung gefunden wurde, die diese spezifische Konfiguration behandelt.” Einzelne Quelle. Keine Bestätigung. Analogische Argumentation.
Beide Antworten könnten korrekt sein. Aber sie erfordern sehr unterschiedliche Level professioneller Prüfung. Ohne ein Confidence-Signal sehen sie identisch aus.
Warum LLMs systematisch überkonfident sind
Das Überkonfidenz-Problem ist keine Einschränkung, die in der nächsten Modellversion behoben wird. Es ist strukturell.
Sprachmodelle werden durch Reinforcement Learning from Human Feedback (RLHF) trainiert, bei dem menschliche Bewerter die Qualität von Antworten bewerten. Selbstsichere, gut strukturierte Antworten erhalten konstant höhere Bewertungen als vorsichtige, unsichere — selbst wenn beide gleich genau sind. Der Trainingsprozess bringt Modellen buchstäblich bei, dass Zuversicht belohnt wird.
Forschung zeigt, dass Belohnungsmodelle, die in RLHF verwendet werden, inhärente Vorurteile zugunsten hoher Confidence-Scores aufweisen, unabhängig von der tatsächlichen Antwortqualität. Das Modell lernt: Sicher zu klingen bringt bessere Bewertungen. Also klingt es sicher — ob es das sollte oder nicht.
Die Kalibrierungszahlen bestätigen dies. Expected Calibration Errors über getestete LLMs liegen zwischen 0,108 und 0,427 — was bedeutet, dass die Lücke zwischen angegebener Confidence und tatsächlicher Genauigkeit erheblich ist. Größere Modelle kalibrieren etwas besser, aber selbst die besten Modelle bleiben signifikant überkonfident bei Aufgaben, die Fachwissen erfordern.
Wenn ein KI-System sagt „Ich bin sicher”, sagt diese Aussage nichts über Genauigkeit aus. Sie sagt etwas über Trainingsanreize aus.
Was gleichförmige Confidence in der Praxis kostet
Betrachten Sie einen belgischen Steuerberater, der zwei Fragen stellt:
Frage A: „Was ist der Standardsatz der Körperschaftsteuer für KMU in Belgien?”
Frage B: „Kann ein belgischer Einwohner, der Kryptowährung an eine ausländische Börse überträgt und anschließend in Stablecoins umwandelt, die Ausnahme für ‚normale Verwaltung des Privatvermögens’ gemäß Art. 90 EStGB 92 geltend machen?”
Ein allgemeines LLM beantwortet beide mit demselben autoritären Tonfall. Dieselbe Formatierung. Dieselbe Gewissheit. Aber Frage A hat eine direkte, gut dokumentierte Antwort (20% auf die ersten €100.000 für qualifizierende KMU gemäß Art. 215 EStGB 92). Frage B liegt an der Schnittstelle sich schnell entwickelnder Steuerpolitik, begrenzter Rechtsprechung und Verwaltungspositionen, die je nach Veranlagungszeitraum variieren.
Ohne Confidence Scoring muss der Berater bei beiden Antworten das gleiche Maß an Überprüfung durchführen. Mit Confidence Scoring markiert das System Frage A als high-confidence (mehrere klare Autoritäten) und Frage B als low-confidence (begrenzte Autoritäten, sich entwickelnder Politikbereich, analogische Argumentation erforderlich). Der Berater kann Prüfungsaufwand dort einsetzen, wo es zählt.
Diese Zuteilung ist keine Faulheit — sie ist die Definition effizienter professioneller Praxis.
Der Unterschied zwischen Modell-Confidence und Evidenz-Confidence
Hier ist eine Unterscheidung, die die meisten KI-Erklärer übersehen: Es gibt zwei völlig unterschiedliche Arten von „Confidence” in KI-Systemen, und nur eine davon ist nützlich.
Modell-Confidence ist die Wahrscheinlichkeit, die das Sprachmodell seinen eigenen Output-Tokens zuweist. Das ist, was intern in jedem LLM verfügbar ist. Forschung zeigt, dass es schlecht kalibriert und systematisch überkonfident ist. Es sagt Ihnen, wie „erwartbar” die Wortwahl des Modells ist — nicht, ob die Antwort korrekt ist.
Evidenz-Confidence wird aus der Retrieval-Pipeline abgeleitet — wie viele Quellen gefunden wurden, wie autoritativ sie sind, wie direkt sie die Frage behandeln und ob sie übereinstimmen. Das ist extern zum Modell. Es basiert auf verifizierbaren Fakten darüber, was das System gefunden hat, nicht auf der Selbsteinschätzung des Modells.
Ein nützliches Confidence-Scoring-System verwendet Evidenz-Confidence, nicht Modell-Confidence. Der Score sollte Ihnen sagen: „Wir haben drei gesetzliche Bestimmungen, zwei Urteile und ein Rundschreiben gefunden, die Ihre Frage direkt behandeln, und sie stimmen überein” — nicht „das Modell ist sich zu 87% sicher über seine Wortwahl.”
Was Confidence Scoring nicht kann
Intellektuelle Ehrlichkeit erfordert das Anerkennen der Grenzen:
Es kann unbekannte Unbekannte nicht erkennen. Wenn die relevante Bestimmung nicht im Korpus ist, kann das System eine plausible Antwort aus angrenzenden Quellen liefern — mit moderater Confidence. Der Confidence Score spiegelt wider, was gefunden wurde, nicht was existiert.
Manche Unsicherheit widersteht der Quantifizierung. Ein kürzlich erschienenes Paper im Journal der Royal Statistical Society macht diesen Punkt direkt: „Viele folgenreiche Formen von Unsicherheit in professionellen Kontexten widerstehen der Quantifizierung.” Ob eine Steuerstruktur als „normale Verwaltung des Privatvermögens” qualifiziert, ist kein Confidence-Score-Problem — es ist ein Problem professionellen Urteils. Das System kann Ihnen die Quellen zeigen. Die Interpretation ist Ihre.
Confidence Scores können falsche Präzision erzeugen. Ein Score von 0,73 vs. 0,71 ist bedeutungsloses Rauschen. Was zählt, ist das kategorische Signal: hohe Confidence (starke Evidenz, handeln Sie danach), moderate Confidence (einige Evidenz, verifizieren Sie die Hauptquellen), niedrige Confidence (dünne Evidenz, das erfordert Ihr volles professionelles Urteil).
Das richtige Design vermeidet falsche Präzision, indem es in Bändern kommuniziert, nicht in Dezimalstellen.
Verwandte Artikel
- Warum Transparenz wichtiger ist als Genauigkeit in juristischer KI
- KI-Halluzinationen: warum ChatGPT Quellen erfindet (und wie man es erkennt)
- Wie man ein juristisches KI-Tool bewertet: 10 Fragen, die wirklich zählen
Wie Auryth TX das anwendet
Jede Antwort in Auryth TX trägt einen Confidence Score — nicht abgeleitet von Modell-Selbsteinschätzung, sondern von der Retrieval-Pipeline.
Der Score reflektiert drei Evidenz-Dimensionen: Quellenanzahl und Autorität (wie viele relevante Quellen und welches Rechtsgewicht haben sie), Direktheit (behandeln die Quellen Ihre exakte Frage oder nur eine verwandte), und Konsens (stimmen die Quellen überein oder gibt es einen Konflikt, der professionelle Interpretation erfordert).
Wenn Confidence hoch ist, sehen Sie die Antwort mit ihren unterstützenden Quellen und können effizient vorgehen. Wenn Confidence niedrig ist, sagt Ihnen das System das explizit — und zeigt Ihnen, was es gefunden hat, was es gesucht und nicht gefunden hat (negatives Retrieval), und wo die Lücken in der Autorität liegen.
Wir tun nicht so, als wäre jede Antwort gleich zuverlässig. Wir geben Ihnen das Signal, das Sie brauchen, um Ihr professionelles Urteil dort einzusetzen, wo es am meisten zählt.
Quellen: 1. Cash, T.N. et al. (2025). „Quantifying uncert-AI-nty: Testing the accuracy of LLMs’ confidence judgments.” Memory & Cognition. 2. Leng, J. et al. (2025). „Taming Overconfidence in LLMs: Reward Calibration in RLHF.” ICLR 2025. 3. Steyvers, M. et al. (2025). „What Large Language Models Know and What People Think They Know.” Nature Machine Intelligence. 4. Delacroix, S. et al. (2025). „Beyond Quantification: Navigating Uncertainty in Professional AI Systems.” RSS: Data Science and Artificial Intelligence.