Hinter den Kulissen: wie eine Gesetzesänderung durch ein juristisches KI-System fließt
Wenn Belgiens Programmgesetz über Nacht 47 Bestimmungen ändert, was passiert dann im KI-Tool, auf das Sie sich verlassen? Ein transparenter Blick auf die Ingestion-Pipeline.
Von Auryth Team
Das Programmgesetz wurde an einem Donnerstag verabschiedet. Es änderte 47 Bestimmungen über sechs Gesetzbücher hinweg — Einkommensteuer, Mehrwertsteuer, Sozialversicherung, Gesellschaftsrecht, regionale Anreize und Erbschaftsteuer. Am Freitagmorgen war das alte Gesetz Geschichte. Am Montag mussten Fachleute Mandanten zu den neuen Regeln beraten.
Wie schnell weiß Ihr KI-Tool Bescheid?
Die meisten juristischen KI-Anbieter versprechen „immer aktuelle Inhalte.” Keiner von ihnen erklärt, was das in der Praxis bedeutet. Sie verraten nicht, wie lang die Lücke zwischen Veröffentlichung und Durchsuchbarkeit eines Gesetzes dauert. Sie erklären nicht, was während dieser Lücke passiert. Sie zeigen nicht, wer verifiziert, dass der aufgenommene Text tatsächlich dem Veröffentlichten entspricht.
Dieses Schweigen sollte jeden beunruhigen, der sich für professionelle Beratung auf diese Tools verlässt.
Was „immer aktuell” tatsächlich erfordert
Das Belgische Staatsblatt veröffentlicht täglich neue Gesetzgebung sowohl auf Niederländisch als auch auf Französisch. Allein 2024 veröffentlichte es einen Rekord von 141.310 Seiten — rund 390 Seiten pro Tag. Programmgesetze (programmawetten) erscheinen zweimal jährlich, wobei jedes Dutzende von Bestimmungen über nicht verwandte Bereiche in einem einzigen Gesetzgebungsakt ändert.
Dieses Volumen macht manuelle Überwachung unmöglich. Aber es macht auch automatisierte Überwachung genuinely schwierig. Juristischer Text ist kein Webcontent. Er hat verschachtelte Hierarchien — Abschnitte, Unterabschnitte, Artikel, Absätze, Punkte — die Standardtextverarbeitung ignoriert. Änderungen verwenden spezialisierte Sprache: „Artikel 145/1 des WIB 92 wird durch Folgendes ersetzt…” Das System muss nicht nur den neuen Text verstehen, sondern auch welche bestehende Bestimmung er ersetzt, wann die Änderung in Kraft tritt, und welche Querverweise betroffen sind.
Standard-RAG-Systeme erreichen nur 58 % Genauigkeit bei versionssensitiven Fragen, weil sie semantisch ähnlichen Inhalt abrufen, ohne die zeitliche Gültigkeit zu prüfen. Versionsbewusste Systeme können 90 % erreichen — aber das erfordert eine dedizierte Architektur, nicht einfach „die Datenbank aktualisieren” (Huwiler et al., 2025).
Die Sieben-Stufen-Pipeline
Folgendes muss zwischen der Veröffentlichung eines Gesetzes und dem Zeitpunkt geschehen, an dem ein Fachmann danach suchen kann:
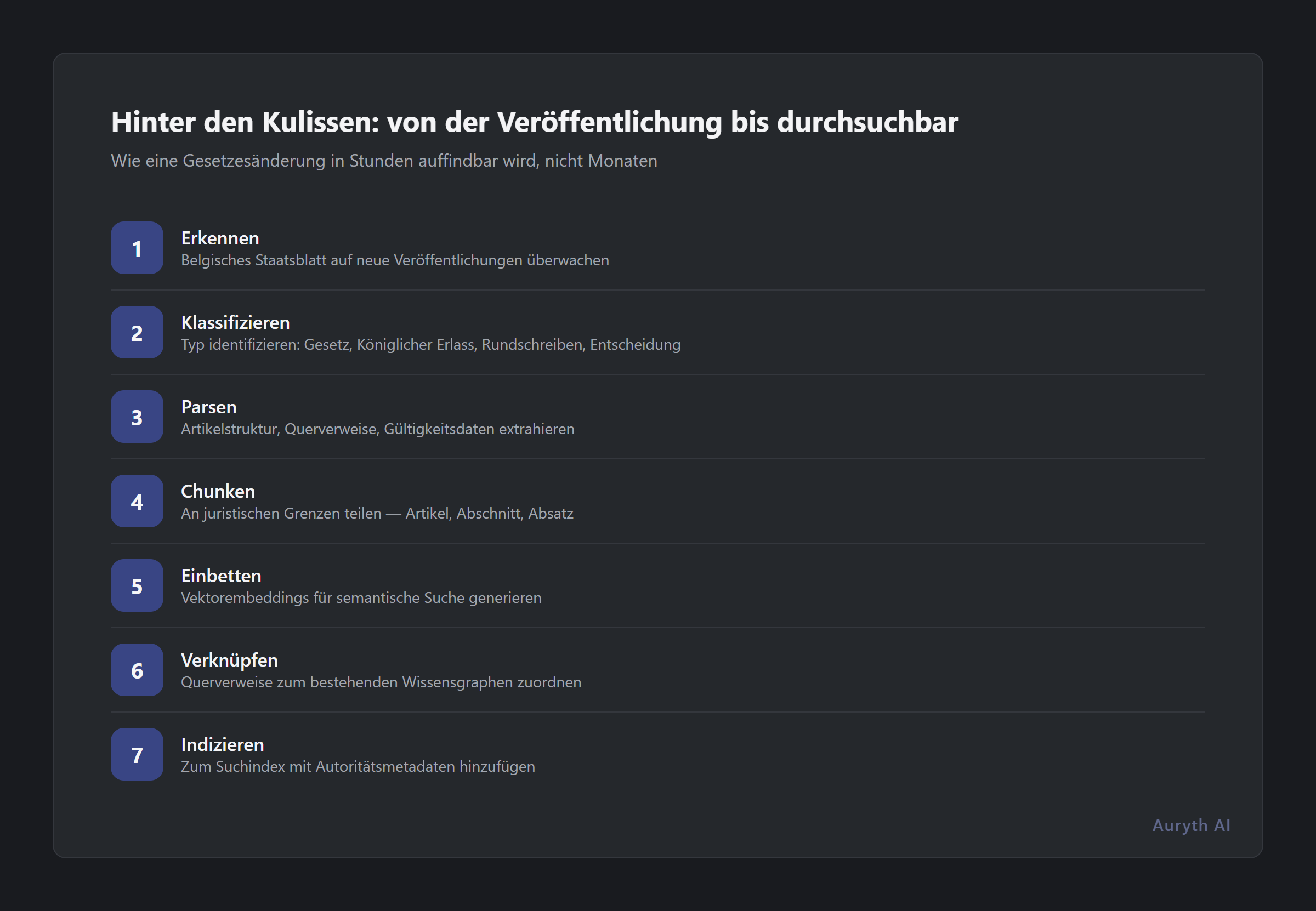
Stufe 1: Erkennung. Ein Überwachungsagent beobachtet das Belgische Staatsblatt auf neue Veröffentlichungen. Dies läuft kontinuierlich — nicht wöchentlich, nicht täglich. Neue Veröffentlichungen werden innerhalb von Stunden nach ihrem Erscheinen im Amtsblatt erkannt.
Stufe 2: Klassifikation. Nicht alles, was veröffentlicht wird, erfordert dieselbe Behandlung. Ein neues Bundesgesetz, ein königlicher Erlass, ein Verwaltungsrundschreiben und eine Gerichtsentscheidung haben jeweils unterschiedliche Autoritätsstufen, unterschiedliche Geltungsbereiche und unterschiedliche Verarbeitungsanforderungen. Das System klassifiziert jedes Dokument nach Typ vor der Verarbeitung.
Stufe 3: Textextraktion. Die Rohveröffentlichung wird in strukturierten Text geparst. Das klingt einfach, bis man auf zweisprachige Formatierung, verschachtelte Artikelstrukturen, Tarieftabellen und Änderungssprache trifft, die auf Bestimmungen in anderen Gesetzbüchern verweist. Sowohl die niederländische als auch die französische Version sind authentisch — mehrsprachige Konsistenz muss gewahrt bleiben.
Stufe 4: Änderungsauflösung. Dies ist die schwierigste Stufe und diejenige, die die meisten Anbieter überspringen oder vereinfachen. Wenn ein Programmgesetz sagt „Artikel 215 des WIB 92 wird wie folgt geändert”, muss das System die bestehende Bestimmung identifizieren, die Änderung anwenden und eine neue Version erstellen, während die alte mit ihren Gültigkeitsdaten erhalten bleibt. Ein einzelnes Programmgesetz kann Dutzende dieser Operationen über mehrere Gesetzbücher hinweg auslösen.
Stufe 5: Chunking und Embedding. Der verarbeitete Text wird in semantisch bedeutungsvolle Einheiten aufgeteilt — nicht willkürliche Absätze, sondern artikelbewusste Chunks, die die juristische Struktur bewahren. Jeder Chunk wird in Vektorembeddings für semantische Suche umgewandelt, während der Volltext für Stichwortsuche indexiert wird. Metadaten werden angehängt: Inkrafttretensdatum, Autoritätsstufe, Zuständigkeit und Querverweise.
Stufe 6: Verifizierung. Bevor neue Inhalte in den Produktivkorpus eintreten, durchlaufen sie Qualitätskontrollen. Stimmt der geparste Text mit der veröffentlichten Quelle überein? Sind Artikelnummern korrekt extrahiert? Verweisen Querverweise auf bestehende Bestimmungen? Sind Inkrafttretensdaten genau? Diese Stufe fängt Parsing-Fehler ab, bevor sie zu schlechter Beratung werden.
Stufe 7: Auswirkungspropagation. Der Wissensgraph identifiziert, welche bestehenden Bestimmungen, Urteile und Kommentare von der Änderung betroffen sind. Gespeicherte Recherchen, die diese Bestimmungen zitieren, werden als potenziell veraltet markiert. Hier fügt das System einen Mehrwert hinzu, der über das bloße „Enthalten des neuen Gesetzes” hinausgeht — es sagt Ihnen, was sich sonst noch geändert hat, weil sich das Gesetz geändert hat.
Wo es schwierig wird: die Herausforderungen, über die niemand spricht
Änderungssprache ist mehrdeutig. „Der erste Absatz von Artikel 344 wird um einen Satz ergänzt…” — welcher Satz? Wo genau? Juristische Redaktion ist nicht immer präzise hinsichtlich der Einfügepunkte, und automatisiertes Parsing muss diese Mehrdeutigkeiten korrekt handhaben oder gar nicht.
Implizite Änderungen sind unsichtbar. Manche Gesetzesänderungen beeinflussen die Bedeutung bestehender Bestimmungen, ohne sie explizit zu ändern. Eine neue EU-Richtlinie kann nationales Recht überlagern, ohne dass der nationale Text modifiziert wird. Forschung zur Erkennung impliziter Änderungen zeigt eine Genauigkeit von nur 60 % — ein genuinely ungelöstes Problem (Huwiler et al., 2025).
Domänenübergreifende Kaskaden sind komplex. Eine Änderung im WIB 92 kann beeinflussen, wie TAK-23-Versicherungsprodukte besteuert werden, was wiederum die VCF-Erbschaftsteuerbehandlung in Flandern beeinflusst. Diese domänenübergreifenden Auswirkungen erfordern Wissensgraph-Reasoning, nicht bloße Textverarbeitung.
Zweisprachige Divergenz kommt vor. Die niederländische und französische Version belgischen Rechts sind beide authentisch, aber nicht immer perfekt abgeglichen. Übersetzungsunterschiede erzeugen gelegentlich genuine rechtliche Mehrdeutigkeit — und das System muss diese kennzeichnen, anstatt stillschweigend eine Version zu wählen.
Die Fragen, die Ihr Anbieter beantworten sollte
Wenn Ihr juristisches KI-Tool behauptet, „immer aktuell” zu sein, stellen Sie diese fünf Fragen:
| Frage | Warum es wichtig ist |
|---|---|
| Wie schnell nach der Veröffentlichung im Staatsblatt ist ein neues Gesetz durchsuchbar? | Stunden? Tage? Wochen? Die Lücke ist, wo das Risiko liegt |
| Wie werden Änderungen bestehender Bestimmungen verarbeitet? | Automatisiert? Manuell? Beides? Die Methode bestimmt die Genauigkeit |
| Wer verifiziert, dass aufgenommene Inhalte der veröffentlichten Quelle entsprechen? | Automatisierte Kontrollen? Menschliche Prüfung? Keines von beidem? |
| Was geschieht mit gespeicherten Recherchen, wenn sich das zugrunde liegende Recht ändert? | Wird der Nutzer benachrichtigt? Oder entdeckt er Veraltung auf die harte Tour? |
| Wie hoch ist die Fehlerquote Ihrer Ingestion-Pipeline? | Wenn sie diese Zahl nicht teilen wollen, fragen Sie warum |
Die Abwesenheit von Antworten auf diese Fragen ist selbst eine Antwort.
Häufige Fragen
Wie schnell sollte eine Gesetzesänderung in einem juristischen KI-System reflektiert werden?
Für kritische Änderungen — neue Steuersätze, geänderte Fristen, modifizierte Meldepflichten — ist die Aufnahme am selben Tag der angemessene Standard. Für weniger dringende Inhalte wie doktrinale Kommentare oder Entscheidungen unterer Gerichte sind 24–48 Stunden akzeptabel. Jedes System, das Wochen braucht, um veröffentlichte Gesetzesänderungen zu reflektieren, operiert auf einer Zeitlinie, die professionelles Risiko erzeugt.
Kann die Ingestion-Pipeline Fehler machen?
Ja. Parsing-Fehler, fehlerhafte Änderungsauflösung, übersehene Querverweise und Fehler bei der Metadatenextraktion kommen alle vor. Die Frage ist nicht, ob Fehler passieren — sondern ob das System sie erkennt und korrigiert, bevor sie den Fachmann erreichen. Deshalb existiert die Verifizierungsstufe, und deshalb sollte sie nie der Geschwindigkeit geopfert werden.
Warum ist zweisprachige Verarbeitung für belgisches Recht wichtig?
Sowohl die niederländische als auch die französische Version des föderalen belgischen Rechts sind gleichermaßen authentisch. Wenn ein System nur eine Sprachversion aufnimmt, verpasst es rechtliche Inhalte, die nur in der anderen existieren. Wichtiger noch: Wenn die beiden Versionen in ihrer Bedeutung divergieren — was vorkommt — sollte das System diese Divergenz kennzeichnen, anstatt stillschweigend eine Interpretation zu liefern.
Verwandte Artikel
- Was ist temporale Versionierung — und warum Ihr juristisches KI-Tool Ihnen wahrscheinlich das Gesetz von gestern liefert → /de/blog/temporale-versionierung-rechts-ki/
- Was ist Chunking — und warum es die unsichtbare Grundlage der Qualität juristischer KI ist → /de/blog/was-ist-chunking-rechts-ki/
- Was ist ein Wissensgraph — und warum er verändert, wie KI belgisches Steuerrecht navigiert → /de/blog/knowledge-graph-steuerrecht/
Wie Auryth TX das umsetzt
Auryth TX betreibt eine kontinuierliche Überwachung des Belgischen Staatsblatts und verwandter offizieller Quellen. Neue Gesetzgebung wird innerhalb von Stunden nach Veröffentlichung erkannt, klassifiziert und geparst. Die Pipeline verwendet artikelbewusstes Chunking, das die hierarchische Struktur belgischer Rechtstexte bewahrt, wobei Änderungen gegen bestehende Bestimmungen aufgelöst werden, um die Versionshistorie zu pflegen.
Jedes aufgenommene Dokument durchläuft eine automatisierte Verifizierung, bevor es in den Produktivkorpus eintritt. Der Wissensgraph propagiert Änderungen an betroffene Bestimmungen, und gespeicherte Recherchen, die auf betroffene Artikel verweisen, werden zur Überprüfung markiert. Wir behaupten keine perfekte Aufnahme — wir behaupten transparente Aufnahme, bei der Fehler erkannt und korrigiert statt verborgen werden.
Wenn sich belgisches Steuerrecht morgen ändert, weiß unser System es morgen. Nicht nächste Woche. Nicht „irgendwann.”
Quellen: 1. Huwiler, D. et al. (2025). „VersionRAG: Version-Aware Retrieval-Augmented Generation for Evolving Documents.” arXiv preprint. 2. Premasiri, D. et al. (2025). „Survey on legal information extraction: current status and open challenges.” Knowledge and Information Systems, 67, 11287-11358. 3. Ariai, F. & Demartini, G. (2024). „Natural Language Processing for the Legal Domain: A Survey.” ACM Computing Surveys.