KI-Halluzinationen: warum ChatGPT Quellen erfindet (und wie Sie es erkennen)
Warum Sprachmodelle juristische Quellen fabrizieren, was belgisches Steuerrecht besonders anfällig macht, und drei Verteidigungslinien, die funktionieren.
Von Auryth Team
Stanford-Forscher testeten die teuersten juristischen KI-Tools auf dem Markt — Westlaw AI, Lexis+ AI — und stellten fest, dass sie bei 17–33 % der Anfragen Informationen fabrizieren. Allgemeine Modelle wie ChatGPT? Zwischen 58 % und 88 %.
Diese Zahlen sind keine Bugs auf einer Roadmap. Es sind Eigenschaften von Systemen, die nie dafür konzipiert wurden, juristische Fakten von plausibler Fiktion zu unterscheiden.
Was ist eine KI-Halluzination?
Eine KI-Halluzination tritt auf, wenn ein Sprachmodell eine Ausgabe erzeugt, die autoritativ klingt, aber sachlich falsch ist — erfundene juristische Zitate, nicht existierende Artikelnummern, fabrizierte Statistiken oder falsche Steuersätze mit absoluter Sicherheit präsentiert. Das Modell lügt nicht. Es sagt das wahrscheinlichste nächste Wort voraus, basierend auf Mustern in seinen Trainingsdaten. Wenn diese Muster die spezifische belgische Rechtsvorschrift, die Sie benötigen, nicht enthalten, füllt es die Lücke mit etwas, das richtig klingt.
Sprachmodelle rufen keine Informationen ab. Sie erzeugen plausiblen Text. Der Unterschied ist die Kluft zwischen einem Bibliothekar, der das Regal prüft, und einem Kollegen, der aus dem Gedächtnis antwortet — und nie zugibt, wenn er rät.
Warum Steuerrecht Halluzinationsterritorium ist
Nicht alle Fachgebiete sind gleich verwundbar. Bitten Sie ein Sprachmodell, einen Nachrichtenartikel zusammenzufassen, und Halluzinationen sind ein Ärgernis. Fragen Sie es nach Art. 344 WIB (Wetboek van de Inkomstenbelastingen) — der belgischen allgemeinen Missbrauchsbekämpfungsvorschrift — und Sie betreten ein Minenfeld.
Drei Faktoren machen Steuerrecht besonders gefährlich:
Präzisionsabhängigkeit. Der Unterschied zwischen 0,12 % und 1,32 % TOB (Steuer auf Börsengeschäfte, Belgiens Börsensteuer) ist der Unterschied zwischen korrekter Beratung und einem Haftungsanspruch. Sprachmodelle optimieren für plausiblen Text, nicht für präzise Zahlen. „Ungefähr richtig” gibt es in der professionellen Steuerpraxis nicht.
Referenzdichte. Eine einzelne belgische Steuerantwort kann gleichzeitig Art. 19bis WIB, den Vlaamse Codex Fiscaliteit, eine DVB-Vorabentscheidung und ein Fisconetplus-Rundschreiben erfordern. Allgemeine KI hat die meisten dieser Dokumente nie verarbeitet. Also erzeugt sie Verweise, die wie echte aussehen.
Zeitliche Instabilität. Belgisches Steuerrecht ändert sich ständig. Der Körperschaftssteuersatz, TOB-Schwellenwerte, regionale Erbschaftssteuersätze — alles bewegliche Ziele. Ein vor sechs Monaten trainiertes Sprachmodell gibt Ihnen das Recht von gestern mit der Zuversicht von heute.
Die fünf Anzeichen: wie Sie eine halluzinierte Steuerantwort erkennen
Halluzinationen hinterlassen Fingerabdrücke. Nach der Analyse von Hunderten KI-generierter Steuerantworten treten fünf Muster konsistent auf:
| Anzeichen | Wie es aussieht | Beispiel |
|---|---|---|
| Sicherheit ohne Quelle | Definitive Antwort, kein Artikelverweis | „Der TOB-Satz beträgt 0,35 %” — welches Instrument? Unter welchen Bedingungen? |
| Die zu perfekte Referenz | Plausibel klingender Artikel, der nicht existiert | Eine Artikelnummer mit Absätzen, die wie echtes belgisches Steuerrecht aussieht, aber im WIB 92 nicht zu finden ist |
| Jurisdiktionsvermischung | Regeln aus dem falschen Land als belgisch dargestellt | Niederländische Quellensteuersätze auf einen belgischen Steuerpflichtigen angewandt |
| Zeitliche Blindheit | Aktuelle Sätze für eine historische Frage | Körperschaftssteuersatz von 2026 für das Steuerjahr 2019 |
| Fehlende Nuancen | Saubere Antwort, wo das Gesetz komplex ist | Ein TOB-Satz, wenn drei gelten — je nach Fondsklassifizierung |
Das letzte Anzeichen ist das gefährlichste. Eine erfundene Artikelnummer ist leicht zu entdecken — Sie suchen sie und sie existiert nicht. Eine unvollständige Antwort, die vollständig klingt? Da verbrennen sich Fachleute und verlieren Mandanten Geld.
Ein Modell, das nie „ich weiß es nicht” sagt, lügt häufiger als Sie denken.
Die Vertrauens-Kompetenz-Inversion
Hier ist die kontraintuitive Wahrheit über den KI-Fortschritt: Je besser Modelle in Sprache werden, desto schlechter werden sie darin, zu signalisieren, wenn sie etwas nicht wissen.
GPT-3 halluzinierte offensichtlich — unbeholfener Text, sichtbare Fehler. GPT-4 halluziniert eloquent. Die erfundene juristische Referenz kommt verpackt in flüssiger Rechtsterminologie, komplett mit Bedingungen und Ausnahmen, die echtem Steuerrecht ähneln.
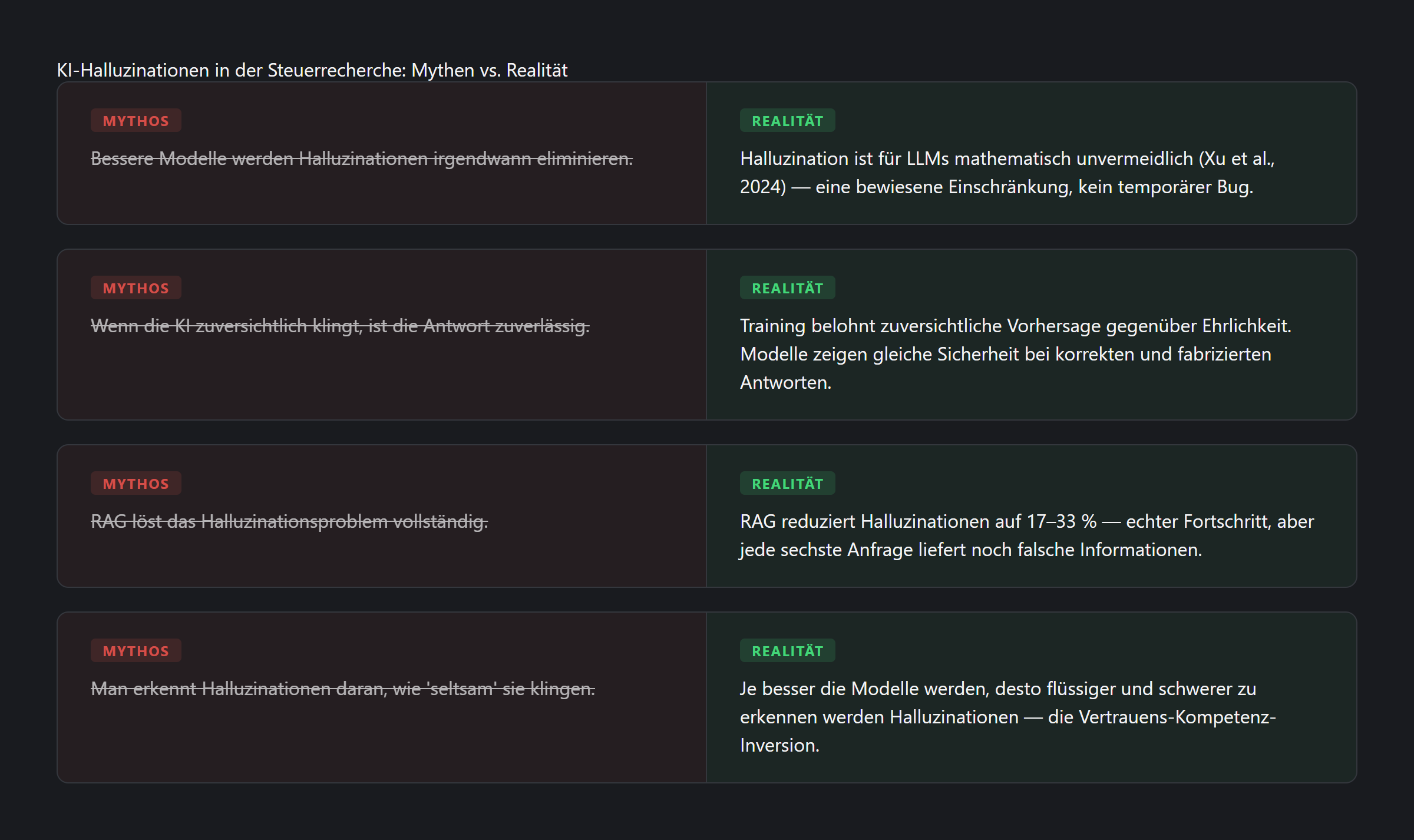
OpenAI-Forscher dokumentierten diese Dynamik 2025: Trainingsziele belohnen zuversichtliche Vorhersage gegenüber ehrlicher Unsicherheit. Das Modell, das „ich bin nicht sicher” sagt, wird in Benchmarks bestraft. Das Modell, das eine plausible Antwort erfindet, wird belohnt.
Das ist kein Bug, der behoben werden kann. Xu et al. bewiesen 2024 formal, dass Halluzination für Sprachmodelle, die als allgemeine Problemlöser eingesetzt werden, mathematisch unvermeidlich ist. Nicht schwer zu eliminieren. Nicht eine vorübergehende Einschränkung. Unmöglich — per Beweis.
Wir nennen dies die Vertrauens-Kompetenz-Inversion: Je besser die Sprache, desto schwieriger wird es, Wissen von Fabrikation zu unterscheiden. Jede Modellgeneration macht Halluzinationen gefährlicher, nicht weniger.

Aber RAG behebt das — oder?
Teilweise. Retrieval-Augmented Generation — bei der die KI echte Dokumente durchsucht, bevor sie antwortet — reduziert Halluzinationen erheblich. Das Stanford-Team stellte fest, dass RAG-basierte juristische Tools bei 17–33 % der Anfragen halluzinieren, verglichen mit 58–88 % bei allgemeinen Modellen. Das ist echter Fortschritt.
Aber 17 % ist nicht null. Jede sechste Anfrage, die falsche Informationen liefert, ist kein Rundungsfehler — es ist ein professionelles Risiko. Und die verbleibenden Halluzinationen sind die am schwersten zu erkennenden: Sie zitieren echt aussehende Quellen, entsprechen dem Format korrekter Antworten und geben kein Signal, dass etwas falsch ist.
Die Orde van Vlaamse Balies (Kammer der Flämischen Rechtsanwälte) erkannte diese Realität in ihren KI-Richtlinien an: Anwälte müssen alle KI-Ausgaben kritisch überprüfen, einschließlich zitierter Quellen und Rechtsprechung. Die berufliche Verantwortung bleibt bei Ihnen, unabhängig davon, welches Tool die Antwort generiert hat.
International setzen Gerichte dies mit zunehmender Strenge durch. Ende 2025 waren weltweit über 700 dokumentierte Fälle von KI-halluzinierten Inhalten in Gerichtsverfahren aufgetreten. Sanktionen reichen von 2.000 $ bis über 31.000 $ pro Vorfall. Allein im August 2025 sanktionierten drei separate US-Bundesgerichte Anwälte für die Einreichung KI-fabrizierter Zitate.
Der Verifizierungsstapel: drei Verteidigungen, die funktionieren
Halluzinationen können nicht eliminiert werden. Aber sie können abgefangen werden. Drei architektonische Verteidigungsschichten, kombiniert, reduzieren das Risiko von systemisch auf handhabbar:
| Verteidigung | Was sie tut | Was sie abfängt |
|---|---|---|
| Quellengestützte Retrieval | Durchsucht einen kuratierten Rechtskorpus vor der Generierung | Verhindert das Erfinden von Fakten, die nie abgerufen wurden |
| Zitationsvalidierung | Prüft jede zitierte Quelle gegen den tatsächlichen Korpus | Fängt fabrizierte Referenzen und falsch zugeordnete Inhalte ab |
| Konfidenzscoring | Signalisiert Unsicherheit explizit bei jeder Behauptung | Markiert dünne Beweislage, bevor Sie sich darauf verlassen |
Keine einzelne Schicht ist für sich ausreichend. Quellengestützte Retrieval halluziniert noch — Stanford hat das bewiesen. Zitationsvalidierung fängt fabrizierte Referenzen ab, aber keine subtilen Fehlinterpretationen. Konfidenzscoring markiert Unsicherheit, erfordert aber Kalibrierung.
Die Kombination ist entscheidend. Jede Schicht fängt auf, was die anderen verpassen.
Die Kosten falscher Gewissheit sind immer höher als die Kosten ehrlicher Unsicherheit.
Verwandte Artikel
- Ich stellte ChatGPT und Auryth dieselben belgischen Steuerfragen — das ist passiert
- Was ist RAG — und warum es für Steuerberater wichtig ist
- Was ist Confidence Scoring — und warum ist es ehrlicher als eine selbstsichere Antwort?
Wie Auryth TX das umsetzt
Auryth TX basiert auf der Annahme, dass Halluzinationen unvermeidlich sind — und gestaltet darum herum, anstatt so zu tun, als würden sie nicht auftreten.
Jede Antwort durchläuft eine dreistufige Verifizierungspipeline: Retrieval aus dem kuratierten belgischen Rechtskorpus (nicht dem offenen Internet), Post-Generations-Zitationsvalidierung, die jede referenzierte Bestimmung gegen den tatsächlichen Text prüft, und Konfidenzscoring pro Behauptung, das explizit markiert, wenn die Beweislage dünn ist.
Wenn das System nicht genügend Quellen findet, teilt es Ihnen das mit. Wenn Quellen einander widersprechen, zeigt es beide Seiten. Wenn eine zitierte Bestimmung seit dem relevanten Steuerjahr geändert wurde, markiert es die zeitliche Abweichung.
Das Ziel ist nicht, zu 100 % Recht zu haben. Es ist, Ihnen immer zu sagen, wie sehr Sie der Antwort vertrauen können.
Entdecken Sie, wie Auryth TX Verifizierung handhabt →
Quellen: 1. Dahl, M. et al. (2024). „Large Legal Fictions: Profiling Legal Hallucinations in Large Language Models.” Journal of Legal Analysis, 16(1), 64–93. 2. Magesh, V. et al. (2025). „Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools.” Journal of Empirical Legal Studies. 3. Xu, Z., Jain, S. & Kankanhalli, M. (2024). „Hallucination is Inevitable: An Innate Limitation of Large Language Models.” arXiv:2401.11817. 4. Kalai, A.T., Nachum, O., Vempala, S.S. & Zhang, E. (2025). „Why Language Models Hallucinate.” OpenAI.