Was ist RAG — und warum es allein nicht für juristische KI ausreicht
Wie Retrieval-Augmented Generation funktioniert, warum einfaches RAG noch halluziniert, und was eine Such-RAG-Fusionsarchitektur für Steuerberater bringt.
Von Auryth Team
Jede KI-Antwort ohne Quellenangabe ist eine Meinung, die als Recherche verkleidet wird. Das klingt hart — bis Sie feststellen, dass die meisten KI-Tools, die Fachleute heute nutzen, genau das tun: selbstsicheren Text aus dem Gedächtnis generieren, ohne Möglichkeit zu prüfen, woher die Antwort stammt.
Die Architektur, die dieses Problem zu lösen begann, hat einen Namen: RAG. Aber einfaches RAG ist nur der Anfang. Zu verstehen, was es leistet — und wo es versagt — ist das Wichtigste, was ein Steuerberater 2026 über KI lernen kann.
Was ist Retrieval-Augmented Generation?
Retrieval-Augmented Generation (RAG) ist eine KI-Architektur, bei der das System zunächst eine Wissensbasis nach relevanten Dokumenten durchsucht und diese Dokumente dann — zusammen mit Ihrer Frage — an ein Sprachmodell sendet, das eine Antwort auf Basis der gefundenen Informationen formuliert. Anders als Chatbots, die aus dem Gedächtnis antworten, stützt ein RAG-System jede Antwort auf abrufbare Quellen.
Stellen Sie sich den Unterschied zwischen zwei Kollegen vor. Der eine beantwortet Ihre Steuerfrage aus dem Gedächtnis — selbstsicher, manchmal richtig, manchmal nicht. Der andere geht in die Bibliothek, holt die einschlägigen Bestimmungen, liest sie und gibt Ihnen eine Antwort mit Seitenzahlen. RAG ist der zweite Kollege.
Das Konzept wurde von Lewis et al. in einem Paper von 2020 auf der NeurIPS formalisiert, wobei parametrisches Gedächtnis (das trainierte Wissen des Sprachmodells) mit nicht-parametrischem Gedächtnis (einem durchsuchbaren Dokumentenindex) kombiniert wurde. Die Erkenntnis war einfach, aber transformativ: Statt ein Modell alles auswendig lernen zu lassen, lässt man es nachschlagen.
Warum einfaches RAG nicht ausreicht
Hier ist, was die meisten RAG-Erklärungen verschweigen: Vanilla-RAG — Dokumente in eine Vektordatenbank laden, ein Sprachmodell anschließen, fertig — halluziniert noch immer bei 17–33 % der juristischen Anfragen. Stanford-Forscher bewiesen dies durch Tests an Westlaw AI und Lexis+ AI, beides RAG-basierte Systeme der größten juristischen Verlage weltweit.
Warum? Weil juristischer Text nicht wie Wikipedia-Artikel ist. Er hat eine Struktur, die einfaches RAG ignoriert:
Hierarchie. Ein Urteil des Kassationshofs überwiegt ein Fisconetplus-Rundschreiben. Einfaches RAG behandelt sie als gleichwertige Textfragmente. Wenn ein Rundschreiben der Rechtsprechung widerspricht, wählt ein System ohne Autoritätsbewusstsein den Text, der am besten zu Ihrer Anfrage passt — und das kann der falsche sein.
Temporalität. Der belgische Körperschaftsteuersatz betrug 2019 29,58 % und liegt heute bei 25 %. Einfaches RAG ruft die Version ab, die seine Vektorsuche zuerst findet. Fragen Sie nach 2019 und Sie erhalten möglicherweise den Satz von 2026 — mit voller Überzeugung dargestellt.
Querverweise. Eine einzelne Steuerfrage kann gleichzeitig Art. 19bis WIB, den TOB-Rahmen und eine Bestimmung der Vlaamse Codex Fiscaliteit umfassen. Einfaches RAG ruft Fragmente ab. Es versteht nicht, dass diese Bestimmungen zusammenwirken.
Der Generierungsschritt verschärft das Problem. Selbst bei korrektem Abruf kann das Sprachmodell falsch interpretieren, übergeneralisieren oder Quellen auf Weisen kombinieren, die die Originaltexte nicht stützen. Zitationsvalidierung — die Prüfung, ob jede zitierte Quelle tatsächlich das aussagt, was das Modell ihr zuschreibt — ist eine notwendige zusätzliche Schicht, die einfaches RAG nicht umfasst.
Dokumente in eine Vektordatenbank zu laden ist das minimale RAG. Für juristische Arbeit ist es das maximale Haftungsrisiko.
Von einfachem RAG zur Such-RAG-Fusion
Die Erkenntnis, die professionelle juristische KI von einer Demo unterscheidet, ist diese: RAG ist eine Generierungsstrategie, keine Suchstrategie. Der „Abruf” in RAG ist nur so gut wie die Suchinfrastruktur darunter.
Eine Such-RAG-Fusionsarchitektur schichtet professionelle Suchfähigkeiten vor dem Sprachmodell:
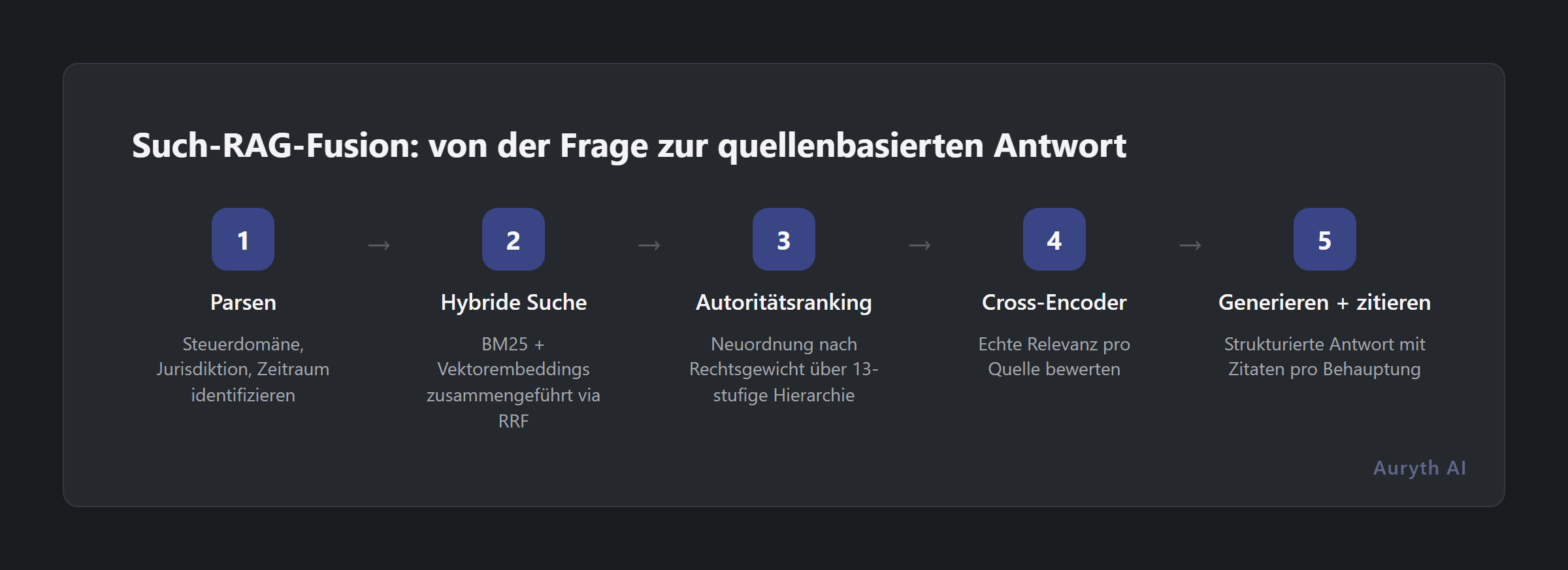
| Schritt | Was passiert | Warum einfaches RAG das nicht kann |
|---|---|---|
| 1. Parsing | Das System identifiziert den Steuerbereich, die Jurisdiktion und den Zeitraum aus Ihrer Frage | Einfaches RAG kodiert nur die Rohfrage — kein Domänenbewusstsein |
| 2. Hybride Suche | Zwei Suchstrategien laufen parallel: BM25 (exakte juristische Begriffe wie „Art. 344 WIB”) und Vektor-Embeddings (semantische Bedeutung). Ergebnisse werden via Reciprocal Rank Fusion zusammengeführt | Einfaches RAG nutzt nur Vektorsuche — übersieht exakte Artikelverweise |
| 3. Autoritätsranking | Ergebnisse werden nach juristischem Gewicht neu geordnet: Verfassung → EU-Recht → Bundesgesetze → Rechtsprechung → Rundschreiben → Doktrin | Einfaches RAG behandelt alle Dokumente gleich |
| 4. Cross-Encoder-Reranking | Ein spezialisiertes Modell liest jede Quelle neben Ihrer Frage und bewertet die tatsächliche Relevanz | Einfaches RAG verlässt sich auf Embedding-Ähnlichkeit, die Nuancen übersieht |
| 5. Generierung + Zitation | Das Sprachmodell liest die geordneten Quellen und erstellt eine strukturierte Antwort — jede Behauptung mit ihrer Quelle verknüpft | Wie einfaches RAG, aber mit weit besseren Inputs |
Der Unterschied zwischen Schritt 2 allein (einfaches RAG) und den Schritten 1–4 zusammen (Such-RAG-Fusion) ist der Unterschied zwischen einen relevanten Text finden und das richtige Gesetz, von der richtigen Autorität, zum richtigen Zeitpunkt finden.
Warum Überprüfbarkeit wichtiger ist als Genauigkeit
Die meisten RAG-Erklärungen fokussieren auf Genauigkeit — RAG reduziert Halluzinationen, RAG liefert bessere Antworten. Das stimmt, verfehlt aber den Kern.
Der wahre Vorteil ist nicht Genauigkeit. Es ist Überprüfbarkeit.
Ein feinabgestimmtes Modell mag zu 95 % genau sein. Ein Such-RAG-System zu 92 %. Aber das Such-RAG-System zeigt Ihnen genau, welche Quellen es verwendet hat, geordnet nach juristischer Autorität, sodass Sie die 8 % selbst prüfen können. Das feinabgestimmte Modell bietet keine Möglichkeit zu wissen, welche Antworten zu den 5 % gehören.
Für einen Steuerberater ist dieser Unterschied entscheidend. Ihre Berufshaftung hängt nicht von der Genauigkeit des Tools ab. Sie hängt davon ab, ob Sie die Beratung, die Sie Ihrem Mandanten gegeben haben, verifiziert haben.
Die Frage ist nicht „Ist diese KI genau?” Die Frage ist „Kann ich es überprüfen?”
Wir nennen dies das Überprüfbarkeitsprinzip: Ein Tool, das zu 90 % genau und transparent ist, ist sicherer als eines, das zu 95 % genau und undurchsichtig ist. Jeder Prozentpunkt Genauigkeit, den Sie nicht überprüfen können, ist ein Haftungsrisiko, das Sie nicht steuern können.
Such-RAG-Fusion vs. Fine-Tuning: die Bibliothek vs. das Lehrbuch
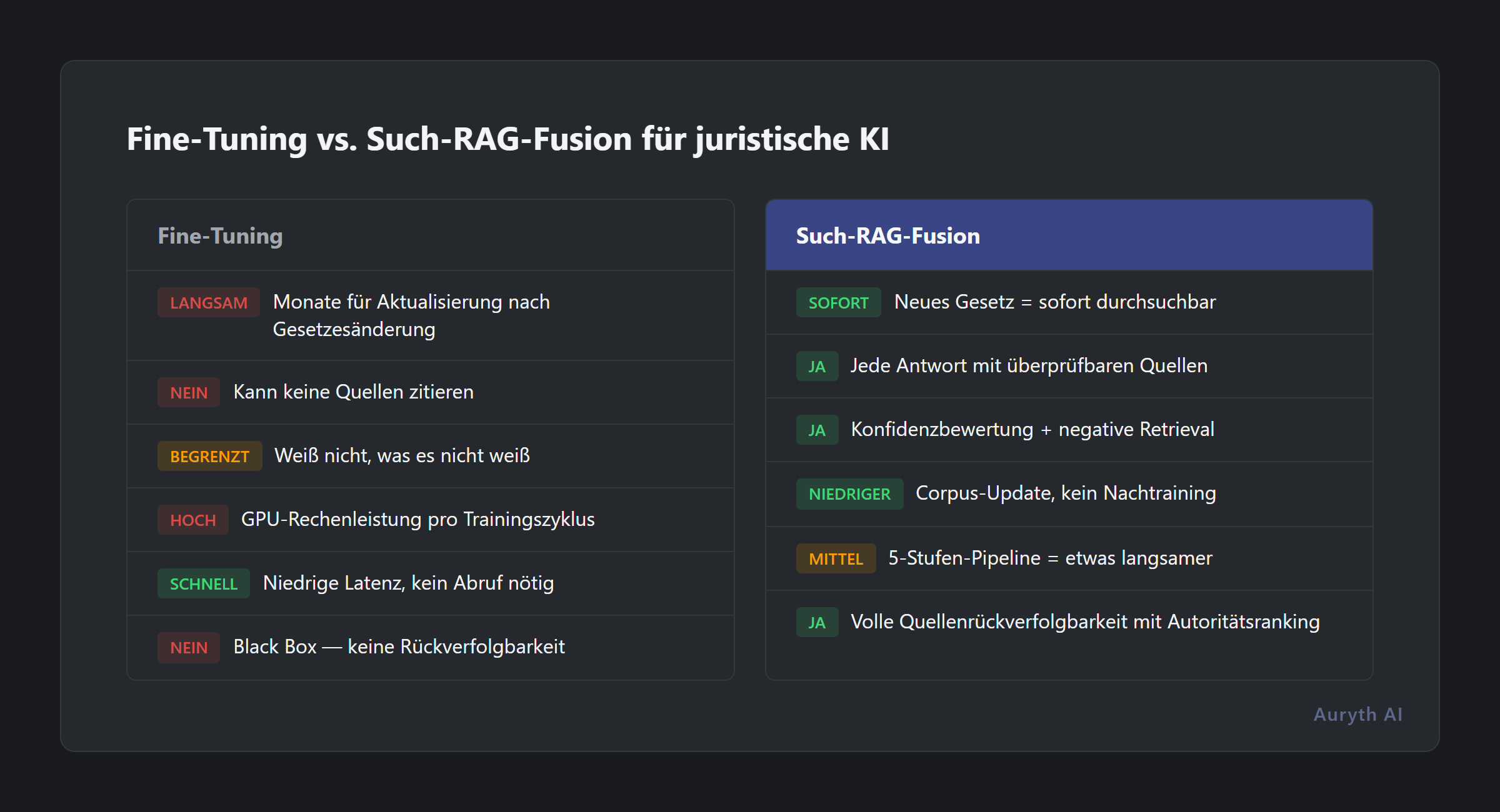
Die wichtigste Alternative zu RAG-basierten Ansätzen ist Fine-Tuning — ein Modell auf domänenspezifischen Daten zu trainieren, sodass das Wissen in seine Gewichte eingebrannt wird. Stellen Sie sich vor: ein Lehrbuch auswendig lernen versus Zugang zu einer Bibliothek mit einem professionellen Bibliothekar.
| Aspekt | Fine-Tuning | Such-RAG-Fusion |
|---|---|---|
| Wissensquelle | In Modellgewichte eingebrannt | Aus einem kuratierten, strukturierten Corpus abgerufen |
| Aktualisierbarkeit | Modell neu trainieren (Wochen, teuer) | Corpus aktualisieren (Stunden, günstig) |
| Transparenz | Black Box — Antworten nicht zu Quellen rückverfolgbar | Vollständige Zitationskette mit Autoritätsranking |
| Eignung für belgisches Steuerrecht | Gesetze ändern sich schneller als Modelle nachtrainiert werden | Neue Bestimmung = sofort durchsuchbar mit Metadaten |
| Kosten | Hoch (GPU-Rechenleistung für Training) | Niedriger (Suchinfrastruktur) |
| Halluzinationsrisiko | Halluziniert selbstsicher, keine Möglichkeit zur Überprüfung | Kann noch halluzinieren, aber jede Quelle ist überprüfbar |
Harvey, gestützt durch über eine Milliarde Dollar an Investitionen, wählte zunächst Fine-Tuning für seine US-fokussierte juristische KI. Das ergibt Sinn für ein relativ stabiles Rechtssystem mit tiefen Taschen für kontinuierliches Nachtraining. Belgisches Steuerrecht — mit drei Regionen, zwei Amtssprachen, ständigen Gesetzesänderungen und einer Regulierungslandschaft, die sich quartalsweise verschiebt — erfordert einen anderen Ansatz.
Wenn sich die flämischen Erbschaftssteuertarife ändern, braucht ein feinabgestimmtes Modell ein Nachtraining. Ein Such-RAG-System braucht eine Corpus-Aktualisierung.
Wie das in der belgischen Steuerpraxis aussieht
Betrachten Sie eine Frage, der jeder belgische Steuerberater begegnen kann: „Welche TOB-Folgen hat der Wechsel von einem ausschüttenden zu einem thesaurierenden ETF?”
Ein allgemeines Sprachmodell wird auf Basis von Trainingsdaten antworten — die möglicherweise Monate oder Jahre veraltet sind, belgische und niederländische Regeln verwechseln können und den spezifischen Artikel im WIB 92 oder das relevante Fisconetplus-Rundschreiben nicht zitieren können.
Ein Such-RAG-Fusionssystem für belgisches Steuerrecht geht so vor:
- Parst die Frage — identifiziert TOB als Steuerbereich, bestimmt den relevanten Veranlagungszeitraum, erkennt, dass die Fondsklassifizierung relevant ist
- Durchsucht das belgische juristische Corpus mit hybrider Suche — BM25 findet „TOB” und spezifische Artikelnummern exakt, Vektorsuche findet semantisch verwandte Bestimmungen zur Fondsbesteuerung
- Ordnet nach Autorität — eine gesetzliche Bestimmung überwiegt ein Rundschreiben; ein Urteil des Kassationshofs überwiegt Doktrin
- Rerankt nach Relevanz — ein Cross-Encoder-Modell bewertet jeden Kandidaten gegen Ihre tatsächliche Frage und filtert Fehlalarme
- Generiert eine strukturierte Antwort mit Verweis auf jede Quelle, mit einem Konfidenzwert pro Behauptung
- Signalisiert Lücken — wenn keine spezifische Entscheidung zu einer Nuance Ihrer Frage existiert, teilt es Ihnen das mit
Dieser letzte Punkt ist mindestens so wichtig wie die Antwort selbst. In der professionellen Steuerpraxis ist das Wissen, dass zu einem bestimmten Punkt keine Autorität existiert, eine wertvolle Information — es bedeutet, dass Sie sich in Interpretationsgebiet befinden und entsprechend handeln sollten.
Die ehrlichen Grenzen
Selbst ein gut konzipiertes Such-RAG-Fusionssystem hat reale Einschränkungen:
Die Abrufqualität ist die Obergrenze. Wenn das richtige Dokument nicht im Corpus ist oder die Suchpipeline es nicht hochspült, kann das Modell es nicht verwenden. Das System ist nur so gut wie seine Wissensbasis und seine Suchalgorithmen.
Der Generierungsschritt kann noch immer fabrizieren. Selbst bei perfektem Abruf und Ranking kann das Sprachmodell Quellen falsch interpretieren oder auf Weisen kombinieren, die die Originaltexte nicht stützen. Deshalb ist Zitationsvalidierung — die unabhängige Prüfung, ob jede zitierte Quelle das aussagt, was das Modell behauptet — eine notwendige Post-Generierungsschicht.
Komplexität hat ihren Preis. Eine Fünf-Stufen-Pipeline ist langsamer als eine einzelne Vektorabfrage. Der Kompromiss lohnt sich für professionelle Arbeit, bei der Korrektheit wichtiger ist als Geschwindigkeit — aber es ist ein Kompromiss.
Die ehrliche Bewertung: Such-RAG-Fusion reduziert das Problem von katastrophal (58–88 % Halluzination bei allgemeinen Sprachmodellen) auf handhabbar (deutlich unter den 17–33 % von einfachem juristischem RAG, mit zusätzlichen Verifikationsschichten). Aber „handhabbar” bedeutet immer noch, dass professionelles Urteilsvermögen unerlässlich bleibt. Das System beschleunigt Ihre Recherche — es ersetzt Ihre Expertise nicht.
Verwandte Artikel
- KI-Halluzinationen: warum ChatGPT Quellen erfindet (und wie Sie das erkennen)
- Ich habe ChatGPT und Auryth die gleichen belgischen Steuerfragen gestellt — das ist passiert
- Fine-Tuning vs. RAG: zwei Wege, KI intelligent zu machen
Wie Auryth TX das umsetzt
Auryth TX verwendet kein einfaches RAG. Es fusioniert professionelle Suchinfrastruktur mit Retrieval-Augmented Generation — weil die Qualität des Abrufs die Qualität der Antwort bestimmt.
Jede Frage durchläuft eine Fünf-Stufen-Pipeline: hybride Suche (BM25 + Vektor-Embeddings zusammengeführt via Reciprocal Rank Fusion), Autoritätsranking über eine 13-stufige belgische Rechtshierarchie, Cross-Encoder-Reranking für Präzision, strukturierte Antwortgenerierung mit Zitaten pro Behauptung und Post-Generierungs-Zitationsvalidierung mit Konfidenzwertung.
Das belgische juristische Corpus ist unsere Wissensbasis: WIB 92, Fisconetplus, DVB-Vorabentscheidungen, VCF, Gerichtsentscheidungen und doktrinäre Publikationen — alles strukturiert mit temporalen Metadaten, Jurisdiktionstags und Autoritätsstufen. Wenn Quellen sich widersprechen, werden beide Seiten gezeigt. Wenn die Beweislage dünn ist, sagt Ihnen der Konfidenzwert das ausdrücklich. Wenn sich das Gesetz ändert, wird das Corpus innerhalb von Stunden aktualisiert.
Wir bitten Sie nicht, der KI zu vertrauen. Wir bitten Sie, die Quellen zu prüfen, die sie Ihnen zeigt. Das ist das Überprüfbarkeitsprinzip in der Praxis.
Erfahren Sie, wie unsere Such-RAG-Pipeline funktioniert — zur Warteliste →
Quellen: 1. Lewis, P. et al. (2020). „Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.” NeurIPS. 2. Magesh, V. et al. (2025). „Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools.” Journal of Empirical Legal Studies. 3. Schwarcz, D. et al. (2025). „AI-Powered Lawyering: AI Reasoning Models, Retrieval Augmented Generation, and the Future of Legal Practice.” SSRN.