Was die Stanford-Hallucinationsstudie wirklich enthüllt hat — und warum die Reaktion der Branche den Punkt verfehlt hat
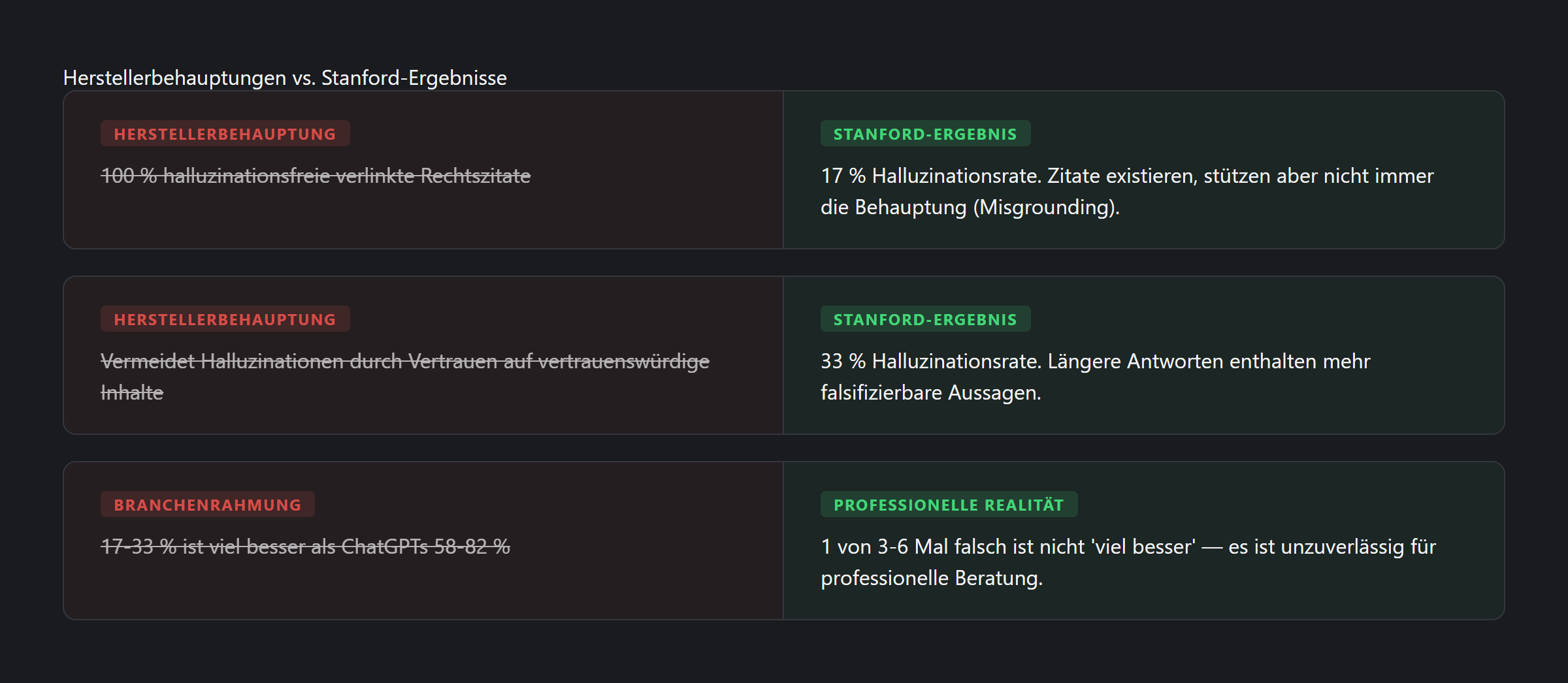
Stanford fand heraus, dass Premium-KI-Rechtstools in 17-33% der Fälle halluzinieren. Aber der gefährlichste Befund war nicht die Halluzinationsrate — es war Misgrounding.
Von Auryth Team
Der gefährlichste KI-Fehler ist nicht der offensichtlich falsche. Es ist der, der genau richtig aussieht.
Im Mai 2024 veröffentlichten Forscher des Stanford RegLab die erste präregistrierte empirische Evaluation kommerzieller juristischer KI-Tools (Magesh et al., 2024). Sie testeten Lexis+ AI, Ask Practical Law AI und später Westlaw AI-Assisted Research mit 202 juristischen Abfragen, handbewertet von Rechtsexperten. Die Schlagzeile — Halluzinationsraten von 17–33 % — schockierte die Branche.
Was Stanford wirklich fand
| Tool | Akkurat | Unvollständig | Halluziniert |
|---|---|---|---|
| Lexis+ AI | 65 % | 18 % | 17 % |
| Ask Practical Law AI | 19 % | 62 % | 17 % |
| Westlaw AI-Assisted Research | 42 % | 25 % | 33 % |
| GPT-4 (Referenz, frühere Studie) | — | — | 58–82 % |
Das Fazit der Stanford-Forscher war unmissverständlich: „Die Behauptungen der Anbieter sind übertrieben.”
Misgrounding: der Befund, den alle übersehen haben
Fabrikation ist, was die meisten sich unter „KI-Halluzination” vorstellen. Die KI erfindet einen Fall, der nicht existiert. Peinlich, aber auffindbar.
Misgrounding ist subtiler und gefährlicher. Die KI beschreibt das Recht korrekt, zitiert einen realen Fall, der tatsächlich existiert, aber der zitierte Fall stützt die gemachte Behauptung nicht. Das Zitat ist gültig. Die juristische Aussage klingt korrekt. Aber die Quelle sagt nicht, was die KI behauptet, dass sie sagt.
Dies übersteht oberflächliche Kontrolle. Ein zeitlich unter Druck stehender Fachmann, der zur Quelle durchklickt, den Leitsatz liest, das richtige Rechtsgebiet sieht und weitergeht.
Das gefährlichste Zitat ist das, das existiert, aber nicht sagt, was Sie denken, dass es sagt.
Der „besser als ChatGPT”-Trugschluss
Die dominante Branchenreaktion: „17–33 % ist dramatisch besser als ChatGPTs 58–82 %. RAG funktioniert.”
Dieses Framing ist aus drei Gründen falsch. Ein Premium-Profitool mit einem kostenlosen Verbraucher-Chatbot zu vergleichen ist wie die Flugsicherheit einer Airline mit der eines Fahrrads zu vergleichen. Würden Sie einen Junioranwalt behalten, der 1 von 3–6 Antworten falsch hat? In der Medizin würde ein Diagnosetool mit 17–33 % Fehlerrate nie als „halluzinationsfrei” vermarktet.
Was das für belgische Steuerfachleute bedeutet
Belgisches Steuerrecht ist genau die Domäne, wo diese Fehlermodi am gefährlichsten sind.
Jurisdiktionsverwechslung. Belgisches Steuerrecht operiert über föderale, flämische, wallonische und Brüsseler Ebenen. Ein KI-Tool, das föderale WIB-92-Bestimmungen mit flämischen VCF-Bestimmungen verwechselt, produziert genau die Art von misgrounded Output, die Stanford identifiziert hat.
Autoritätshierarchie-Verletzungen. Ein Rundschreiben des FÖD Finanzen hat nicht dasselbe rechtliche Gewicht wie ein Gesetzesartikel oder ein Urteil des Kassationshofs.
Zeitliche Fehlanwendung. Belgisches Steuerrecht ändert sich häufig. Ein KI-Tool, das ein korrektes Rechtsprinzip aus einer überholten Gesetzesversion abruft, produziert Beratung, die letztes Jahr richtig, aber heute falsch ist.
Das Verifikationsparadox
Wenn jedes KI-generierte Zitat manuell gegen die Primärquelle verifiziert werden muss, was genau ist dann die Zeitersparnis? Der Wert ist nicht „weniger verifizieren.” Er ist „breiter suchen, verifizieren was das Tool findet, und Verbindungen erkennen, die man manuell verpasst hätte.”
Häufige Fragen
Bedeutet die Stanford-Studie, dass juristische KI-Tools nutzlos sind?
Nein. Sie bedeutet, dass ihre Genauigkeit niedriger ist als Anbieter behaupteten, und dass professionelle Verifikation essenziell bleibt.
Warum hatte Westlaw eine höhere Halluzinationsrate als Lexis?
Die Forscher führten dies teilweise auf die Antwortlänge zurück. Westlaw generiert längere, detailliertere Antworten — die mehr falsifizierbare Propositionen enthalten.
Verwandte Artikel
- KI-Halluzinationen: warum ChatGPT Quellen erfindet → /de/blog/ki-halluzinationen-steuer/
- Warum Transparenz wichtiger ist als Genauigkeit → /de/blog/transparenz-vs-genauigkeit/
- Was ist Konfidenz-Scoring → /de/blog/confidence-scoring-erklaert/
Wie Auryth TX das umsetzt
Auryth TX adressiert die drei Fehlermodi, die die Stanford-Studie identifiziert hat. Jede Antwort enthält Quellenangaben, die mit den spezifischen Bestimmungen, Urteilen oder Kommentaren verknüpft sind, die die Antwort stützen. Konfidenzwerte zeigen an, wie gut die abgerufenen Quellen die generierte Antwort stützen.
Wir behaupten nicht, halluzinationsfrei zu sein. Wir behaupten, transparent zu sein über das, was wir wissen, worüber wir unsicher sind und wo das professionelle Urteil des Nutzers essenziell ist.
Quellen: 1. Magesh, V. et al. (2024). „Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools.” Journal of Empirical Legal Studies, 2025. 2. Dahl, M. et al. (2024). „Large Legal Fictions: Profiling Legal Hallucinations in Large Language Models.” Journal of Legal Analysis, 16(1), 64-93. 3. Farquhar, S. et al. (2024). „Detecting hallucinations in large language models using semantic entropy.” Nature, 630, 625-630.